前言
ACTF2026出了一道npu的逆向题目,随着显卡的重要性大幅提高,npu相关架构的题目一定会出现,了解nvidia cuda的架构就变得比较重要
1. cuda toolkit
https://wsxk.github.io/AI_env/
之前已经安装过一次了。
cuda编程和传统编程不一致,主要原因是需要同时编写host测(cpu)和slave侧(npu)执行的代码。
https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html
1.1 cuda应用程序简介
1. CUDA 应用程序的源文件混合了传统的 C++ 主机代码和 GPU 设备函数。
2. CUDA 将设备函数与主机代码分开编译,使用专有的 NVIDIA 编译器和汇编器编译设备函数,使用可用的 C++ 主机编译器编译主机代码,然后将编译后的 GPU 函数作为 fatbinary 嵌入到宿主对象文件中。
3. 在链接阶段,添加特定的 CUDA 运行时库以支持远程 SPMD(多数据) 过程调用和提供显式 GPU 操作,例如分配 GPU 内存缓冲区和主机-GPU数据传输。
cuda的文件如下所示:
cuda的源代码一般是`.cu`,通过前端生成中间语言`.ptx`,最后编译为`.cubin`,也是elf格式的文件,`.fatbin`不是一种单独的指令格式,而是fat binary container,里面可以同时包含多份 PTX 和多份 CUBIN。
(NVIDIA说明,fatbin的目的就是把同一份CUDA 代码的多个变体放到一个 CUDA fat binary 里,以便为不同架构动态加载最合适的版本。)
.cu 源码
↓ nvcc 前端
.ptx // 中间表示,类似 GPU 汇编/虚拟 ISA
↓ ptxas
.cubin // 针对具体 GPU 架构的机器码
↓ 打包
.fatbin // 容器,里面可以同时放多个 .cubin 和 .ptx

1.2 cuda编译过程
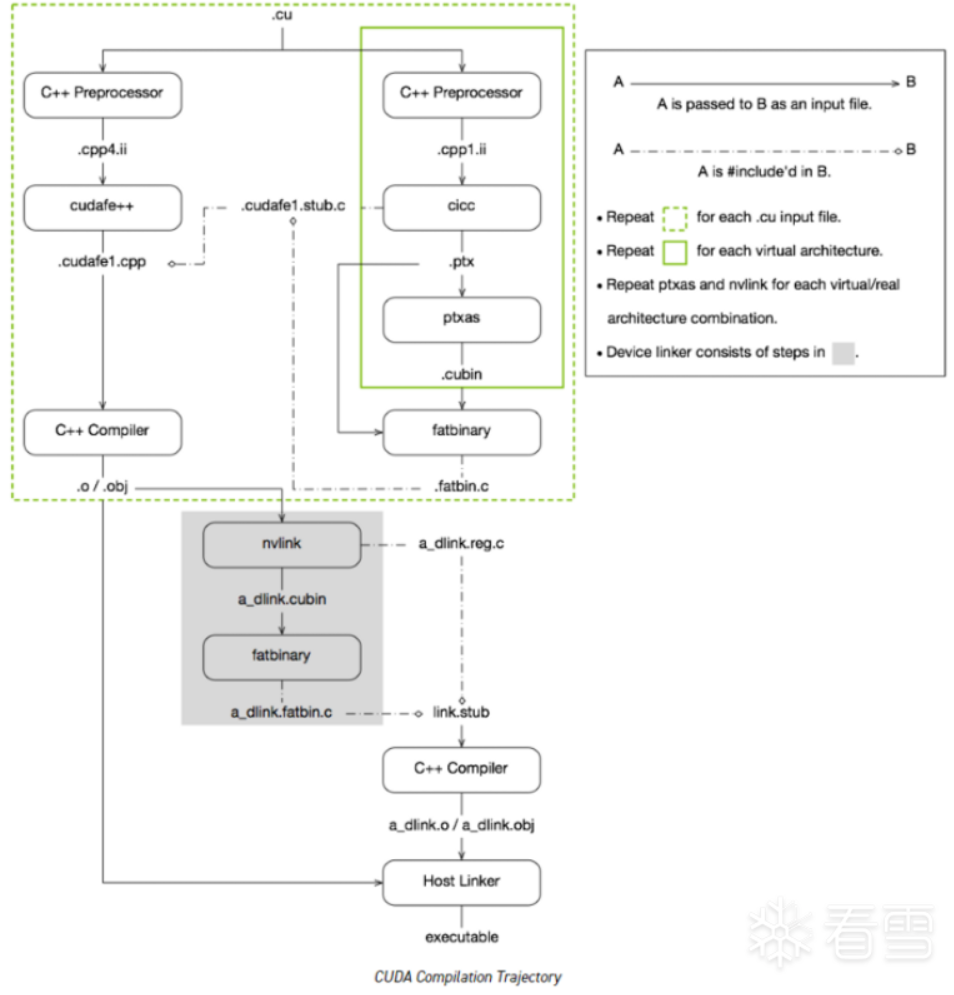
2. cuda编译代码例子
如下所示:
// Kernel definition
// Run on GPU
// Adding 2 numbers and store the result in c
__global__ void add(int *a, int *b, int *c)
{
*c = *a + *b;
}
int main(void) {
// Allocate & initialize host data - run on the host
int a, b, c; // host copies of a, b, c
a = 2;
b = 7;
int *d_a, *d_b, *d_c; // device copies of a, b, c
// Allocate space for device copies of a, b, c
cudaMalloc((void **)&d_a, size);
cudaMalloc((void **)&d_b, size);
cudaMalloc((void **)&d_c, size);
// Copy a & b from the host to the device
cudaMemcpy(d_a, &a, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_b, &b, size, cudaMemcpyHostToDevice);
// Launch add() kernel on GPU with parameters (d_a, d_b, d_c)
add<<<1,1>>>(d_a, d_b, d_c);
// Copy result back to the host
cudaMemcpy(&c, d_c, size, cudaMemcpyDeviceToHost);
// Cleanup
cudaFree(d_a); cudaFree(d_b); cudaFree(d_c);
}
3. todo
ptx、cubin、fatbinary逆向