PS:kernel,我又回来啦
0. 写在前面
其实大三有一段时间是在学习kernel pwn的,后来很长一段时间不用又忘记了,如今重拾kernel,希望能更系统的学习。
大三的学习记录在https://wsxk.github.io/linux_kernel_basic_one/
事到如今,不过是再学一遍罢了~
1. 内核简介
1.1 什么是操作系统内核
操作系统(Operation System) 本质上也是一种软件,可以看作是普通应用程式与硬件之间的一层中间层,其主要作用便是调度系统资源、控制IO设备、操作网络与文件系统等,并为上层应用提供便捷、抽象的应用接口而 内核(kernel) 是操作系统最重要的一部分。
1.2 内核专享的外部资源
内核专享的外部资源(external resources),指只有内核才能访问的资源,即用户态无法直接访问其资源。
这里引出用户态和内核态的概念:用户态就是我们的进程执行的代码空间,内核态指内核执行的代码空间。
也就是说,用户态的程序想要访问一些外部资源,需要先陷进内核态,通常这个动作是通过系统调用完成(还有其他,接下来再举例)
一些常见的外部资源如下:
1. hlt指令:只在内核态才允许执行该指令
其作用是让 CPU 进入 halt(空闲/省电)状态,停止取指与执行,直到被“唤醒事件”打断。常用于内核的 idle 循环。(idle即空闲状态)
2. in 和 out指令:用于访问I/O端口空间的设备寄存器。其实就是和硬件外设交互,常用于老式设备
(现代的pcie将设备寄存器暴露为某个物理/虚拟地址范围,用普通 mov 读写(再配合内存屏障))
3. 一些特殊寄存器:
cr3:(control register 3) ,它是指向page table的指针,用于虚拟地址和物理地址之间的转换,通常用mov指令就可以修改值,但是必须要是内核态。
MSR_LSTAR (Model-Specific Register, Long Syscall Target Address Register): 它定义了syscall指令应该跳往哪个函数。 通常用wrmsr和rdmsr来读写这个寄存器
1.3 privilege level
CPU通过跟踪权限等级来控制资源的访问,权限等级的图如下:
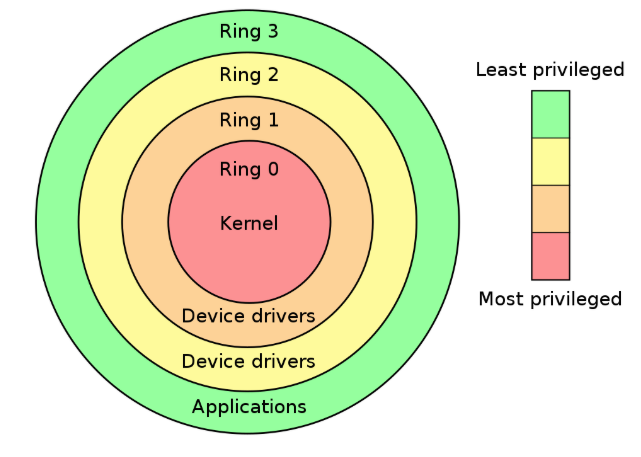
Ring 3: Userspace, where we have been operating until now. Very restricted.
Ring 2: Generally unused.
Ring 1: Generally unused.
Ring 0: The Kernel. Unrestricted, supervisor mode.
