前言
话说回来,其实直觉上来说,对于一个大模型而言,参数越多,数据集越多,效果往往越好,如下图所示
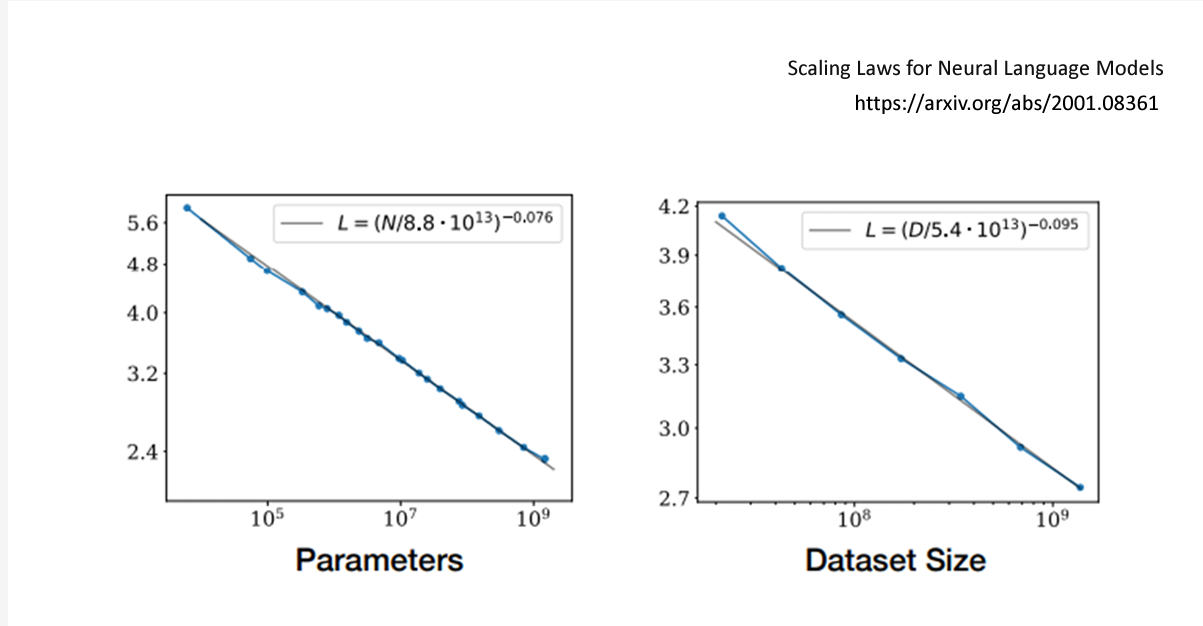 参数越多,数据集大小越大,Loss越少,模型功能越好
参数越多,数据集大小越大,Loss越少,模型功能越好
然而,有人好奇,参数大小和数据集大小应该使用多少比较合适呢?
1. Parameters
后来人们发现,大模型是有顿悟时刻Emergent Ability的,在保证数据量不变的情况下,参数达到一定水准后,大模型突然就变强了
然而具体在哪个点变强,是不确定的,这给开发大模型带来了一些困难,即在一开始性能不强,或者增长不明显的时候,难以说服投资人继续砸钱开发大模型
然而,会发生这样的情况是有理由的,下图可以比较清晰的解释为什么大模型在某一时刻效果达到max
下面一张图更直观地展示了问题
