1. 集中式版本控制与分布式版本控制
版本控制其实指的是维护一个项目工程的历史信息,方便进行回溯或修改。
有版本控制其实也好理解,比如想windows操作系统这么大的一个项目,一个人肯定是开发不完的,需要几百人联合开发,联合开发就面临一个协同的问题(如果有2个人对同一段代码进行了不同程度的修改,那选那个作为正确的修改?)。这时候就需要版本控制工具方便你们进行协同了。
版本控制工具从 集中式 发展到了 分布式
- 集中式版本控制的历史记录都存放在中央服务器上
- 而分布式版本控制 每个人的电脑上都有一个完整的仓库,远程服务器维护一个完整仓库,好处也是显而易见的,即使远程服务器出问题,也能方便的进行修复。
git就是很常用的一个分布式版本控制(version control)工具。github上的所有开源仓库都是通过git来上传、更新和修改的。
因此我们从git的原理开始逐步学习git以及它的常规用法。
大家可以看https://missing.csail.mit.edu/2020/version-control/来学习git的基础,如果不喜欢看纯英文也可以看笔者写的精简版(
2. git model
git使用两种基本结构来描述文件和目录:
文件 使用 blob 来进行描述,blob本质上是一串字节。
目录 使用 tree 来描述,tree本质上是一种map类型的变量,用于存储<变量名称,变量类型>. 最高层目录 使用 snapshot 来描述,它是最顶层树的描述,也是一个tree类型,但是使用它可以描述一个完整项目。
下面给出一个例子:
<root> (tree) //snapshot
|
+- foo (tree)
| |
| + bar.txt (blob, contents = "hello world")
|
+- baz.txt (blob, contents = "git is wonderful")
有了上面3个概念,就可以描述一个项目当前的状态了。
但是不能完成版本控制的全部内容(比如回滚版本)。
git 使用 history 来描述一个项目的历史信息。history其实是一系列相关的snapshort(即同一个项目) 有向无环图(directed acyclic graph,DAG) ,虽然但是,其实history中的每个单位是一个名为 commit 的东西,但是commit其实约等于snapshot(commit = snapshot+parent(父节点)+author(作者)+message(消息))
下图展示了一个项目的历史,每个圆圈都代表一个commit
o <-- o <-- o <-- o
^
\
--- o <-- o
至此,可以用伪代码来定义需要用到的数据模型。
// a file is a bunch of bytes
type blob = array<byte>
// a directory contains named files and directories
type tree = map<string, tree | blob>
// a commit has parents, metadata, and the top-level tree
type commit = struct {
parents: array<commit> //可以理解为父节点的指针
author: string
message: string
snapshot: tree
}
为了方便描述,git使用 object 来形容blob、tree、commit中的任意一个。为了方便索引,用SHA-1哈希算法来处理object的内容得到哈希值后,用 objects 来存储 哈希值和object的映射关系
type object = blob | tree | commit
objects = map<string, object>
def store(object):
id = sha1(object)
objects[id] = object
def load(id):
return objects[id]
可以看到,当需要往objects里放入object时,会先计算其哈希(得到id),然后建立映射关系。
当需要加载时,需要用哈希值(id)来索引真的文件内容。
但是这还是不够的,因为记住id(无规律数字)对人类极其不友好,所以为了方便记忆,git还添加了额外一层结构: references
references其实是 人类友好的名称 和 id 的映射关系。
references = map<string, string>
def update_reference(name, id):
references[name] = id
def read_reference(name):
return references[name]
def load_reference(name_or_id):
if name_or_id in references:
return load(references[name_or_id])
else:
return load(name_or_id)
有了以上基础打底,现在我们知道,Git中的”HEAD”其实指的是当前所在的commit。
那么 Git repository就大概指的是 references和objects的数据。
