6. 设计硬件抽象层
请先看下图所示的架构:
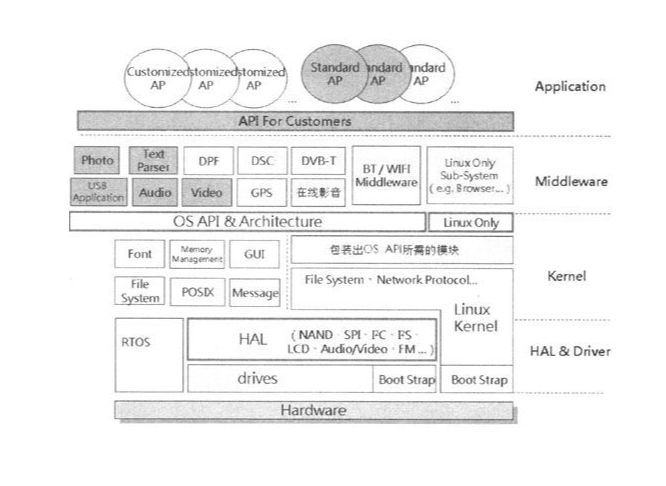 这个架构同时要支持两种系统(RTOS与Embedded Linux),但我们又希望driver可以共享,不要有两套,否则maintain将会是个大麻烦,所以在driver上再加了一层HAL,所谓HAL就是将硬件抽象化,Linux可以基于HAL再往上开发自己格式的driver。
这个架构同时要支持两种系统(RTOS与Embedded Linux),但我们又希望driver可以共享,不要有两套,否则maintain将会是个大麻烦,所以在driver上再加了一层HAL,所谓HAL就是将硬件抽象化,Linux可以基于HAL再往上开发自己格式的driver。
HAL的另一个好处是就算硬件配置做了修改,也只需要修改driver,两方系统都不需要大更动。
6.1 由eCos & amp;Android的系统架构谈起
般通用性的嵌入式操作系统,如VxWorks、μCOS II等,可能应用在截然不同的产品上,硬件配置南辕北辙,所以很难去定义通用的HAL;但如果我们的产品线定义颇为明确的话,若希望我们的系统能够具有可扩展性,可以用较少的effort来执行未来的项目,那么,HAL就不可或缺。
Open Source的嵌入式操作系统——eCos,它的系统架构就明确定义了HAL这一层
我们来看另一个例子。最近火红的手机系统Android,因为Android的应用锁定在手机上,且智能手机的硬件架构差异有限,所以可以看到Android的HAL中就包含了许多硬件设备。
举例来说,不同的手机制造商可以选用不同的GPS硬件模块,只要能按照Android HAL中对GPS设备所定义的行为模式(如送出位置信息的格式),并包装出指定的API,则其他程序都不需要修改,内置的导航应用程序应该就可以正常运行。
6.2 HAL vs. BSP
HAL之前已经提到很多了,现在具体说说BSP的定义
■ BSP(Board Support Package):BSP介于主板硬件和操作系统间,其功能与PC主机板上的BIOS相类似,主要功能为完成硬件初始化,并切换到相应的操作系统。
■ BSP是相对于操作系统而言的,不同的操作系统会对应于不同定义形式的BSP。例如,某一CPU上的VxWorks BSP和Linux BSP,尽管实现的功能一样,但写法和接口定义是完全不同的。
■ BSP单纯只支持某个硬件板子的配置,无法用于其他板子、CPU或操作系统。举例来说:微软定义BSP是由Boot-loader、OAL(OEM Adaptation Layer)、Device Driver及Run-Time Image Configuration File这几个组件所构成。
所以BSP和HAL是不一样的东西,应用时机也不同。BSP是针对某个板子的硬件配置,进行驱动程序套件开发,并包装出某种OS的接口,让使用者拿到板子后,可以很快地将OS与应用程序移植到这个板子。Linux、VxWorks、Microsoft Windows Mobile都有BSP这样的说法
相较于HAL,BSP是一专用于某个板子、某种系统的一组驱动程序套件,但HAL是一种概念、一组作为系统标准的API。嵌入式系统基本上是个分层架构,上层通过下层提供的API与下层沟通,而分层的好处就在于只要API不变,上层不需要知道下层的实现方式与细节,就算下层模块整个切换或全部改写,上层程序都不需要修改.
6.3 为什么会需要HAL?
很简单,为了减少未来开发的成本,建立商业竞争的领先
假设第一代产品大卖,此时竞争对手肯定会争相研发同样的产品,为了保持自身的领先,此时当然需要投入资源到第二代产品的开发当中,此时,如果第一代产品设计了HAL,那么进行第二代产品开发说,会大大减少开发成本和时间耗费。