可以看到虽然划分了4个层级,其实只有2个层级被使用到:ring3和ring0
然而随着VM(virtual machine)技术的兴起,虚拟机内核不能和主机os内核有一样的权限,在古早时期(21世纪初),虚拟机内核被放入ring 1中,这导致了严重的性能开销,运行在虚拟机中的进程,如果想要执行 主机os配合才能完成的操作时,需要从ring3->ring1->ring0,在ring1上模拟ring0操作(或者可以说ring1陷入ring0态)带来额外开销
为了减少开销,现代引入了ring-1级别(即hypervisor),它比ring0更高,因此当虚拟机os(guest os)产生了需要ring0的操作时,hypervisor会拦截到该操作,并把任务下发给在主机os,由其执行
看起来拦截并转给主机os执行想比模拟ring0,性能开销小得多。
1.4 不同类型的os模型
笼统的说,os的类型有三种:
monolithic kernel:宏内核,是一个单一的,统一的内核二进制文件,处理所以的操作系统层级的任务,驱动也会作为内核的一部分被加载到二进制文件中(这意味着驱动和内核都处于ring0,即 驱动即内核,驱动有问题=内核有问题)
- examples: Linux, FreeBSD
microkernel:微内核,理论上完美的内核(实际上要处理的消息太多了),由一个微小的"core"二进制文件提供进程间通信和与硬件基本交互,驱动程序是具有轻微特权的普通用户空间程序。
- examples: Minux, seL4
hybrid kernel:混合内核,微内核的特效与宏内核组件相结合
- examples: Windows (NT), MacOS
1.5 ring间的切换
通常情况下,ring间切换指的是 ring3<->ring0之间的状态转换。
x86/x86-64(以 Linux 为例),ring3<->ring0的切换的本质是CPU 触发特权门(IDT/GDT/MSR),把 CPL=3 切到 CPL=0,状态转换的方法如下所示:
| methods | Description |
|---|---|
| 同步异常: 错误(faults)/陷阱(traps) faults & traps → kernel | 错误和陷阱统称为异常 |
| os处理指令触发fault后并修复,会重新执行该指令,缺页异常(page-fault)就依靠这个原理 | |
| os处理指令触发trap后并修复,不会重新执行该指令,常见的有int 3指令(以下3条均属于陷入(trap)的范畴) | |
syscall/sysret(x86-64 主流;由 IA32_LSTAR/STAR/FM ASK MSR 配置入口) |
|
| sysenter/sysexit(32 位“快速系统调用”) | |
| int 0x80(32 位旧式软中断;IDT 中该门 DPL=3 允许用户触发 | |
| 异步中断 (hardware IRQ / IPI / NMI → kernel) | 通常发生在外围设备,比如硬盘读写操作完成,系统会切换到硬盘读写的中断处理程序中执行后续操作 |
1.5.1 切换原理:以syscall为例
在系统启动时,处于ring0状态,内核会设置MSR_LSTAR指向syscall handler routine,即系统调用处理表
系统启动后,当用户态(ring3)想要和内核交互时,可以通过系统调用(syscall)进行:
1. Privilege level switches to Ring 0.
2. Control flow jumps to value of MSR_LSTAR.
3. Return address saved to rcx
详情可参考https://www.felixcloutier.com/x86/syscall
当内核处理完相应事务后,回退用户态时,通过sysret进行:
1. Privilege level switches to Ring 3.
2. Control flow jumps to rcx.
1.6 内核态和用户态空间的关联
用户态空间位于虚拟地址空间的 低地址处, 内核态空间位于虚拟地址空间的 高地址处。
诸如系统调用,并没有改变虚拟地址的映射,只不过内核态空间的访问需要ring0权限
2. kernel module
A kernel module is a library that loads into the kernel
kernel module通常是.ko结尾的文件(可以类比.so文件)
1. .ko也是elf文件
2. 这个文件会被加载到内核空间
3. 拥有和内核一样的执行权限
kernel module在日常生活中是很常见的,比如驱动(显卡驱动)、文件系统、网络功能都是通过kernel module部署进内核的。
2.1 kernel module交互方式
2.1.1 中断(这里虽然说是中断,本质上还是一个trap)
kernel module是能够注册interrupt handler(中断处理器)来捕获一些特殊的指令,比如int 42
当然,hook一些已有的指令也是可行的:
int3 (0xcc): normally causes a SIGTRAP, but can be hooked!
int1 (0xf1): normally used for hardware debugging, but can be hooked
甚至我们可以注册一个非法指令int 66,当运行到这个指令时,会跳转到我们的kernel module进行处理。
2.1.2 通过文件访问
kernel module可以通过在以下3种路径注册一个文件,这样用户态代码能够通过open()函数打开文件并于内核交互!
1. /dev: mostly traditional devices (i.e., /dev/dsp for audio)
2. /proc: started out in System V Unix as information about running processes. Linux expanded it into in a disastrous mess of kernel interfaces. The solution...
