- 1. 什么是 namespaces
- 2. 运用namespaces构建container
- 3. 运用chroot/pivot_root改变根目录
- 4. chroot/pivot_root和namespaces 和 seccomp 的差异和关联
- 5. 附录: C/C++: namespaces API使用方法
1. 什么是 namespaces
namespaces的简介可以通过linux命令 man namespaces来了解
 总而言之,
总而言之,namespaces是linux kernel提供的用来隔离进程可用内核资源的机制。通过namespaces可以让进程只看到跟自己相关的一部分内核资源。
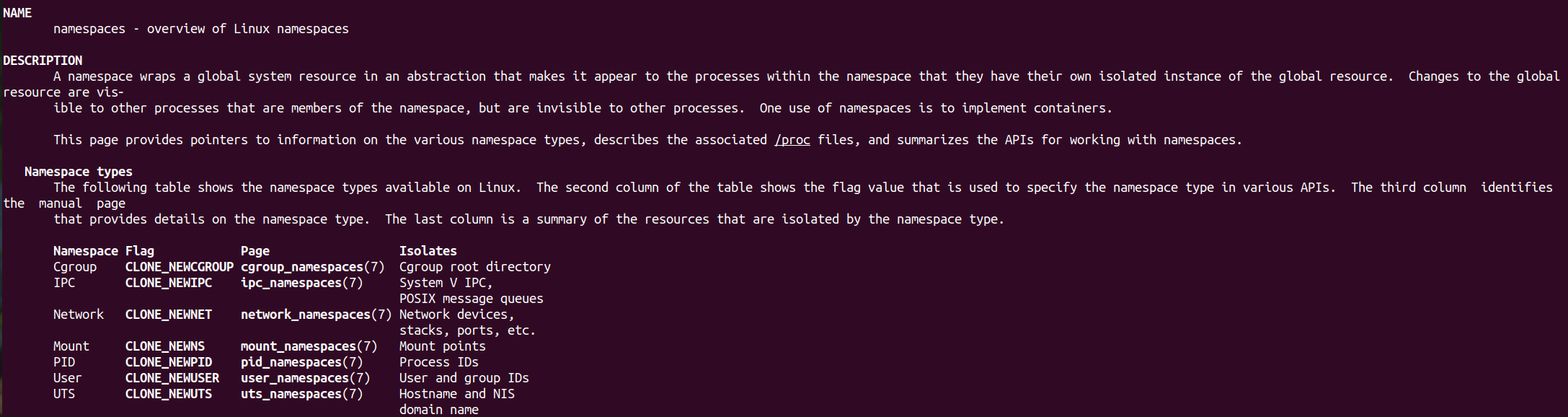
从上述的man可以得知,当前namespaces只允许隔离7种类型的linux内核资源
1. UTS:提供主机名和域名的隔离,这样一个容器就可以拥有独立的主机名和域名,能够
作为网络中的一个独立节点,而非宿主机上的进程
2. IPC: 进程间通信的三种方式:共享内存、消息队列、信号量。这让容器内无法见到宿
主机的进程间通信的状态。(可通过ipcmk -Q创建队列,ipcs -q查看队列 ipcrm -Q key删除队列)
反过来,宿主机也无法看到容器内新建的队列
3. PID: 创建独立的PID namespace,同一个进程在不同的namespace下可以有不同的pid。
另外,因为linux内核为所有的PID namespace维护了一个树状结构,树顶就是linux内
核默认创建的root namespace,我们创建的新PID namespace被成为child namespace
因此,pid namespace是有等级的,所属父节点可以看到子节点的进程,并通过发送信号
等方式影响子节点
换句话说,通常情况下容器内创建的进程,在宿主机是可以观测到并杀死的,反之不行。
此时如果ps -aux还是可以看到所有的进程,这说明隔离不完全(没有隔离/proc文件系统)
4. Mount:创建一个mount namespace,通过隔离文件系统挂载点来隔离文件系统,在
执行mount("proc","/proc","proc",0,NULL);后(对应参数的含义分别是
挂载的源为proc文件系统,挂载到/proc目录下,挂载的类型是proc)
ps -aux将无法看到其他进程的信息,退出该进程后需要sudo mount -t proc proc /proc进行复原
5. User:一个普通用户的进程通过clone()创建新的进程在新user namespace中可以拥
有不同的用户和用户组。这意味着一个进程在容器外属于一个没有特殊权限的普通用户,
但是它创建的容器进程却属于拥有所有权限的超级用户,这个技术为容器提供了极大的自由。
6. Network: 能够隔离网络设备,栈,端口,等等
7. cgroup: 能够限制被隔离的namespace中,使被隔离的namespace中的进程,对CPU
的使用率,内存使用量,磁盘IO速率,网络带宽等等进行限制!
namespaces用途广泛,我们应该如何使用呢?