6.4 HAL是否会增加开发难度?
直接说结论:不会
通常我们实现HAL的流程如下:
Step01:定义HAL的规模(Scope)。根据产品特性,分析上层的系统与应用程序需要哪些硬件功能,这些需求就是HAL必须要包含的基本模块,然后再根据硬件配置,分析是否仍有目前系统没用到的硬件功能,这些功能可能在下一代产品就会被用到,我们可为其设计相应HAL模块的API,但在本项目内可先不implement。
Step02:定义HAL API。如果可以的话,最好从硬件到应用程序的开发小组,都要派人员参与HAL设计工作,否则至少要有资深的系统与固件工程师参与,不能仅由一个部门闭门造车。一般定义HAL API步骤为:
□ 系统工程师说明系统需求,包含系统对硬件事件的处理方式。
□ 固件工程师根据硬件功能,提供第一版的HAL API定义文件。
□ 系统工程师协同固件工程师,逐一review HAL API。
□ 在HAL API立项前,必须针对项目中的所有软件工程师做详细报告,收集建议,并做必要的修正。
Step03:由固件工程师负责实现所有HAL的功能,并执行每个模块的单元测试。
Step04:固件工程师release第一版HAL library,由系统工程师负责整合测试,若有需要。各个部门随时可以提出对HAL API增修的建议。
HAL的设计立项后,固件工程师就是照着文件去implement,而系统工程师就被规范只能用HAL API来控制硬件,并不会增加工程师们在实作阶段的工作量。就算系统架构中没有HAL,一般driver的开发流程和上述步骤也差异不大吧.
没有人能够一开始就预知未来,所以不可能直接开发出完善的HAL,只要后续能继续补上就可以了
6.5 HAL实例
6.5.1 HAL基本设计原则
■ 往前兼容(新版HAL的API可以变多,但不能变少)。
■ HAL旨在对硬件做抽象化,不应与任何系统有直接关系。若OS对driver有特殊的需求(如Linux有制式的driver写法),应由系统团队根据需求自行在HAL之上,再往上包一层high level driver。
■ Driver模块化,尽量降低driver之间的耦合程度。这个原则相当重要,因为我们设计HAL的主要目的之一,就是未来项目的硬件配置可能改变,而我们只要切换驱动程序即可。若driver间耦合度过高,则系统的可移植性与HAL的优势将大打折扣。
■ 每个driver分别设计,但章节内的结构必须保持一致,应该包含以下信息。
□ 数据结构
□ API
□ 控制流程或状态机
□ 会产生的硬件事件,以及事件传递流程
■ 每个driver模块应该尽量包装出以下的API,以保持所有driver模块的API风格一致,使得系统在使用HAL API时,比较不会发生误用的状况。
□ Open():执行该设备的初始化工作(包含硬件初始化、取得driver所需之buffer、数据结构或配置的设定)。
□ Enable():driver开始运行。
□ Disable():driver暂停运行。
□ Close():关掉硬件设备,还回已配置的buffer,重设(Reset)driver的数据结构或配置。
□ Set_Power_mode():设定该设备的power mode(如full run、idle、sleep mode),即便有些设备无法实现这么多种的power mode,甚至有些设备根本不需做电源管理,HAL设计者还是可以考虑为此设备包出空的Set_Power_mode()函数,以保持所有driver API的一致性。
■ driver与power manager的配合:driver仅提供电源管理的mechanism,而电源管理的policy由系统的power manager统一管控,即HAL中的每个driver模块都必须配合power manager的需求,例如都必须实现Set_Power_mode()这样的API。
■ HAL的每个driver模块都必须遵守共同命名规则与API style。
■ 统一定义HAL的系统配置(Configuration):这些配置必须开放给系统使用,使得本项目不需要的driver模块或功能不会被link进来.
6.5.2 HAL的系统架构
刚刚提到driver之间的耦合程度越低越好,但driver间难免也是会有阶层关系,例如I2C driver与FM Module Driver(可播放FM广播的芯片,与其他必备零件整合在一个比拇指小的板子里),主控IC通过I2C对其FM Module下命令,FM Module就会根据设定开始接收与播放FM频道。以HAL设计的角度来看,虽然I2C在这个项目只用来控制FM Module,但其他项目可能会用I2C来控制其他芯片,所以I2C必须是独立的driver,而FM Module Driver则通过调用I2C的API来运行。
就如同系统设计会做出各个模块之间的关系图,包含模块间的调用关系、参数传递的规范、共享全局变量的规则、模块间运行的流程与顺序等,我们可以把HAL当作一个独立的子系统,所以在进入个别driver的设计阶段前,HAL设计文件必须比照系统设计文件,事先定义出所有driver间的关系,作为设计个别driver时的规范。
6.5.3 驱动程序与系统的沟通机制
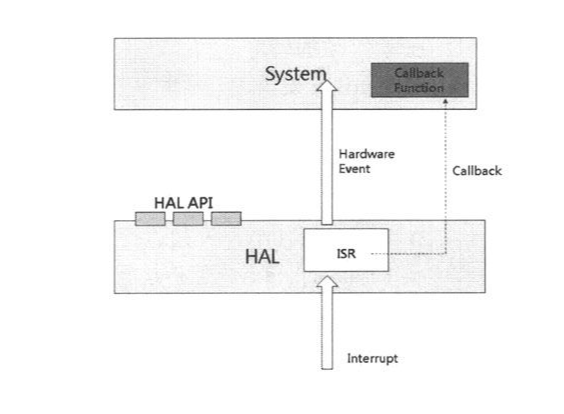
■ HAL API:系统可以直接调用HAL开放的API。
■ ISR & Hardware Event:当硬件产生中断时,相应的ISR会被执行;当ISR处理完毕后,可将硬件事件抽象化,包装成硬件事件,往上层系统传递。以低电压事件为例,驱动程序自硬件读取的是AD值,必须将其换算为电压值(此举即为抽象化),并对上层传递此硬件事件。
□ 驱动程序可以把一个全局变量当作flag,当上层程序发现此flag的值改变了,即表示发生了某硬件事件。这种做法的时效性较差,且必须注意Critical Section的保护。
□ 在ISR内调用系统的功能,如send_message()、wakeup_task()等,这种做法是比较普遍的做法,但此举破坏了HAL必须与上层系统无关的规范。
□ 较好的做法是HAL不决定传递硬件事件的机制,改为提供API,让系统可‘注册’用以传递硬件事件的函数(称为callback function),ISR会在适当时机调用这些callback function,至于系统如何处理硬件事件,ISR并不会知道。
■ Callback:HAL提供注册callback function的API,并明确说明调用此callback function的时机。系统只要传入function pointer,HAL即会在上述时机调用这些callback function。例如上面所说的实时处理硬件事件,或是当HAL准备关机时,会去调用系统预先注册的callback fimction,让系统有机会做一些处理(如存储重要信息或目前的执行状态)。
6.5.4 难以抽象化的设备
例如某颗CPU的clock可以调整为3.768 K、12 MHz、24 MHz、48MHz4 个选项,那我们的 HAL API——hal_set_CPU—clock()的参数要如何设计?若下个项目换了较快的CPU,它的clock的设定值根本不一样,假设是3.768 K、16 MHz、32 MHz、64 MHz,这时候HAL API不就非改不可了吗?
