前言
这篇文章其实是记录论文RetroWrite: Statically Instrumenting COTS Binaries for Fuzzing and Sanitization的内容(真·顶会论文),very牛逼
论文作者提出了一个开源框架retrowrite,在https://github.com/HexHive/retrowrite可以找到他的代码
 可以看到有500+star,60+fork,起码还是有不少人尝试使用过了(吐槽某个神秘uSBS
可以看到有500+star,60+fork,起码还是有不少人尝试使用过了(吐槽某个神秘uSBS
在这篇论文中,作者首先对当前的二进制重写工具进行了一系列评估,并认为它们的效率太差了。于是提出了一个新的二进制重写思路,并使用这个思路写出了新的开源二进制框架,并表示:我的开源框架很猛,效率比当前的其他框架,效率能加个好几倍!
retrowrite overview
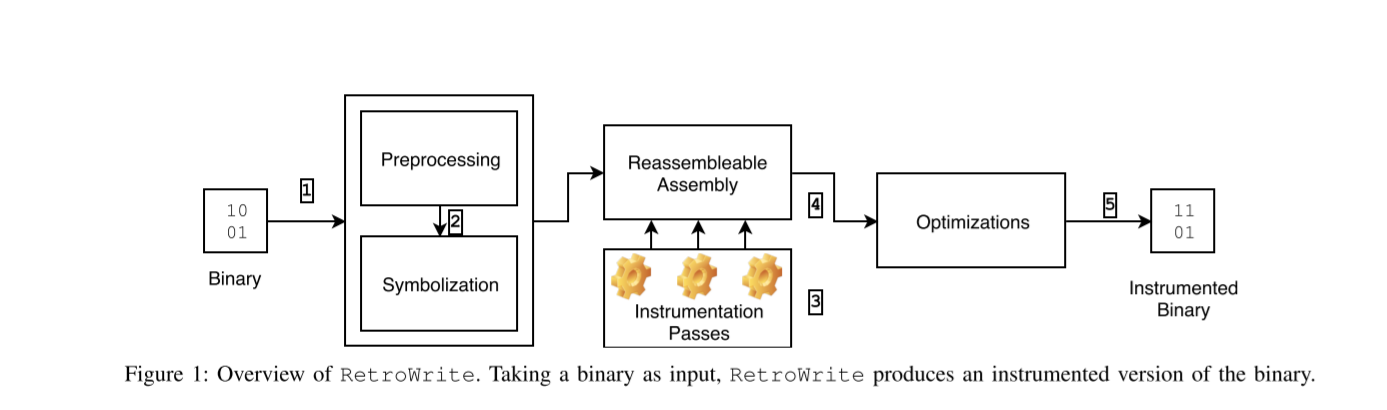 这个工具的工作流程被总结成了5步。
这个工具的工作流程被总结成了5步。
即1.Processing 2.Symbolization 3.Instrumentation Passes 4.Instrumentation Optimization 5.Reassembly
1. Processing
Preprocessing步骤,在这个阶段,该框架做了如下几件事: 预处理。第一步是加载重新组装所需的二进制部分,即文本和数据部分。RetroWrite还加载辅助信息,例如二进制文件中的符号和重定位信息。该步骤还包括使用线性扫描进行分解,并恢复尽力而为控制流图(CFG):识别并添加用于直接控制流传输的边。RetroWrite不需要重量级分析来推断间接控制流目标,从而限制分析时间并扩展到更大的二进制文件。
2. Symbolization
Symbolization步骤,符号化是RetroWrite重写过程的核心。RetroWrite使用加载阶段的重新定位信息和恢复的控制流图来识别数据和代码部分中的可符号化常量,并将其转换为汇编程序标签。RetroWrite在该步骤结束时输出可重新组装的汇编文件。可重新组装的组件可以通过RetroWrite中开发的其他工具或仪器通道进行进一步处理利用。再具体而言,符号化的操作经过了3个步骤
一、控制流符号化:控制流指令(即调用和跳转)的操作数被转换为汇编器标签,从而实现代码到代码的引用。
二、PC(程序计数器)相对寻址:由于位置无关代码不能引用固定地址,因此引用是相对于程序计数器(在x86-64上是rip)计算的。调整计算PC相对地址的指令的操作数,使其使用汇编器标签。然后,在指令引用的位置(静态计算)处定义相应的汇编器标签。这些标签包括代码到代码和代码到数据的引用。通过在获取地址的点符号化函数引用,这种方法隐式地涵盖了间接跳转和调用的情况,从而具体化了(到目前为止不精确的)控制流图(CFG)。
三、数据重定位:最后,处理数据引用。实质上是模拟动态链接器加载器执行重定位:在重定位条目指向的偏移处,我们用汇编器标签替换字节。然后,根据重定位所指向的地址(具体公式取决于重定位类型)定义相应的标签。这个过程处理了数据到数据和数据到代码的引用。

3. Instrumentation Passes