2. 运用namespaces构建container
2.1 namespaces使用前提
需要有root权限,毕竟需要隔离系统资源
要想完整得运用namespaces构建容器,需要用到很多涉及linux kernel底层机制的命令,比如unshare命令和mount命令,正好总结一下这些命令背后的原理以及如何使用
## 以下命令都需要sudo权限执行
unshare: unshare linux命令允许创建一个子进程,该子进程可以拥有与父进程不同的
namespace
mount: mount命令用于将物理设备(通常是磁盘)的文件系统挂载到linux的根目录/下
,这样我们可以直接访问该设备中的内容
但是这么说其实很抽象看,举个例子:linux系统存在某个磁盘设备当中,启动linux kernel前的准备工作就不说了,到linux启动时,它会把它所在磁盘的文件系统挂载到/目录下,这样它就具备了存放数据的能力。 此后linux kernel会创建/dev目录并搜索所有可以访问的设备,并把它们抽象成设备文件放在/dev目录下。这个/dev目录下自然包括了linux本身所在的磁盘设备(/dev/sda)
2.2 运用linux cmds构建container
首先,使用sudo unshare -m bash创建一个子进程,这个子进程有跟父进程不同的mount namespace,注意,虽然此时子进程跟父进程有不同的mount namespace,但是两个mount namespace的内容是一样的(拷贝),但是此时,在子进程中执行命令mount --bind /bin/ $PWD/a命令后,就会发现不同的地方:
 可以看到,使用mount命令将已有的目录挂载到另一个目录下,但是非该namespace的程序无法看见这个内容。
可以看到,使用mount命令将已有的目录挂载到另一个目录下,但是非该namespace的程序无法看见这个内容。
注意,mount namespaces不同,但是这两个进程仍然共享同一个文件系统,下面这个例子可以举证
 我们创建了c目录,两个进程都可以看到这个目录。
我们创建了c目录,两个进程都可以看到这个目录。
但是,如果在mount过的 a目录中创建内容,情况则有所不同
 现在了解完,再来一个有趣的例子。
现在了解完,再来一个有趣的例子。
执行这个shell命令:sudo unshare -m -n -p --fork --mount-proc bash
-m 创建 mount namespace, --mount-proc就是把/proc重新挂载,不这样做 ps -aux
仍然能看到所有进程~
-n 创建 network namespace
-p 创建 pid namespace, 这个选项要跟--fork一起用,不然有神秘问题
 已经有容器的感觉了~
已经有容器的感觉了~
另外,之前提到过pid namespace的等级制度,高等级的pid namespace可以看到低级pid namespace里运行的进程.在docker里也是一样的

3. 运用chroot/pivot_root改变根目录
3.1 chroot改变/目录
sudo unshare -m -n -p --fork --mount-proc bash
mkdir bin usr lib lib64 proc
sudo mount --bind /bin ./bin
sudo mount --bind /usr ./usr/
sudo mount --bind /lib ./lib
sudo mount --bind /lib64 ./lib64
sudo mount --bind /proc ./proc
sudo chroot .
结果如下:
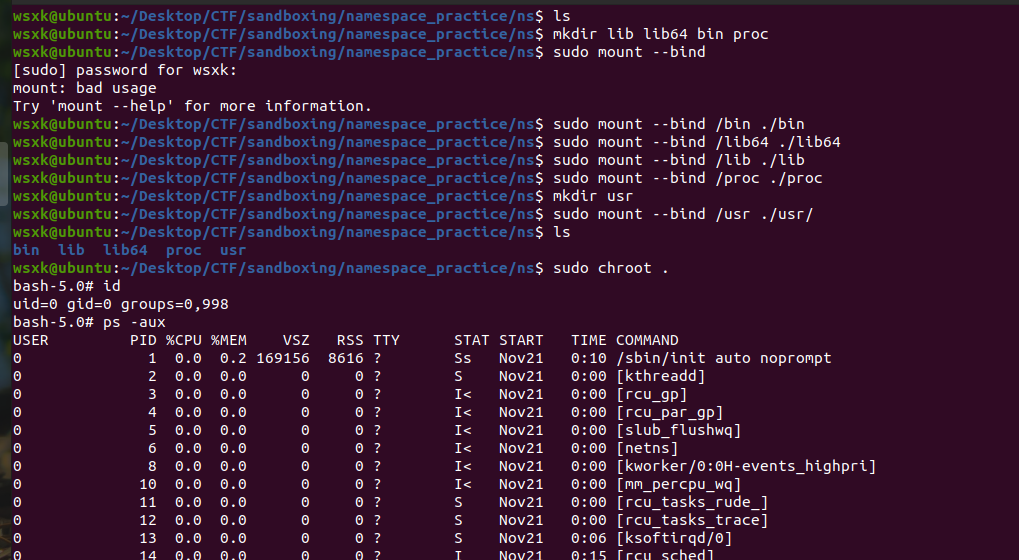 但是众所周知,chroot并不安全,不了解的可以看https://wsxk.github.io/sandboxing_namespace/
但是众所周知,chroot并不安全,不了解的可以看https://wsxk.github.io/sandboxing_namespace/
3.2 pivot_root改变根目录
chroot的作用是改变当前进程及其子进程的根目录,可以随时逃逸
但是pivot_root,它能够改变当前进程所在的mount namespaces空间中所有进程的 根文件系统挂载点
它的作用非常强力,如果说chroot是给进程带了个眼罩,pivot_root就是更换了系统的根基!