为了解决这个问题,需要再往高端抽象化一层,如下图所示:

7. 菜鸟当自强:软件工程师硬起来
7.1 硬件开发流程
固件工程师应该参与hardware review meeting
好处如下
■ 可了解电路设计的主体,在设计阶段就可发现固件编写时必须特别注意的项目。
■ 若对某外部设备的控制方式不是很有把握,可以在电路设计时,请硬件人员预留其他设计方案(举例来说,驱动程序可以用SPI接口控制SD卡,也可以外接一颗SD card Controller。前者电路简单、成本低、速度慢;后者则刚好相反。在设计阶段,系统工程师不见得有把握使用SPI接口就可以符合产品应用的需求,此时可以请硬件工程师将两个方案都做到target board上)。
■ 不仅仅只有硬件工程师才可与硬件原厂联系,固件工程师也应该尽可能寻求原厂的协助,并多与硬件工程师交换意见。
■ 事前的讨论,胜过事后的争执。
硬件工程师需要配合固件工程师,固件工程师也应该提供硬件工程师一些帮助:除了板子验证阶段的测试程序外,软件工程师还必须额外提供一些程序给硬件工程师,通常这些程序可称为系统的工程模式(Engineering Mode)或测试模式(Self-Test Mode),主要用途就是快速地检测产品规格,并检查硬件是否可正常运行。
7.2 嵌入式软件开发工程师的基本艺能
虽然大部分硬件工作主要还是交给硬件工程师来干,但是软件开发工程师也至少会一些硬件技能:
1. 烙铁: 焊板子
2. 看懂电路图: 电路图是一种语言,它沟通的方式是利用简单的线段和符号去叙述组件之间的关系,电路图里包含各个组件及其PIN脚的名称,及所有组件之间的连接关系。
3. 电源供应器: 这你得会用吧
4. 三用电表: 高中物理就用过
5. 示波器: 大学物理有用过。
trigger(触发)功能是使用示波器一定要会用的技巧,示波器预设一直从探针中收集信号,即便探针没有点在有意义的测点也一样,一旦启动了示波器的Trigger功能,其设定决定了当信号发生某种变化时,示波器才会再开始显示波形,并记录一段时间内的波形变化。
8. 做好存储器管理
8.1 动态存储器空间配置
一般的嵌入式设备存储器由如下几个部分组成:
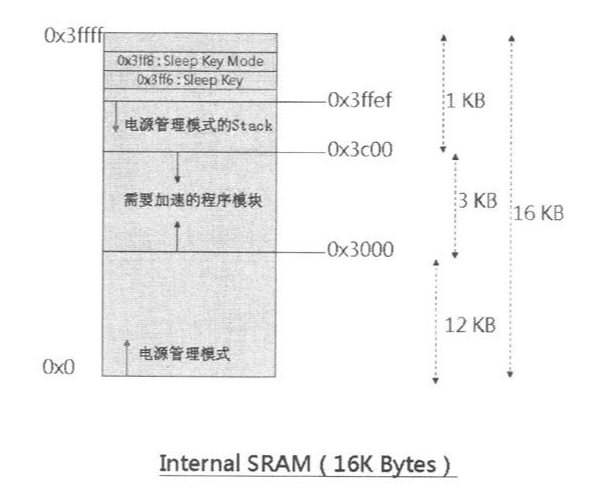
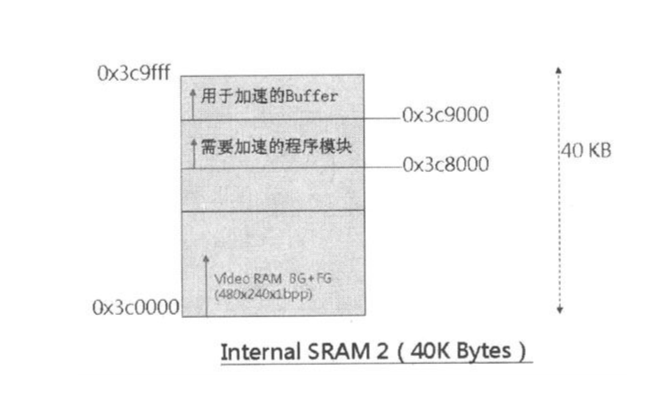
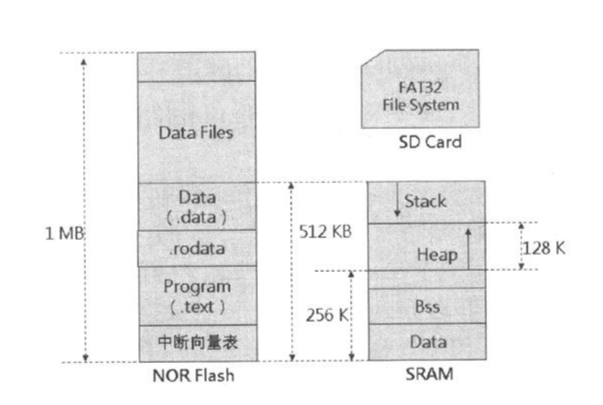
■ CPU Internal SRAM——CPU 内部有两块 RAM,分别是 40K Bytes 与 16K Bytes。作为LCD控制器的Video RAM,或用来加速程序模块的执行性能。
■ 外部NOR Flash——1M Bytes。用来放置程序与data,且程序可以在NOR Flash中直接执行,这块存储器也可以用Mask ROM取代。
■ 外部SRAM——512K Bytes。执行时期放置程序的所有变量(data段与bss段)、程序执行时所需的Stack Memory、以及动态配置存储器(Dynamic Allocation Memory)或缓冲区(Buffer)。