 在这种情形下,中模型甚至表现的还不如小模型(随便乱猜)
在这种情形下,中模型甚至表现的还不如小模型(随便乱猜)
这告诉我们,应该对模型的评价标准进行更细粒度得划分。
2. DataSet
下面一张图可以直观表现出数据集大小的重要性
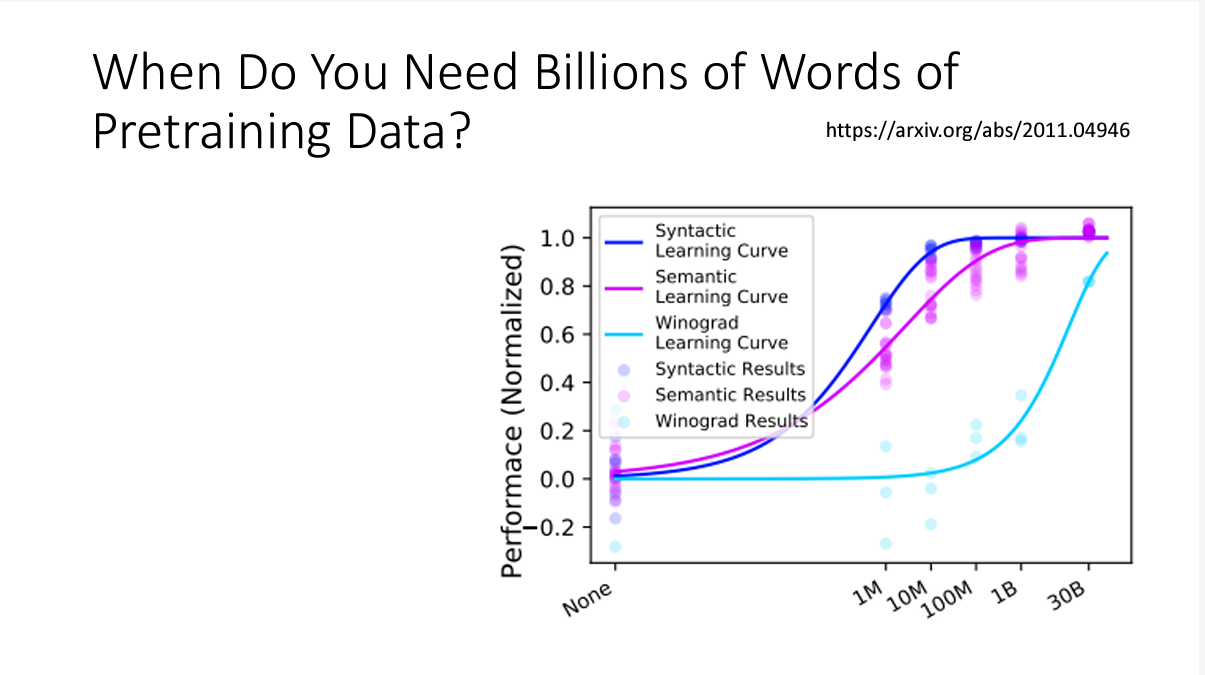
在数据集达到一定程度,模型不仅知道了语言的语法规则,还能掌握一些物理知识
下图是一张对数据集进行裁剪的流程图
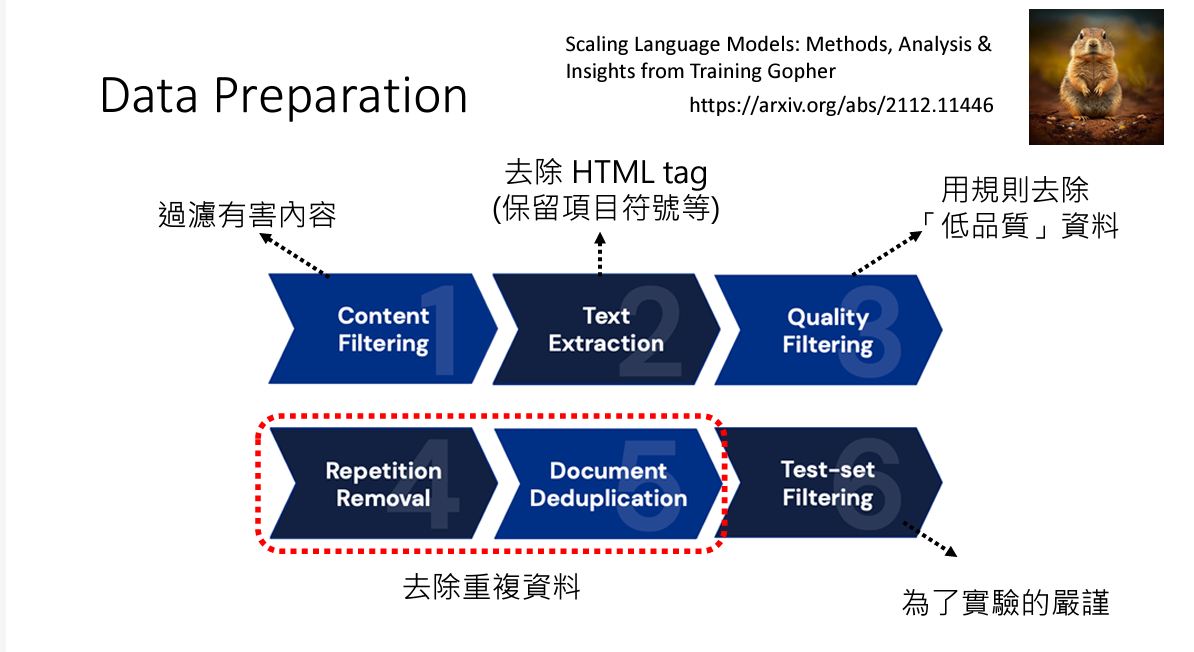 实验表明,一个良好的数据集也有助于帮助模型学习,如果一个数据集杂质较多,不利于模型的学习
实验表明,一个良好的数据集也有助于帮助模型学习,如果一个数据集杂质较多,不利于模型的学习

3. Parameter/DataSet setting
在资源有限的情况下,如何设置模型大小和数据集数量,以便模型能达到最好的效果呢?