现代容器通常都使用pivot_root而不是chroot。
它的用法如下:
sudo unshare -m -n -p --fork --mount-proc bash
mkdir bin usr lib lib64 proc old_root
sudo mount --bind $PWD $PWD #必须这么做
sudo mount --bind /bin ./bin
sudo mount --bind /usr ./usr/
sudo mount --bind /lib ./lib
sudo mount --bind /lib64 ./lib64
sudo mount --bind /proc ./proc
pivot_root $PWD $PWD/old_root/ #old_root为保存原有根节点的目录
cd /
进入后,就把old_root unmounted掉!
umount -l old_root
rm -rf old_root
至此,一个容器诞生了!
 当然,还是要强调一遍,宿主机可以看到容器内的进程pid(和容器内的pid号不同),所以宿主机可以控制容器进程
当然,还是要强调一遍,宿主机可以看到容器内的进程pid(和容器内的pid号不同),所以宿主机可以控制容器进程
接下来再用seccomp限制一下系统调用(防止逃逸),一个类似docker的容器就彻底完成!
此时,要想从外部宿主机进入容器,可以使用如下命令:
nsenter --mount=/proc/6388/ns/mnt /bin/bash
## 6388为你实际运用unshare创建容器的 /bin/bash pid!
## 通过这种方式我们就能从宿主机进入容器内部!docker也是这么干的

4. chroot/pivot_root和namespaces 和 seccomp 的差异和关联
chroot/pivot_root用于改变容器中的根目录,namespace用于隔离进程可调用的系统资源,seccomp用于限制进程可以执行的系统调用;一定要说的话seccomp的优先级大于namespace,毕竟namespace的使用依赖于执行系统调用(system calls)
4.1 PS:docker的隔离原理
docker = namespace+ pivot_root + seccomp这个加法也代表了执行的先后顺序
话又说回来,即使是这么简单的思路,实践起来也很困难,不然世上也就不会仅docker一家独大了。
有的时候理解原理思路 跟 落地实践 是两码事,纸上得来终觉浅,须知此事要躬行,古人诚不欺我
要想学好网络安全,实践是必不可少的.以后还是要专注于实践。
5. 附录: C/C++: namespaces API使用方法
5.1 namespaces 系统api
需要用到的API有三个
// 创建一个新的进程的同时,创建新的namespaces,且新进程会被附加到新namespaces中
// 注意:父进程仍然在原来的namespaces中
int clone(int (*fn)(void *), void *child_stack,
int flags, void *arg, ...
/* pid_t *ptid, void *newtls, pid_t *ctid */ );
/*
fn:指的是新进程运行的函数指针
child_stack: 子进程使用的栈空间指针
flags :使用哪些CLONE_*标志位,不同标准位代表不同类型的namespaces
arg : 传入用户的参数
*/
//创建一个新的命名空间,并将当前进程附加到新的namespaces中,flags与clone的flags一致
int unshare(int flags);
//将当前进程附加到已有的namespaces中
int setns(int fd, int nstype);
/*
fd: 我们要加入的namespaces的文件描述符,通常是/proc/[pid]/ns下面的文件描述符
nstype: 让调用者检查fd指向的文件描述符是否符合实际要求,填0则不检查
*/
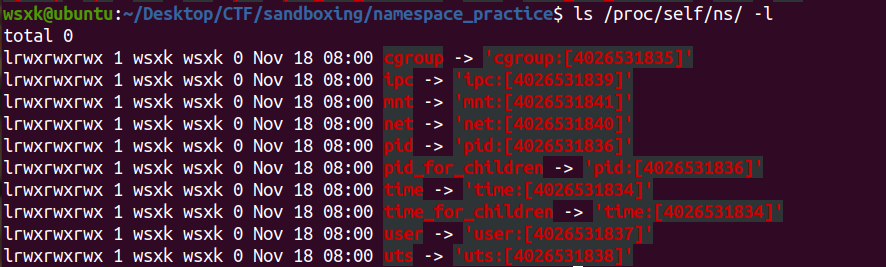
文件描述符查看的例子:
5.2 A example
可以参考https://blog.csdn.net/huchao_lingo/article/details/140448672文章,写的挺好的,yysy
里面还有针对namespace各个参数的案例代码,可以运行感受一下
举个例子:
#define _GNU_SOURCE
#include <sys/types.h>
#include <sys/wait.h>
#include <stdio.h>
#include <sched.h>
#include <signal.h>
#include <unistd.h>
#define STACK_SIZE (1024*1024)
static char child_stack[STACK_SIZE];
char* const child_args[] = {
"/bin/bash",
NULL
};
int child_main(void* args){
printf("in child process!\n");
sethostname("changed namespace", 12);
execv(child_args[0], child_args);
return 1;
}
int main(){
printf("program begin: \n");
int child_pid = clone(child_main, child_stack + STACK_SIZE, SIGCHLD|CLONE_NEWUTS, NULL);
waitpid(child_pid, NULL, 0);
printf("quit\n");
return 0;
}