■ SD Card。我们的系统可支持SD Card,额外的大批数据可以存储在SD Card中。
但是应用开发工程师不需要知道这些细节,他们只需要知道地址范围即可:
 此时,对于一个
此时,对于一个100k大小的空间,可以放置的位置如下:
■ 放置在rodata区(Read-Only Data Section),程序中只要用数组的名称即可操作这批数据。
■ 如果上述数组不定义为const,则这批数据会被连接到data区(有初值的全局变量)。data区的数据也会占据可执行文件的空间,在执行时期会被复制到RAM中,所以程序可以改变这个数组的值。这个方法会加快操作这批数据的性能(RAM速度一定比Flash快),缺点是执行时期时同一批数据分别在RAM与Flash占据一份空间。如果没有改变内容与加速的需求,这么做实在是浪费空间。
■ 当NOR Flash或Mask ROM空间所剩不多,但RAM的空间还充裕时,有时候我们会考虑将这批数据压缩。
8.2 Stack
以前说过,一个程序的分布应该是如下:
■ 程序段(text段与rodata段):可直接在ROM或Flash中执行,也可将某个模块传输到速度较快的RAM里执行。
■ 有初始值的全局变量(data段):会占据可执行文件空间,执行时期必须将其从ROM或Flash传输到RAM。
■ 没有初始值的全局变量(bss段):不会占据可执行文件空间,执行时期必须将该区段的内容全部设为0。
■ Stack(堆栈)。
8.2.1 Stack 的用途
■ 在执行“call”指令时,会将返回地址存储(Push)到目前SP寄存器指到的位置(SP始终指到Stack的顶端)。
■ 当执行“ret”(Return)指令时,会自目前Stack的顶端取回(Pop)返回地址。
■ 当中断产生时,中断控制器会将发生中断的地址(返回地址)以及PSR(状态寄存器)存储(Push)到Stack里。
■ 当ISR执行“iret”(Interrupt Return)指令时,CPU会从目前Stack顶端Pop出PSR与被中断的地址。
■ 我们都知道Stack这个数据结构特性就是先进后出,CPU提供“push”与“pop”指令供程序员操作Stack,最常见的用途就是暂时将某些存储寄存器的值存在Stack中,在某些动作后,再‘依次’取回这些寄存器的值。此外,“push”与“pop”的动作必须是对称的,push多少东西到Stack,就必须记得依次pop多少东西出来,否则下次存取Stack时就数据就会乱掉。
■ Local变量会存储在Stack中,如果应用程序工程师不知道可以用的Stack有多大,一不小心就会把Stack用爆了。此外还要注意的是,用于嵌入式系统的编译器通常不会产生‘将局部变量的值设为0’的code,也就是说,一旦程序员没有明确指定局部变量初值的话,局部变量的初值可能是任何的值。如果程序员疏忽将没给初值的局部变量拿来使用,则结果自然是无法预测的.
