更新于2022-10-26
seq_file
seq_file最初是为了方便内核调试(传递信息到用户态便于查看)而创建的数据结构。
当时为了能够将调试信息导入到sysfs,debugfs,procfs,工作人员使用了许多不同的实现,但是都无法避免的产生一些漏洞。
因此,为了规范标准和便于维护,一些内核hacker依靠自己的经验和总结,实现了一套统一的接口,即seq_file
seq_file的使用过程如下(需要有一定的驱动编程基础,没有基础的同学可以自行百度)
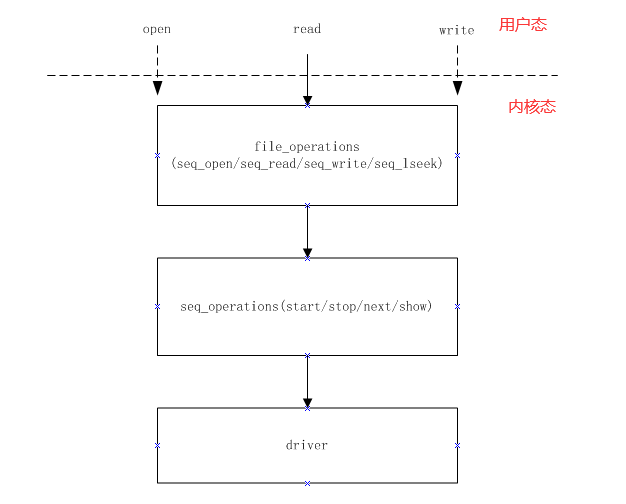
seq_file相关结构定义
seq_file结构定义在include/linux/seq_file.h中,结构如下:
struct seq_file{
char * buf;//seq_file接口使用的缓存页指针
size_t size;//seq_file接口使用的缓存页大小
size_t from;//从seq_file中向用户态缓冲区拷贝时相对于buf的偏移地址
size_t count;//buf中可以拷贝到用户态的字符数
loff_t index;//start()、next()的处理的下标pos值
loff_t read_pos;//当前已拷贝到用户态的数据量大小
u64 version;
struct mutex lock;//互斥锁,同步相关
const struct seq_operations *op;//需要自己实现的操作底层函数
void * private;
}
struct seq_operations{//自定义的函数
void *(*start)(struct seq_file * m,loff_t *pos);//首先被调用的函数,设置访问起点,pos不是字节,而是自定义的单位
void (*stop)(struct seq_file *m,void *v);//结束,通常直接返回就行,如果需要做退出处理就在这里编写代码
void *(*next)(struct seq_file *m,void *v,loff_t *pos);//移动到下一个数据元素
int (*show)(struct seq_file *m,void *v);//将v指向的元素的数据拷贝到seq_file的内部缓存buf中
}
seq_file相关API
int seq_open(struct file*file,const struct seq_operations *op);//将seq_operations赋值给file结构体。
int seq_release(struct inode *inode,struct file *file);
ssize_t seq_read(struct file * file,char __user *buf,size_t size,loff_t *ppos);
int seq_write(struct seq_file *seq,const void * date,size_t len);
loff_t seq_lseek(struct file *file,loff_t offset,int whence);
seq_read执行流程
seq_read是最为重要的一个函数,它负责从内部buffer缓冲区中读取数据并调用copy_to_user 返回给应用层。阅读代码会发现该函数实现如下操作:
- 创建一个buffer(通常情况默认是 1个page的大小)
- 调用seq_operation中的 start函数
- 调用seq_operation中的show函数
- 调用seq_operation中的next函数
- 判断buffer大小是否足够,不够需要释放buffer,然后创建一个更大的buffer(通常情况是*2)
- 循环上述步骤直到不用写入且buffer没有溢出
- 将buffer内容调用
copy_to_userf返回给用户态
可以看一下seq_read源码:(linux 6.0.3版本 fs/seq_file.c)
ssize_t seq_read(struct file *file, char __user *buf, size_t size, loff_t *ppos)
{
struct iovec iov = { .iov_base = buf, .iov_len = size};
struct kiocb kiocb;
struct iov_iter iter;
ssize_t ret;
init_sync_kiocb(&kiocb, file);
iov_iter_init(&iter, READ, &iov, 1, size);
kiocb.ki_pos = *ppos;
ret = seq_read_iter(&kiocb, &iter);
*ppos = kiocb.ki_pos;
return ret;
}
ssize_t seq_read_iter(struct kiocb *iocb, struct iov_iter *iter)
{
struct seq_file *m = iocb->ki_filp->private_data;
size_t copied = 0;
size_t n;
void *p;
int err = 0;
if (!iov_iter_count(iter))
return 0;
mutex_lock(&m->lock);
/*
* if request is to read from zero offset, reset iterator to first
* record as it might have been already advanced by previous requests
*/
if (iocb->ki_pos == 0) {
m->index = 0;
m->count = 0;
}
/* Don't assume ki_pos is where we left it */
if (unlikely(iocb->ki_pos != m->read_pos)) {
while ((err = traverse(m, iocb->ki_pos)) == -EAGAIN)
;
if (err) {
/* With prejudice... */
m->read_pos = 0;
m->index = 0;
m->count = 0;
goto Done;
} else {
m->read_pos = iocb->ki_pos;
}
}
/* grab buffer if we didn't have one */
if (!m->buf) {
m->buf = seq_buf_alloc(m->size = PAGE_SIZE);
if (!m->buf)
goto Enomem;
}
// something left in the buffer - copy it out first
if (m->count) {
n = copy_to_iter(m->buf + m->from, m->count, iter);
m->count -= n;
m->from += n;
copied += n;
if (m->count) // hadn't managed to copy everything
goto Done;
}
// get a non-empty record in the buffer
m->from = 0;
p = m->op->start(m, &m->index);
while (1) {
err = PTR_ERR(p);
if (!p || IS_ERR(p)) // EOF or an error
break;
err = m->op->show(m, p);
if (err < 0) // hard error
break;
if (unlikely(err)) // ->show() says "skip it"
m->count = 0;
if (unlikely(!m->count)) { // empty record
p = m->op->next(m, p, &m->index);
continue;
}
if (!seq_has_overflowed(m)) // got it
goto Fill;
// need a bigger buffer
m->op->stop(m, p);
kvfree(m->buf);
m->count = 0;
m->buf = seq_buf_alloc(m->size <<= 1);
if (!m->buf)
goto Enomem;
p = m->op->start(m, &m->index);
}
// EOF or an error
m->op->stop(m, p);
m->count = 0;
goto Done;
Fill:
// one non-empty record is in the buffer; if they want more,
// try to fit more in, but in any case we need to advance
// the iterator once for every record shown.