在经过各种实验后,得到结论
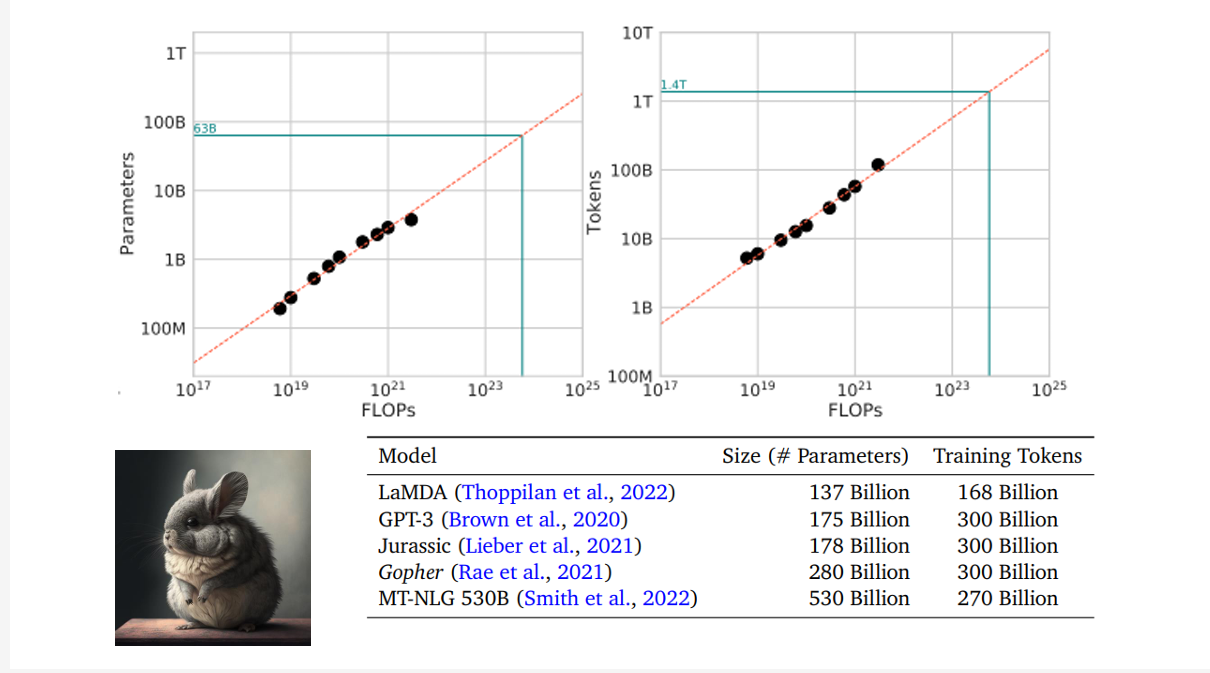
这种设置和现在的大模型相去甚远
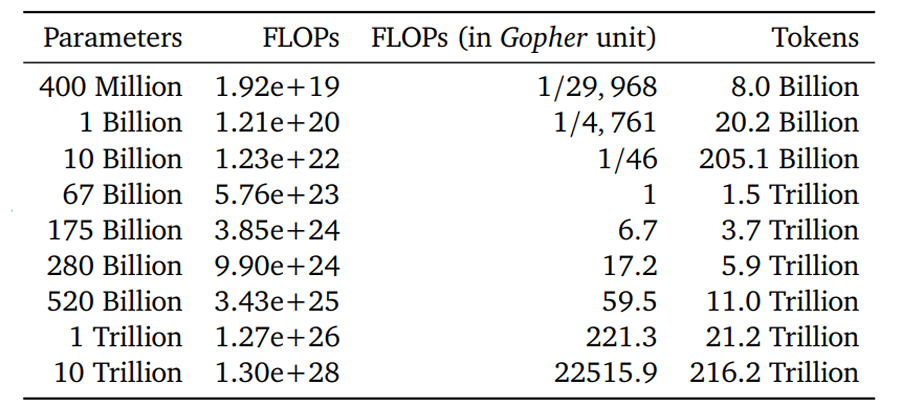
到底哪个比较好呢,又有实验表明,还是下图中数据比较合理
4. Other Optimization
还有一些常用的优化方法,比如先前提到的In-context learning、Instruction tuning、Human Teaching(supervised learning)、RL(Reinforcement learning)等等,可以在占用资源较少(相比于训练大模型而言)的情况下,获得比较好的提升