■ 函数调用时,返回地址当然会根据目前SP寄存器,存储在Stack中,这是CPU的机制,C语言的函数自然也是如此运行。
■ 函数调用时参数的传递可以通过寄存器,也可以通过Stack,端视编译器的策略而定。通常如果参数个数不多的话,编译器会倾向用寄存器来传递参数,反之,则把参数存在Stack 中。
8.2.2 Stack Overflow
老生常谈了。
8.2.3 Stack & RTOS
我们从RTOS的角度来看Stack Memory的用途,一般用于嵌入式系统的CPU都不会具备虚拟存储器的功能,也就是说系统无法像Windows或Linux 一样为每个程序配置独立的虚拟地址空间,在这样的硬件限制下,RTOS要想实现多任务,其实靠的是Multiple-Task
在Windows或Linux上的多任务可分为两种,一种是Multiple-Process,另一种是Multiple-Thread。每一个Process有自己独立的地址空间,而且每一个Process内可以建立多个Thread,所以process内的所有Thread则位于同一个地址空间。
举个简单的例子来说明地址空间的概念。可以把process想象成不同的可执行文件(.exe),因为不同的process有独立的地址空间,假设不同的process都去存取同样的地址(如0×100000),实际上,操作系统会将其mapping到不同的物理地址,所以绝对不会互相冲突。至于同一个process内的不同Thread,因为共享地址空间,所以不同Thread存取同样的地址时就可能会引发冲突。因为Thread没有自己的地址空间,所以Thread之间切换的复杂度远比process间的切换低很多,而且由于多个Thread共享地址空间,所以Thread之间的通信相对简单。总之,只要做好critical section保护,Thread的性能较好、程序编写较简单,却同样可以达到多任务的效果,这也是目前Multiple-Threading程序设计方法广泛流行的主要原因。
用于嵌入式系统的RTOS的多任务功能就是上述的Multiple-Thread,通常嵌入式操作系统的书或RTOS的网站会把这个功能称为Multiple-Task,其实是相同的东西,只是名词差异而已。总之,就是所有的执行单位不论称之为Thread或task,都共享同一个地址空间
可以看看多任务的代码:


8.2.4 Context Switch
对于RTOS的Multiple-Thread的执行原理基本上可以想象成多个Thread轮流在CPU上执行,但无论如何,CPU只有一个,一段时间中只能有一个Thread获准取得CPU的使用权,同时RTOS必须妥善保存其他被搁置的Thread的执行状态,当换成另一个Thread执行时,它才可以顺利地从上次被Task-Switch的位置继续执行。RTOS用一个数据结构记录各个Thread的执行状态,我们称这个状态为Context(task之间的切换也称为Context-Switch)。每个Thread的Context中包含了该Thread上次被切换出去时所有寄存器的值以及一些系统信息,而Thread的Context会存储在自己的Stack中,Context Switch也是通过操作Stack完成。
Context Switch通常是通过一个可重入(Reentry)的函数完成,每一个task被切换出去的地址正是这个函数的最后一行(return)
可以看一下代码:

8.2.5 没有足够RAM供Stack使用的平台
对于没有足够RAM的CPU平台,比如8051系列(RAM只有256bytes),通常使用Keil C进行开发。
Keil C提供了以下3个办法:
1. Keil C compiler 会分析每个函数之间的调用关系,使用stack的大小等等,,在编译完成后会生成*.M51文件,里面会告诉你stack还剩下多少空间
2. 将函数的局部变量配置到外部固定RAM中(通过外接一个RAM解决)。
甚至会把没有调用关系的函数的局部变量,配置到同一处空间中,这个方法叫做**data overlaying**
3. 高级的Keil C版本会把没有被调用的函数自动省略掉
8.3 Heap:动态存储器配置
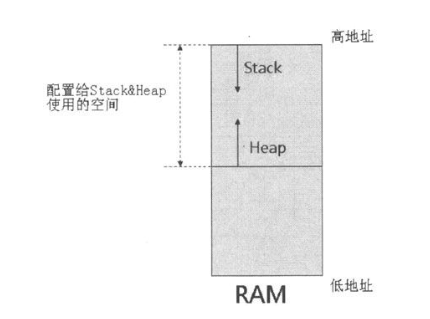
先看一幅传统的stack & heap的图:
8.3.1 Memory Allocate & Free
关于内存分配的算法,一般思路有如下三种:
■ First-Fit:自Memory Pool中存储器队列的开头往下找寻,直到寻得第一块空间大于或等于N的可用存储器区块。
■ Best-Fit:寻遍整个存储器队列,选择一块空间最接近N的可用存储器区块。
■ Worst-Fit:选择一块空间最大的可用存储器区块。有时采用此法的原因是size最大片的存储器区块段使用了一部分后,仍可供其他程序使用,减少小片段存储器区块的产生。
这三种都会不同程度的产生Fragmentation的问题,即总是有一小部分内存分散在存储器的各个位置,无法得到有效利用。缓解措施有如下几种:
■ 取一适当常数n,若配置后剩下的存储器size小于等于n,则整块存储器都分配给要求配置存储器的程序,这样可以减少小块存储器区块的产生。
■ 将存储器队列构建成环状队列,每次搜寻可用存储器区块都自队列的不同点开始搜寻,使得小块存储器可以尽量均匀分布在整个队列中。
■ 程序归还存储器区块时,系统必须检查该存储器区块的邻边是否也是空闲区块。如果是的话,必须将其合并为较大的一块存储器区块。
8.3.2 碎片处理?