Instrumentation Passes步骤,通过对可重新组装的汇编代码进行相应操作来对目标二进制文件进行插桩和修改。rewrowrite的API既灵活又富有表现力,可以在二进制代码上执行重量级转换。
4. Instrumentation Optimization
Instrumentation Optimization步骤,retroWrite分析插桩后的代码以确定所需的寄存器数量和副作用。然后,这些分析的结果用于在每个插桩站点之前(和之后)选择性地保存(和恢复)状态变化,例如条件标志,以及为插桩实现分配寄存器。
5. Reassembly(ASM)
Reassembly步骤,这步骤就是将修改后的汇编文件借助现代编译器(例如gcc,clang)重新编译为可执行文件。
通过论文的分析,我们也可以得知x64架构下的retrowrite的使用前提是被分析的二进制程序需要是保留符号,且必须是位置无关代码(PIE)。
思路优点
一、不需要将汇编代码再提升一个层次到IR中,(通常这种做法很耗时,而且容易出错
二、轻量,而且可以直接在 现有的反汇编器生成的反汇编代码中 进行操作。
三、利用relocation、PC-relative addressing以及恢复的控制流,来确定代码中的指针信息
四、因为不是使用启发式算法,因此没用误报和漏报,说明这个框架是通用的,应用范围很广。
retrowrite框架实现方法
用capstone实现反汇编,用pyelftools加载elf文件信息并处理重定向信息。
在symbolization步骤中,生成可重新汇编的汇编代码。
为了能够安全的instrumentation插桩(即插入之后不影响程序的正常功能运行,有3个问题需要解决):
(i) a logical abstraction for analysis and instrumentation passes to operate on, e.g., modules, functions, or basic block level granularity (即需要一些函数的相关信息等等)。 对此,解决办法是获得函数的名称等等,对于stripped后的二进制文件,可以采用现有的工具(比如ida)对函数名称进行还原.
(ii) working around the ABI to ensure the instrumentation does not break the binary(围绕应用程序二进制接口进行工作,避免损坏二进制文件)。为此,需要在汇编层面根据函数的调用约定,传参,返回值,隐式规则等等进行匹配
(iii) automatic register allocation to achieve compiler-like overhead.(自动进行寄存器的申请,以达到跟编译器一样的开销)其实最安全的方法是将所有寄存器被使用前都保存下来,但一来需要空间,二来耗时;对此使用intra-function liveness analysis来找到在进行调用时有用的寄存器,将它们的值存储下来(必须是sound的方法,保证所有活寄存器可以被保留。
和Asan的联合使用
原话是这样的Our goal is to implement a binary version of ASan in RetroWrite that closely resembles and integrates seamlessly with the source-based sanitizer..