3. /sys: non-process information interface with the kernel.
如果kernel module编写了某些函数,那么用户态程序就可以像操作文件一样与kernel module交互:
// 1. 文件读写
//kernel module
static ssize_t device_read(struct file *filp, char *buffer, size_t length, loff_t *offset)
static ssize_t device_write(struct file *filp, const char *buf, size_t len, loff_t *off)
//userspace
fd = open("/dev/pwn-college", 0)
read(fd, buffer, 128);
// 2. ioctl
//kernel module
static long device_ioctl(struct file *filp, unsigned int ioctl_num, unsigned long ioctl_param)
//userspace
int fd = open("/dev/pwn-college", 0);
ioctl(fd, COMMAND_CODE, &custom_data_structure);
linux命令行上如何安装/查看/删除驱动:
安装: insmod mymodule.ko
通常会调用init_module系统调用
查看: lsmod
删除: rmmod mymodule
通常会调用delete_module系统调用
3. kernel memory management
3.1 物理内存和虚拟内存
物理内存指的是计算机架构里的ram,计算机也只有一块物理内存,实际的地址布局如下:
 实际上,物理内存里只有一个区域的地址是
实际上,物理内存里只有一个区域的地址是0x401000,通常程序都是加载到0x401000的位置的,我们如何加载多个程序呢?
有一个可行的方案是PIC(position independent code),就像so一样,程序可以加载到内存里的不同位置。但是这样还是有问题,多个程序都在一个地址空间里,没有隔离,一个程序A能够越界写到程序B的空间,很容易就导致两个程序都崩溃。