随着程序每次执行的顺序与状态不同,会调用allocate/free的次数、顺序、大小也不同,当然,Memory Pool内存储器区块的状态也会大不相同。久而久之,整个存储器队列中会出现许多分散在队列各处,size比较小,明显用不到的存储器区块,这就是所谓的碎片(Fragment)。最差的状况是明明整个队列中可以用的存储器区块size总和还很大,但程序要求配置存储器时却找不到一块足够大的存储器区块,如果产品出货后才发生这个问题就麻烦了。
这是一个很棘手的难题:整个系统一定是经过长时间的运行才可能产生过多的碎片,至于中间到底做了什么操作实在很难一一记录,也就是说,不容易找到一个手法可以让问题重现,所以工程师要追踪问题并不容易。而且这种问题通常是长久累积下来的,并不一定是哪一支程序的bug,要修改就比较困难。
而garbage collection的思想在嵌入式设备中不适用
第一,在C语言中,系统配置一块存储器给程序后,程序得到的是一个指针,以后,程序就是通过这个指针来操作这块存储器。第二,所谓的Garbage Collection就是设法将所有不用的存储器或者碎片集合成一块,假使系统提供虚拟存储器的功能,那么,只要改变虚拟地址和物理地址的对应关系,程序就可以使用同样的指针继续正确运行。如果我们的系统无法提供虚拟存储器,修改内存的分布后得到的结果如下图所示:
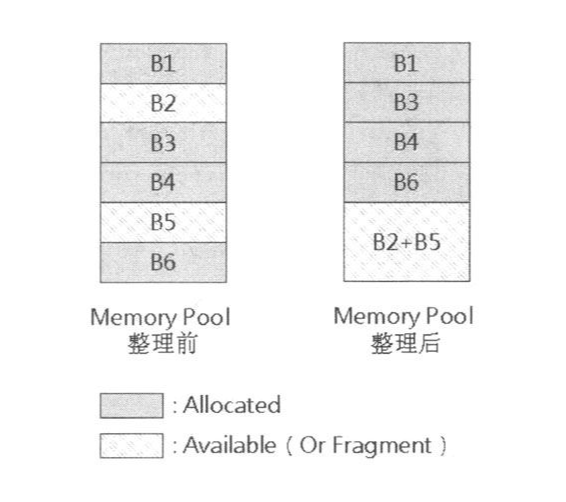 这就导致一个问题:代码中的指针仍然指向原来的位置,它不知道原本它指向的内容已经发生了位置更换
这就导致一个问题:代码中的指针仍然指向原来的位置,它不知道原本它指向的内容已经发生了位置更换
其实,碎片的问题往往由工程师的不良习惯导致:
■ allocate 了一块存储器,当不使用后却没有归还,这样就会产生一个垃圾碎片。如果这个有问题的模块一再被执行,系统累积的垃圾碎片就会越来越多,最后终于导致程序要不到任何存储器可以用。
■ 负责allocate动态存储器的程序与负责free的程序属于不同的模块,这也是碎片产生的原因之一。主要是因为不同模块的设计逻辑、设计理念与负责工程师可能都不相同。实际上,这种设计方式确实经常造成有些存储器区块没有被free,应该尽量避免这样的设计。
■ 连size很小的存储器区块(如一个short int)都要向系统allocate。这样的程序风格未免有点矫枉过正了,无谓增加Memory Pool中的区个数,对动态存储器管理系统的性能自然会有所影响。
■ 因为动态存储器管理程序会把邻接的未使用的存储器区块merge成一块,所以工程师在配置与free存储器区块时要稍微考虑一下顺序,有时候稍微改变一下顺序就可以避免碎片的产生。
8.3.3 保护Heap?
除了要求工程师改善程序编写习惯之外,几乎没有预防Stack被误操作的方法,Heap被破坏的问题也是如此,而且更容易发生
对于heap的bug寻找,这个做法很有用:
说穿了方法也不复杂。首先,系统要先实现一个检查目前存储器队列是否正常的函数,如sys_checkMemoryList(),这个函数也很简单,只要遍寻整个Memory Pool队列,把所有区块的size累加,看是否等于原先Memory Pool的size。或者存储器区块的header中可以包含特殊的信息,例如owner ID或magic number (header某个栏位的值一定是特殊数字,如果不是的话,表示已被破坏),若有异状表示Heap也已被破坏。
有了这个检测的函数后,接下来先找出一个最简单就会出问题的操作手法,然后利用上述检查存储器队列的函数(sys_checkMemoryList()),确认在问题发生之前,存储器队列已经不正常了。然后让在出问题之前所有执行过的函数,都去调用sys_checkMemoryList(),就可以查出在哪一个函数内存储器队列的状态由OK变成NG,仔细检查一下这个函数就八九不离十了
8.4 烧录器
之前我们已经提过ROM模拟器,顾名思义,它是一个用来模拟ROM的设备,工程师可以把这个设备一边连接到机器上ROM的插槽,一边连接到PC (串行端口或USB),然后从PC将欲烧录到ROM的内容(Binary File)传送到这个设备中,则机器就可以执行或存取ROM模拟器中的程序或数据,就如同有一颗真的ROM焊在机器上一样。
至于要将Binary File写入实际的EEPROM或NOR Flash中,则必须通过烧录器。烧录器的种类、品牌繁多,好的烧录器有容易使用的PC端控制程序、可以支持多种存储器种类,或者可以同时烧录多颗存储器芯片
烧录的流程一般如下:
Step01 :将Binary File转换成烧录器控制程序可接受的格式,如HEX或S-Record,这些都是标准的格式,通常烧录器或编译器套件中都会包含相关的转换工具。
Step02:载入欲烧录的文件。
Step03:擦除(Erase)存储器芯片的所有内容。有些存储器芯片不能用控制的方式,必须先经过紫外线照射,才能擦除存储器芯片内的所有内容.