design
论文作者认为,将asan应用到二进制文件上的主要问题在于没有变量、类型、缓冲区长度的信息,虽然静态分析可以缓解这些问题,但是实用,无法大规模使用,因此作了折中。
下图可以看出ASan和二进制级别的Asan-retrowrite的区别。
 对于栈,只对栈帧进行检测
对于栈,只对栈帧进行检测
 并且,并不是对所有的函数的栈帧加入
并且,并不是对所有的函数的栈帧加入redzone,而是找到加入canary的函数加入redzone,并将原本canary的空间留作redzone。
在函数返回时,unpoison相应区域,对于longjmp的指令
不对global变量进行修改(可以看原文,还是存在问题的)
implement


和AFL的联合使用
因为retrowrite得到的汇编代码和compiler的类似,而AFL的插桩是直接基于汇编代码进行的。因此可以直接使用afl-gcc 生成二进制文件,链接动态库等等。
retrowrite源码分析
开始分析retrowrite的源码
它的源码因为支持x64和aarch64位的,看起来会比较抽象,因此我把它主要运行代码关于x64的源码扣了出来,方便观看
main function
import argparse
import json
import tempfile
import subprocess
import os
import sys
import traceback
import importlib
from elftools.elf.elffile import ELFFile
from librw_arm64.util.logging import info
from librw_x64.rw import Rewriter
from librw_x64.analysis.register import RegisterAnalysis
from librw_x64.analysis.stackframe import StackFrameAnalysis
from rwtools_x64.asan.instrument import Instrument
from librw_x64.loader import Loader
from librw_x64.analysis import register
bin = "./heap"
outfile = "heap.s"
arch = "x64"
cache = 1
args = ""
Rewriter.detailed_disasm = True
def load_analysis_cache(loader, outfile):
with open(outfile + ".analysis_cache") as fd:
analysis = json.load(fd)
print("[*] Loading analysis cache")
for func, info in analysis.items():
for key, finfo in info.items():
loader.container.functions[int(func)].analysis[key] = dict()
for k, v in finfo.items():
try:
addr = int(k)
except ValueError:
addr = k
loader.container.functions[int(func)].analysis[key][addr] = v
def save_analysis_cache(loader, outfile):
analysis = dict()
for addr, func in loader.container.functions.items():
analysis[addr] = dict()
analysis[addr]["free_registers"] = dict()
for k, info in func.analysis["free_registers"].items():
analysis[addr]["free_registers"][k] = list(info)
with open(outfile + ".analysis_cache", "w") as fd:
json.dump(analysis, fd)
def analyze_registers(loader):
StackFrameAnalysis.analyze(loader.container)
if cache:
try:
load_analysis_cache(loader, outfile)
except IOError:
RegisterAnalysis.analyze(loader.container)
save_analysis_cache(loader, outfile)
else:
RegisterAnalysis.analyze(loader.container)
def asan(rw, loader):
analyze_registers(loader)
instrumenter = Instrument(rw)
instrumenter.do_instrument()
instrumenter.dump_stats()
# load binary
loader = Loader("./heap")
if arch == "x64" and loader.is_pie() == False :
print("***** The x64 version of RetroWrite requires a position-independent executable. *****")
print("It looks like %s is not position independent" % bin)
print("If you really want to continue, because you think retrowrite has made a mistake, pass --ignore-no-pie.")
sys.exit(1)
if arch == "x64" and loader.is_stripped() == True:
print("The x64 version of RetroWrite requires a non-stripped executable.")
print("It looks like %s is stripped" % bin)
print("If you really want to continue, because you think retrowrite has made a mistake, pass --ignore-stripped.")
sys.exit(1)
# get sections info
slist = loader.slist_from_symtab() #get all section baseinfo
if not ".gcc_except_table" in slist:
# if there are no exceptions, we never emulate calls
Rewriter.emulate_calls = False
loader.identify_imports()
flist = loader.flist_from_symtab() # before loading data sections: get systable baseinfo
loader.load_functions(flist)
loader.load_data_sections(slist, lambda x: x in Rewriter.DATASECTIONS)
reloc_list = loader.reloc_list_from_symtab()
loader.load_relocations(reloc_list)
global_list = loader.global_data_list_from_symtab()
loader.load_globals_from_glist(global_list)
loader.container.attach_loader(loader)
# symbolize
rw = Rewriter(loader.container, "heap.s")
rw.symbolize()
asan(rw, loader) # address sanitizer
rw.dump()
单看主代码还是比较简洁的
实际上也符合论文描述。
首先加载二进制程序,并做一些处理,然后符号化,最后插桩。
至于为什么缺少了重新汇编的功能,因为它重新汇编需要依赖本地的编译环境
之后会着重看一下其中几个类型的实现,然后继续补充