为了解决隔离问题,虚拟内存方案出现了,简单的说内核会维持虚拟内存和物理内存的映射关系,如下图所示:每个程序都有自己的虚拟内存空间,且他们映射到不同的物理内存当中
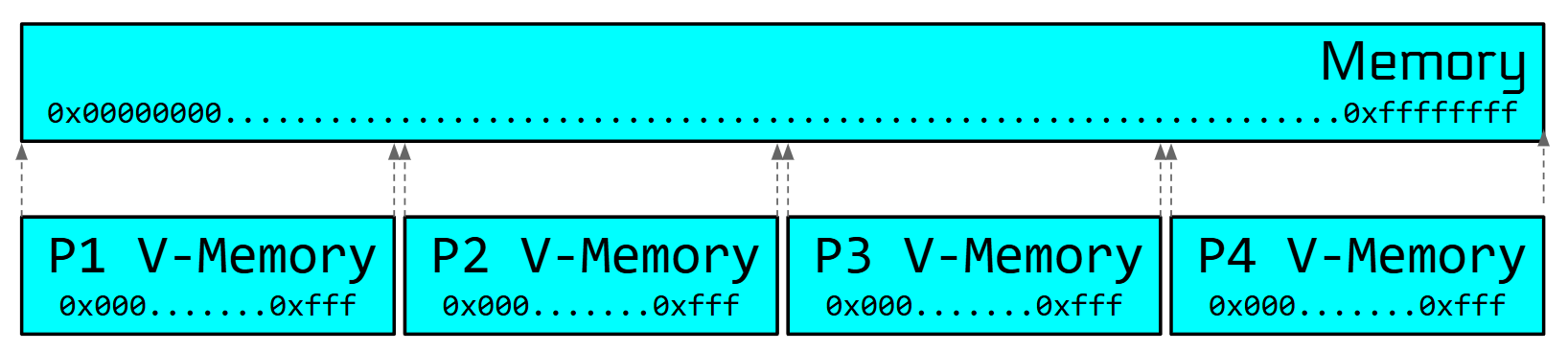
3.2 虚拟内存方案
最原始的虚拟内存方案,它假设每个进程只需要4kb内存,如下图所示:
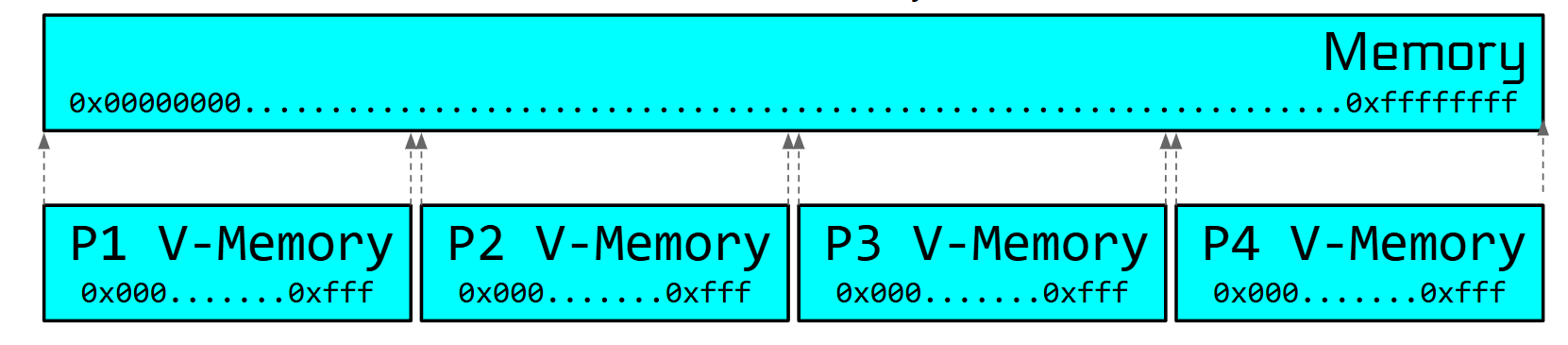 即,一个进程的地址空间,在虚拟内存/物理内存都是连续的。但是如果一个程序动态分配了更多内存,这将导致规则被破坏。
即,一个进程的地址空间,在虚拟内存/物理内存都是连续的。但是如果一个程序动态分配了更多内存,这将导致规则被破坏。
为了解决程序需要更多内存的需求,新的虚拟内存方案出现了:进程布局在物理内存中不连续,在虚拟内存连续
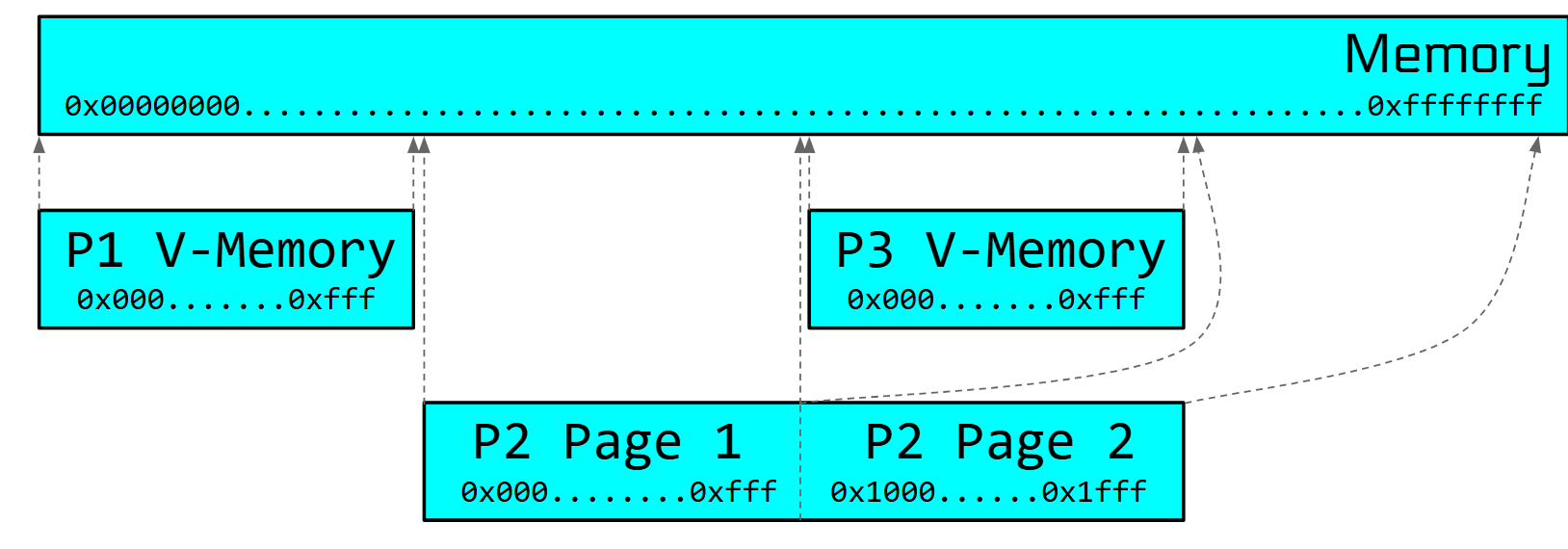
3.3 页表、页目录、页目录页表、页映射等级4
上面提到,内核会维护每个进程虚拟地址和物理地址的映射,而维护映射的数据结构就是页表(page table)
1. 一个页表,维护512个页表条目(page table entries),
2. 一个条目8字节,所以一张页表需要4kb(4096字节)
3. 另外每个条目实际指向的是大小为4096字节的物理内存区域,所以一张页表消耗4kb的内存,能够维护2mb的内存映射

然而,我们知道一个程序是远远不止2mb的,有大聪明又发明了一个概念,页目录(page directory)
1. 一个页目录,维护512个页目录条目(page directory entries)
2. 每个页目录条目8字节,都指向一张页表,一个页目录也需要4kb(4096字节)
3. 那么现在,一个页目录,能够维护512*2mb=1gb的虚拟内存映射!
 有时候
有时候PD(页目录)中的PT(页表)条目的低12位都是0,所以可以用来设置特殊的flag标志,使PT条目指向另一个页表,而是指向一个2MB的物理内存(这样还能省1kb的内存空间)
计算机的发展永无止境!1gb还不能满足需求怎么办!我再加一级数据结构页目录页表(page directory page table)
1. 一个页目录页表,维护512个页目录指针
2. 每个页目录指针8字节,都指向一张页目录,一个页目录页表也需要4kb(4096字节)