为了方便你debug然而不将debug的信息上传至repository,git还添加了所谓 Staging area 的说法(对比命令 git add),它的作用就是帮助你决定你想要commit的内容(例如省略debug内容,只上传普通代码)。
3. git基本操作
在学习了git的底层原理后,我们来学习一下git的基本操作
首先需要知道一些基本命令:
git config --global user.name your_name // 安装git后设置一次即可
git config --global user.email your_email //安装git后设置一次即可
//本地库操作
git init //初始化本地仓库
git add file //在缓存区添加内容
git rm file //从缓存区和工作目录删除这个文件
git rm --cached file //从缓存区删除内容,工作目录保留文件
git mv file1 file2 //移动文件,或重命名文件
git checkout -- <file> //将file 恢复到最近一次commit的状态,删除更改
git commit file_name -m "description"//将文件commit到本地库中
git commit -m "description" //将缓存区中的内容更新到本地库中,从此以后将留下历史信息无法删除
git reset --hard commit_id //版本穿梭,有--mix --soft --hard 三个选项, --hard 回溯到工作区,--mix 回退到缓存区级别,--soft 回退到本地仓库级别。
git checkout . //直接用缓存区的文件覆盖工作区
git checkout -filename //用缓存区的filename覆盖工作区的filename
//查看日志
git commit --amend //修改最近一次提交的内容
git status //查看当前仓库的状态
git reflog //查看当前仓库的简易日志
git log //查看当前仓库的日志
//分支相关
git branch //查看本地分支
git branch -r // 查看远程分支
git branch xxx //创建一个新分支
git branch -d branch_name //删除某个分支
git branch -D branch_name //强制删除
git branch -d -r branch_name //删除远程分支,branch_name为本地分支名,删除后需要git push上传远端
git checkout //xxx 切换到某个分支
//分支合并等等
git merge branch_name //把branch_name的内容合并到当前分支,但是branch_name分支保留
git rebase branch_name // 当前分支是基于branch_name提交的最新分支之上,能不用尽量不用
//远程库相关
git remote -v //查看当前远程仓库的情况
git remote add 别名 远程地址 //添加远程地址的别名
git push 别名/远程地址 本地分支:远程分支 //将本地仓库的内容推到远程中
git pull 别名/远程地址 远程分支:本地分支 //将远程仓库的内容拉取到本地仓库中,并进行合并
git fetch 别名/远程地址 远程分支:本地分支//将远程仓库的内容拉取到本地仓库中,只能拉取不同名分支到本地仓库里
git clone
开始之前
在开始之前,你需要已经安装git
并且在环境中添加下面的内容:
git global --config user.name your_name
git global --config user.email your_email
只要添加一次即可,这里的 user.name 和 user.email只在本地起作用,但不能没有(name和email随便填,假的也无所谓)
git 仓库模型
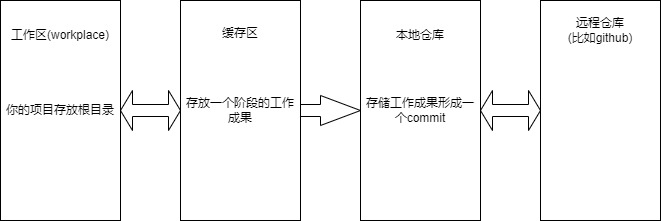
由上图可以得知,git 的仓库模型由 4个部分组成:工作区、缓存区、本地仓库、远程仓库
你在工作区添加了新的代码,你首先需要将新代码存入缓存区中,随后才能提交到本地仓库中形成一个commit,如果有必要,也可以将本地仓库推送到远程仓库中
4. git实操
git修改已commit的内容
如果你发现自己已经commit了一个或好几个内容,想要合并成一个/或者有一个commit的内容需要修改,又不想要因为这个修改额外添加一个commit,怎么办呢?
答案来了!
一、针对修改上一个commit
如果你想要添加内容,修改完后使用git add --all,如果不想的话,直接进入到下一步了
使用git commit --amend --reset-author 重新创建commit.
二、针对好几个commit的合并
首先使用git reset --soft commit_id 返回到你想要修改/合并的位置.(注意(这时候,你本地仓库的前几个commit都因为git rest –soft消失了)
如果你想要添加内容,修改完后使用git add --all,如果不想的话,直接进入到下一步了
这一步,使用git commit -m "xxx"即可
三、修改commit后提交到远程仓库
这时候就需要 git push -f强制远程仓库跟你同步了,乐