5. KNN LM
KNN是另一种大模型的训练方法,它的做法如下图所示
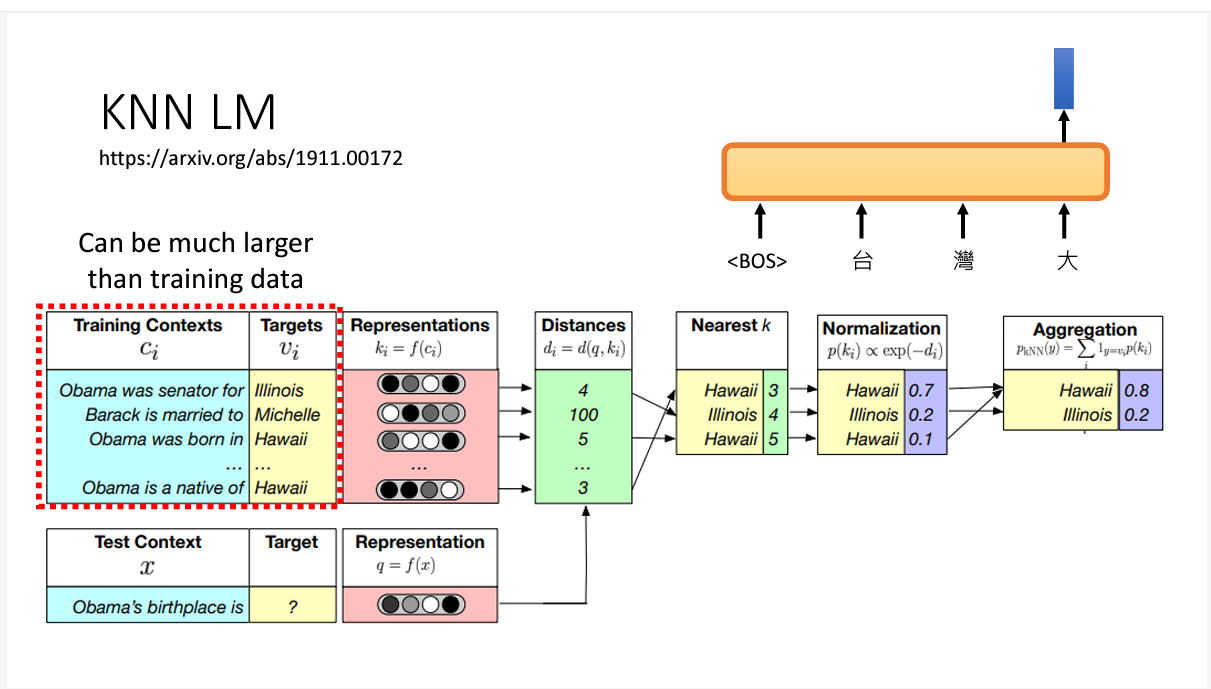 其实它训练的方法也很神奇啊,模型训练好后,它预测方法是,将训练数据中每个前缀后跟着的token和测试集计算距离,算出最近的那一个距离,得到结果。
其实它训练的方法也很神奇啊,模型训练好后,它预测方法是,将训练数据中每个前缀后跟着的token和测试集计算距离,算出最近的那一个距离,得到结果。
这个训练方法的好处是,计算距离的数据可以比训练集大得多,坏处是,很慢(事实上chatgpt就不是用这个方法,你也知道了)