while (1) {
size_t offs = m->count;
loff_t pos = m->index;
p = m->op->next(m, p, &m->index);
if (pos == m->index) {
pr_info_ratelimited("buggy .next function %ps did not update position index\n",
m->op->next);
m->index++;
}
if (!p || IS_ERR(p)) // no next record for us
break;
if (m->count >= iov_iter_count(iter))
break;
err = m->op->show(m, p);
if (err > 0) { // ->show() says "skip it"
m->count = offs;
} else if (err || seq_has_overflowed(m)) {
m->count = offs;
break;
}
}
m->op->stop(m, p);
n = copy_to_iter(m->buf, m->count, iter);
copied += n;
m->count -= n;
m->from = n;
Done:
if (unlikely(!copied)) {
copied = m->count ? -EFAULT : err;
} else {
iocb->ki_pos += copied;
m->read_pos += copied;
}
mutex_unlock(&m->lock);
return copied;
Enomem:
err = -ENOMEM;
goto Done;
}
seq_write执行流程
关于seq_write函数,其实它和seq_read并不对称。
seq_write只把内核的消息拷贝到seq_file的buffer当中,并不涉及用户态向内核态传送内容(seq_file系列本来就是只读的)
通常在show()函数中会调用seq_write函数来往buffer写入内容.
seq_file编写实例
(1)注册的实例代码
proc_test_entry = create_proc_entry("proc_seq",0644,NULL);
if(proc_test_entry == NULL){
ret = -ENOMEM;
cleanup_test_data();
}else{
proc_test_entry->proc_fops = &proc_ops;//这里把实现的file_operations进行赋值
}
(2)实现struct file_operations proc_ops的定义
static struct file_operations proc_ops = {
.owner = THIS_MODULE,
.open = proc_seq_open,//通常情况下 open函数是需要自己编写的,也很简单,后面会给出实例
.read = seq_read,//以下3个函数都使用seq_file自带的api接口即可
.llseek = seq_lseek,
.release = seq_release,
}
open函数实现也很简单
static int proc_seq_open(struct inode 8 inode,struct file * file){
return seq_open(file,&proc_seq_ops);//proc_seq_ops是需要自己实现的seq_operations结构体。
}
(3)实现seq_operations结构体
static struct seq_operations proc_seq_ops = {
.start = proc_seq_start,
.next = proc_seq_next,
.stop = proc_seq_stop,
.show = proc_seq_show
};
这些回调函数需要自己编写。实际编写过程中,当然是需要反着写的,但是在讲解时这样写比较容易理清思路。
PS1:single_open
single_open是对seq_file相关操作进行了进一步封装,简化了操作步骤,使得我们不需要编写完整的seq_operations,只需要编写show函数即可。
int single_open(struct file *file, int (*show)(struct seq_file *, void *),
void *data)
{
struct seq_operations *op = kmalloc(sizeof(*op), GFP_KERNEL_ACCOUNT);
int res = -ENOMEM;
if (op) {
op->start = single_start;
op->next = single_next;
op->stop = single_stop;
op->show = show;
res = seq_open(file, op);
if (!res)
((struct seq_file *)file->private_data)->private = data;
else
kfree(op);
}
return res;
}
在使用时只需要修改上述实例的步骤2,步骤3简化为只编写show函数。
PS2:创建proc文件的三种方法
create_proc_entry //方法一 创建简单,但危险(有缓冲区溢出风险,已经不推荐使用了)
proc_create + seq_file//方法二
proc_create_data + seq_file //方法三
重点讲解这3个方式的区别
create_proc_entry 在没有添加文件操作时,会使用一个创建一个默认的文件操作。
proc_create 必须提供自己定义的文件操作函数(没有默认
proc_create_data其实是proc_create的底层调用(你也可以自己调用)
references
内核proc文件系统与seq接口
内核seq_file操作函数
用户与内核空间数据交换的方法之一seq_file
ubuntu/linux mint 创建proc文件的三种方法(四)
proc_create和create_proc_entry的区别