3. 现在,一个页目录页表,能够维护512*1gb=512gb的虚拟内存映射!
 现代的计算机,都是通过4级页表来进行物理内存的维护!页映射等级4(Page Map Level 4)
现代的计算机,都是通过4级页表来进行物理内存的维护!页映射等级4(Page Map Level 4)
1. 一个PML4,维护512个页目录页表指针
2. 每个页目录页表指针8字节,指向一个页目录页表,每个PLM4也需要4kb(4096字节)
3. 现在,一个PML4,能够维护512*512gb=256tb的虚拟内存映射!
 为了能够方便的索引(加快索引速度),实际上的虚拟地址转换是有规律的:
为了能够方便的索引(加快索引速度),实际上的虚拟地址转换是有规律的:

3.4 进程间隔离、虚拟机隔离
每个进程都有一个PML4表,它放在CR3寄存器当中.
只能在ring0状态下,我们才能访问CR3寄存器
虚拟机的隔离就相当变态了,因为每个虚拟机都认为它能访问所有的物理内存
4. kernel mitigations
kernel中的安全缓解措施和用户态时遇到的类似:
1. stack canaries: 保护栈的机制
2. kaslr:内核中的地址空间布局随机化
3. Heap/stack regions 有NX机制,即不可执行
4. SMAP/SMEP: 开启这俩个机制后,内核态无法访问/执行 用户态的地址空间。 但是SMAP是可以被关闭的,因为有些时候内核需要读取用户态的数据(copy_from_user)
5. kpti: 内核页表隔离,即用户态只有部分内核代码映射,而内核态会有全量的代码映射
5. kernel 利用思路
总的来说,一般从3个方向考虑内核的利用:
1. From the network: remotely-trigged exploits (packets of death, etc). Rare!
几乎不存在
2. From userspace: vulnerabilities in syscall and ioctl handlers (i.e., launched from inside a sandbox!)
现在最多的手法
3.From devices: launch kernel exploits from attached devices such as USB hardware (https://www.pjrc.com/teensy/)
也比较少