Step04:将欲烧录的内容写入Program存储器芯片。
Step05:自烧录完毕的存储器芯片中读出内容与原始数据比较(Verify),确认烧录的正确性。
8.5 突破物理存储器大小的限制
电子产品的人,总是特别想用少的成本,完成更大的功能。于是开发厂商就如何让100M的物理内存,实际用起来让人感觉是200M,内卷了起来:
■ 虚拟存储器(Virtial Memory):要让程序认为自己有足够大的虚拟存储器空间可使用,通过CPU所提供之虚拟地址与物理地址的转换机制,暂时没用到的存储器内容可以存储在Secondary Storage (如硬盘、NAND Flash)中,当程序access到相应的虚拟地址时,CPU会产生硬件事件(Page Fault),通知系统从Secondary Storage置换存储器内容。而这一切对应用程序来说都是透明的。
■ 动态载入:并非所有的CPU都会提供虚拟存储器的功能,但系统仍可使用Secondary Storage当主存储器的缓存区,只有在需要某个程序或数据区段时,才将其载入主存储器的特定位置。因为这个方案没有CPU介入,系统或应用程序必须做较多的处理。
■ Banking: 8 bit MCU的寻址空间只有64 KB,对较复杂的应用远远不足,就算使用较大的物理存储器也无法突破MCU既有的硬件限制。一般的解决方案为系统可利用GPIO模拟地址线,扩充寻址空间,使得系统可以使用大于64 KB的存储器。大部分Compiler都会提供banking的支持,即系统只要提供操作模拟地址线之GPIO的程序,Compiler会处理相关寻址的工作。对应用程序而言,寻址空间扩充也完全是透明的。
8.5.1 虚拟存储器
学过OS估计都学过这个:
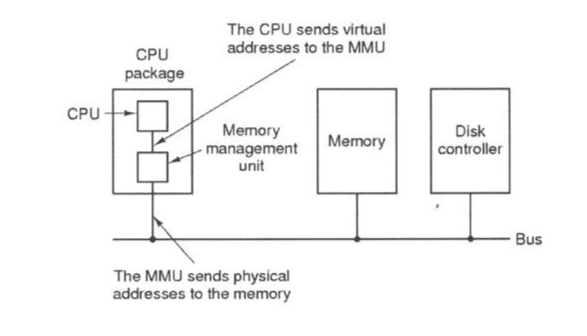
■ 虚拟地址:以32 bit的CPU来说,应用程序会认为其有完整的4 GB空间可用,但物理存储器当然不会那么大,所以应用程序可使用的空间称之为虚拟存储器空间,而应用程序指令送出的地址都是虚拟地址。
■ 物理地址:顾名思义,物理地址就是实体RAM的地址。CPU里的MMU (存储器管理单元)和操作系统要做的事情,就是将应用程序传来的虚拟存储器转换为物理地址,并将正确的内容放到这个物理地址。
从软件来看,应用程序与操作系统用的都是虚拟地址,但操作系统必须维护虚拟与物理地址的对应表,因为地址对应的基本单位为Page (Page Size乃基于CPU的设定),所以称此表格为Page Table。
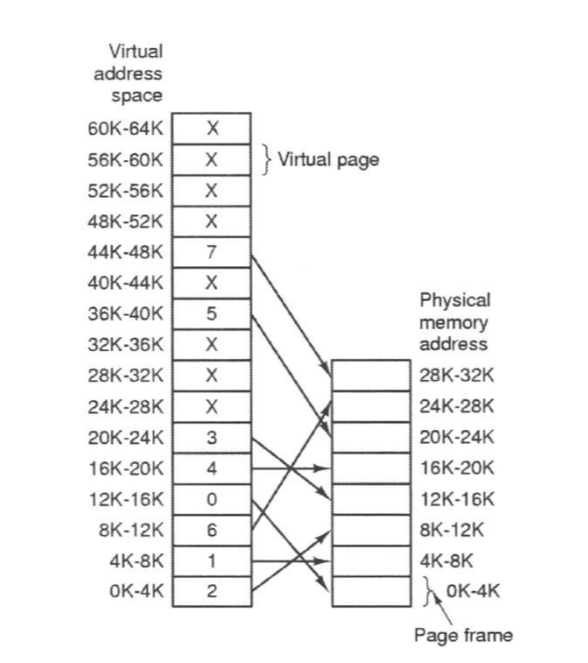
8.5.2 动态载入
RTOS是Single Address Space/Multiple-Tasking的系统,通常应用于没有MMU的平台,所以要应用Secondary Storage来存储程序或数据段,只能由系统自己来实作类似Windows DLL(动态载入函数库)的功能。简单地说,程序里用到的某些函数并未真正被连接到可执行文件里,直到runtime该函数被调用时,系统才会将其载入存储器并执行之。
在存储器的特定地址中保留空间给动态载入模块使用,则这些模块在编译/连接阶段都可以连接到这个已知地址,从而避开了动态连接的麻烦。
解决了动态载入模块的寻址问题后,另一个麻烦是因为要被动态载入的程序段并未与系统程序连接,所以无法直接调用系统功能。有几种做法可以解决这个问题,一种是用Software Interrupt指令,利用寄存器或Share Memory传送系统功能编号与参数(例如,规定系统功能os_draw_pixel(x, y)为第5号功能),而系统可以从Software Interrupt ISR启动动态载入模块所需的系统服务。举例来说,嵌入式系统操作系统free-DOS就是利用硬件中断(Software Interrupt)来提供系统服务。
