malloc(主线程)
1.tcache bin
先从tcache bin中寻找可用的chunk。
2.fast bin
tcache bin中如果没有,会尝试从fast bin中获取可用chunk(在比较新版本的glibc中,在tachebin中没有chunk而fast bin中有chunk的情况,会将fastbin中的chunk拆出,放入tcache bin中)。
3.small bin
接下来尝试在small bin中寻找可用chunk.
4.unsorted bin
在smallbin中没有chunk时,会进行consolidate流程,合并fastbin中的chunk并放入unsorted bin中。从unsortedbin中找合适的chunk
5. large bin
以上4步都没有分配到合适chunk时,在large bin中寻找chunk
6. top chunk
large bin没有时,会在top chunk中切割一小块内存。
7. sysmalloc
连top chunk都没有足够内存时,如果申请的size过大,会尝试使用mmap分配;
否则会使用brk函数尝试扩展top chunk后再进行分配;
malloc(非主线程)
对于非主线程来说,每个线程会有一个独立的arena管理一个区域(均有mmap分配而来)。<br
采用如下函数进行测试:
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
void * thread1(void * arg){
int i = (int)*((int *)arg);
char * a = malloc(0x20);
printf("%d: chunk address:%p\n",i,a);
}
int main(){
int i;
long long ret[10];
pthread_t tid[10];
pthread_attr_t pthread_attr[10];
int number[10];
for(i=0;i<5;i++){
number[i]=i;
pthread_attr_init(&pthread_attr[i]);
pthread_attr_setdetachstate(&pthread_attr[i], PTHREAD_CREATE_JOINABLE);
pthread_create(&tid[i],&pthread_attr[i],thread1,&number[i]);
pthread_join(tid[i],NULL);
pthread_attr_destroy(&pthread_attr[i]);
}
return 0;
}
运行结果如下图所示:
 可以看到 每个chunk分配的地址都位于文件映射区域,因此非主线程arena管理的memory由mmap分配而来。
可以看到 每个chunk分配的地址都位于文件映射区域,因此非主线程arena管理的memory由mmap分配而来。
但是由一个问题,刚刚上面提到了,每个非主线程对应一个arena管理内存,为什么创建了5个线程,其实都位于一个arena中呢?
使用如下代码进行测试:
#include <pthread.h>
#include <stdio.h>
#include <stdlib.h>
void * thread1(void * arg){
int i = (int)*((int *)arg);
char * a = malloc(0x20);
printf("%d: chunk address:%p\n",i,a);
getchar(); //difference1
}
int main(){
int i;
long long ret[10];
pthread_t tid[10];
pthread_attr_t pthread_attr[10];
int number[10];
for(i=0;i<5;i++){
number[i]=i;
pthread_attr_init(&pthread_attr[i]);
pthread_attr_setdetachstate(&pthread_attr[i], PTHREAD_CREATE_DETACHED);//difference2
pthread_create(&tid[i],&pthread_attr[i],thread1,&number[i]);
pthread_join(tid[i],NULL);
pthread_attr_destroy(&pthread_attr[i]);
}
return 0;
}
这段代码和上述代码只有2个不同,一个是每个线程都添加了getchar()函数让线程不会销毁,其实是使用 PTHREAD_CREATE_DETACHED参数,使得主线程在调用pthread_join函数时不会因为线程未结束而陷入等待。其结果如下图所示:
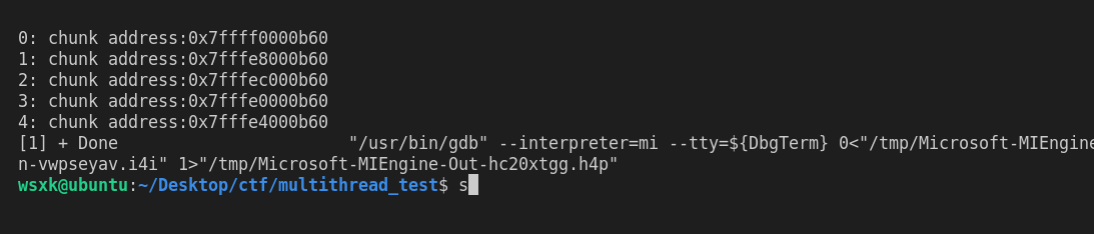 可以看到,在存在多个线程时,每个线程申请的chunk都对应一个arena管理的区域,每个chunk的地址差别也很大。
可以看到,在存在多个线程时,每个线程申请的chunk都对应一个arena管理的区域,每个chunk的地址差别也很大。
free流程
1.放入tcachebin
如果符合tcachebin且tcachebin没有满,放入tcachebin
2.放入fastbin
3.放入unsortedbin
如果释放的chunk既不能放入tcachebin,也不能放入fastbin,会进行合并操作(前向合并和后向合并),随后放入unsorted bin中
当然,如果被释放chunk的下一个chunk是top chunk,会直接合并到top chunk中。