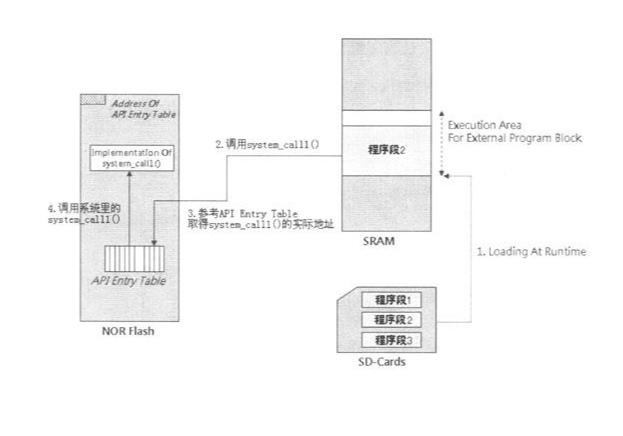
并不是所有的CPU都有提供Software Interrupt指令,此时,系统必须设法让动态载入模块可以取得每个open API的实际地址,最简单的方式就是建一个表格,并放置在存储器的特定地址。图12-18所示是一种实现方法的流程。
这个范例的系统配置为:系统与内部API烧在NOR Flash内,动态载入的模块则存储在SD card内,这些程序段都被寻址到SRAM中固定的地址。当动态载入的模块调用了system_call1()这个系统函数,其实是执行了下图所示的步骤3、4,而这些动作对该模块而言都是透明的。
8.5.3 Banking
最后,我们来说说如何突破8 bit MCU地址空间太小的限制。诸如8051这种MCU的Data Bus只有8条,所以称为8 bit MCU。但其地址线有16条,其可寻址的最大空间为2^16,也就是64 KB
这已不是增加成本、加大存储器就能解决的问题,问题症结在于MCU的地址线只有16根。
虽然最直接的办法是通过增加地址线,但是增加了地址线,CPU提供的指令只能处理16位,增加地址线,就意味着也要修改CPU指令集,成本太高
有个简单的方法,就是利用GPIO来模拟地址线,这个方法称为Banking,其原理如下:
■ 有两块64 KB的ROM。
■ 当GPIO #1为High时,CPU的地址线与chip select都接到第一块ROM。
■ 当GPIO #1为Low时,CPU的地址线与chip select都接到第二块ROM。
这个方法也有问题,就是程序员需要自己配置函数的地址到各个ROM中;好在编译器能够帮我们解决这个问题:
■ 函数与变量位置配置优化。
■ 应用程序只管直接做函数调用,不需要处理Bank-Switch相关工作。
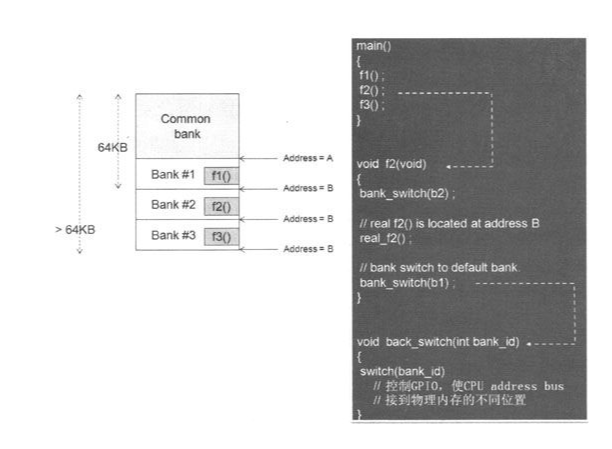 左半部是物理存储器的配置,其中Common bank是永远不会被置换的区域。通过硬件设计,bank#l、#2、#3的起始地址都是B,可以利用GPIO来做bank切换;对MCU而言,同一时间可以操作的就是Common bank与bank #1、#2、#3三个其中之一。系统中有3个函数fl()、f2()、f3(),Compiler分别将其配置到bank #1、#2、#3
左半部是物理存储器的配置,其中Common bank是永远不会被置换的区域。通过硬件设计,bank#l、#2、#3的起始地址都是B,可以利用GPIO来做bank切换;对MCU而言,同一时间可以操作的就是Common bank与bank #1、#2、#3三个其中之一。系统中有3个函数fl()、f2()、f3(),Compiler分别将其配置到bank #1、#2、#3
工程师并不会知道f1()、f2()、 f3()分别被配置到哪一个bank,他只知道如图所示的右半部程序里的main(),直接调用函数名称。举例来说,当main()调用了 f2()时,Compiler会产生一些额外的code,如图所示程序中的f2()。只有Compiler才知道这个函数被配置到了哪个bank,所以f2()会先执行Bank-Switch,然后才真正去调用这个函数的程序(如图所示程序的real_f2())。
要注意的是,Compiler并不知道我们会用哪些GPIO脚来模拟Address Bus,所以上述bank_switch()是由我们系统设计者根据Compiler的规范来编写,并指定这个函数让Compiler知道即可。