- 前言
- 15. Retrieval Augmented Generation (RAG) and Vector Databases
- 16. open-source-models
- 17. ai-agents
- 18. Fine Tuning
前言
老规矩,请看完前面的章节,anyway其实你不看也没什么大问题~
😄
15. Retrieval Augmented Generation (RAG) and Vector Databases
RAG主要解决的是LLM训练数据集老旧,且去除了大量私人数据和公司产品手册的问题
本质逻辑是把最新材料作为prompt也放入用户输入中,作为上下文提供给LLM,让其给出合理答案。
使用rag的好处如下:
-
- 信息更丰富,提供最新数据
-
- 利用经过验证的数据来减少伪造
-
- 相比fine-tune更省钱
15.1 RAG运行步骤
1. 知识库基础:
最新数据库/文档被切分成chunk,随后喂入embedding model转换为vectors。
2. 用户查询:
用户查询某个问题。
3. retrieval(检索):
用户查询问题后,这个问题会被检索,从知识库中检索出相关信息,将相关信息作为上下文和用户查询的问题结合,发送给LLM
4. LLM生成:
LLM基于检索的数据和用户的查询进行分析,得到响应并返还给用户。
Augmented Generation: the LLM enhances its response based on the data retrieved. It allows the response generated to be not only based on pre-trained data but also relevant information from the added context. The retrieved data is used to augment the LLM's responses. The LLM then returns an answer to the user's question.
根据检索到的数据的使用不同,RAG又分成了2个变体:
RAG-Sequence,RAG-Sequence 在生成答案时的步骤如下:
1. 检索阶段:首先从知识库中检索与输入查询相关的多个文档。
2. 生成阶段:基于检索到的每个文档,独立生成一个候选答案。
3. 最终答案:从所有候选答案中选择一个作为最终答案,或者通过某种集成方法(如投票)生成最终答案。
RAG-Token,RAG-Token 在生成答案时的步骤如下:
1. 检索阶段:同样地,从知识库中检索与输入查询相关的多个文档。
2. 生成阶段:与 RAG-Sequence 不同的是,RAG-Token 在生成答案时是逐词生成的。即在生成每个词时,都会考虑所有检索到的文档。
3. 最终答案:逐词生成整个答案,每个词的生成都综合考虑了检索到的所有文档的信息。
RAG-Sequence:基于每个检索文档生成多个完整答案,然后选择或集成这些答案。
RAG-Token:逐词生成答案,每个词的生成都利用了所有检索到的文档的信息。
接下来会介绍如何RAG运行步骤 1 3的思路
15.2 创建知识库(向量库)
与传统数据库不同,向量数据库是一种专门用于存储、管理和搜索embedding vector的数据库。它存储文档的数字表示。将数据分解为embeddings使我们的 AI 系统更容易理解和处理数据。
我们将embeddings存储在向量数据库中,因为 LLM 接受的token数量是有限的。由于无法将整个embeddings传递给 LLM,因此我们需要将它们分解成块chunk,当用户提出问题时,最像问题的embeddings将与提示一起返回。分块还可以降低通过LLM的token数量的成本。
一些流行的矢量数据库包括 Azure Cosmos DB、Clarifyai、Pinecone、Chromadb、ScaNN、Qdrant 和 DeepLake。
15.3 检索
检索的核心思路有4种
1. Keyword search - used for text searches
2. Semantic search - uses the semantic meaning of words
3. Vector search - converts documents from text to vector representations using embedding models.
Retrieval will be done by querying the documents whose vector representations are closest to the user question.
4. Hybrid - a combination of both keyword and vector search.
这里面的关键点在于如何衡量向量相似度,目前常用的方法有余弦相似度、欧几里得距离、点积
15.4 RAG(using langchain)
文档在这https://python.langchain.com/v0.2/docs/tutorials/rag/#built-in-chains
目前掌握如下代码:
import bs4
from langchain_community.document_loaders import WebBaseLoader
# Load the contents of the blog.
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",), # 用作知识库的网址
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
) # 用beautifulsoup的strainer来parse html文本,这里的意思是提取含有 post-content post-title post-header 类的元素的数据提取出来
),
)
docs = loader.load() # 加载数据
# print(docs[0].page_content[:500]) # 打印第0个网址的相关内容
# chunk the contents of the blog.
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=200, add_start_index=True
) # 用langchain_text_splitters中的RecursiveCharacterTextSplitter来当作文本分割器,这里每个chunk的size是1000,重叠的部分size为200(这一部分是为了能够体现块之间的上下文关联关系而设立的),add_start_index=true会把该chunk在原文中的起始位置作为metadata的一部分
all_splits = text_splitter.split_documents(docs) #执行分割
# print(len(all_splits))
# print(all_splits[0].page_content)
# print(all_splits[0].metadata)
# embed、store、index the contents of the blog.
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
from dotenv import load_dotenv
load_dotenv() # 加载环境变量,包括openai的apikey 以及 langchain的apikey
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings())# 用openAIembeddings模型来对splits做embedding
# print(vectorstore)
# retrieve
retriever = vectorstore.as_retriever(search_type="similarity",search_kwargs={"k":6}) # 用vectorstore的as_retriever方法来生成一个retriever,这里的retriever是基于相似度的,k=6表示每次检索返回6个结果
retrieved_docs = retriever.invoke("what are the approaches to Task Decomposition?")
# print(len(retrieved_docs)) # 返回检索到的文档数量
# print("-------------------")
# print(retrieved_docs)
# print("-------------------")
# print(retrieved_docs[0].metadata)
# print(retrieved_docs[0].page_content)
# print("-------------------")
# generation
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-3.5-turbo-0125") # 选择openai的模型
from langchain import hub
prompt = hub.pull("rlm/rag-prompt") # 获得一个prompt模板
# print(prompt)
# example_messages = prompt.invoke(
# {"context": "filler context", "question": "filler question"}
# ).to_messages()
# print(example_messages) # 填充模板内容
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()} # retriever | format_docs passes the question through the retriever, generating Document objects, and then to format_docs to generate strings; # RunnablePassthrough() passes through the input question unchanged.
| prompt
| llm # The last steps of the chain are llm, which runs the inference.
| StrOutputParser() # StrOutputParser(), which just plucks the string content out of the LLM's output message
)
print(rag_chain)
for chunk in rag_chain.stream("What is Task Decomposition?"):
print(chunk, end="", flush=True)
16. open-source-models
anyway,在huggingface上使用一些开源模型就对了,省钱又省事~
https://huggingface.co/chat
hugging face网页里有很多开源的模型和数据集可供使用,氪金后更能体验先进的一站式服务!可以说是ai界的github了~
17. ai-agents
AI 代理是生成式 AI 领域中一个非常令人兴奋的领域。这种兴奋有时会带来术语及其应用的混淆。为了使事情简单化并涵盖大多数涉及 AI 代理的工具,我们将使用以下定义:
人工智能代理通过让大型语言模型 (LLM) 访问状态和工具来执行任务。
其大概原理图如下:
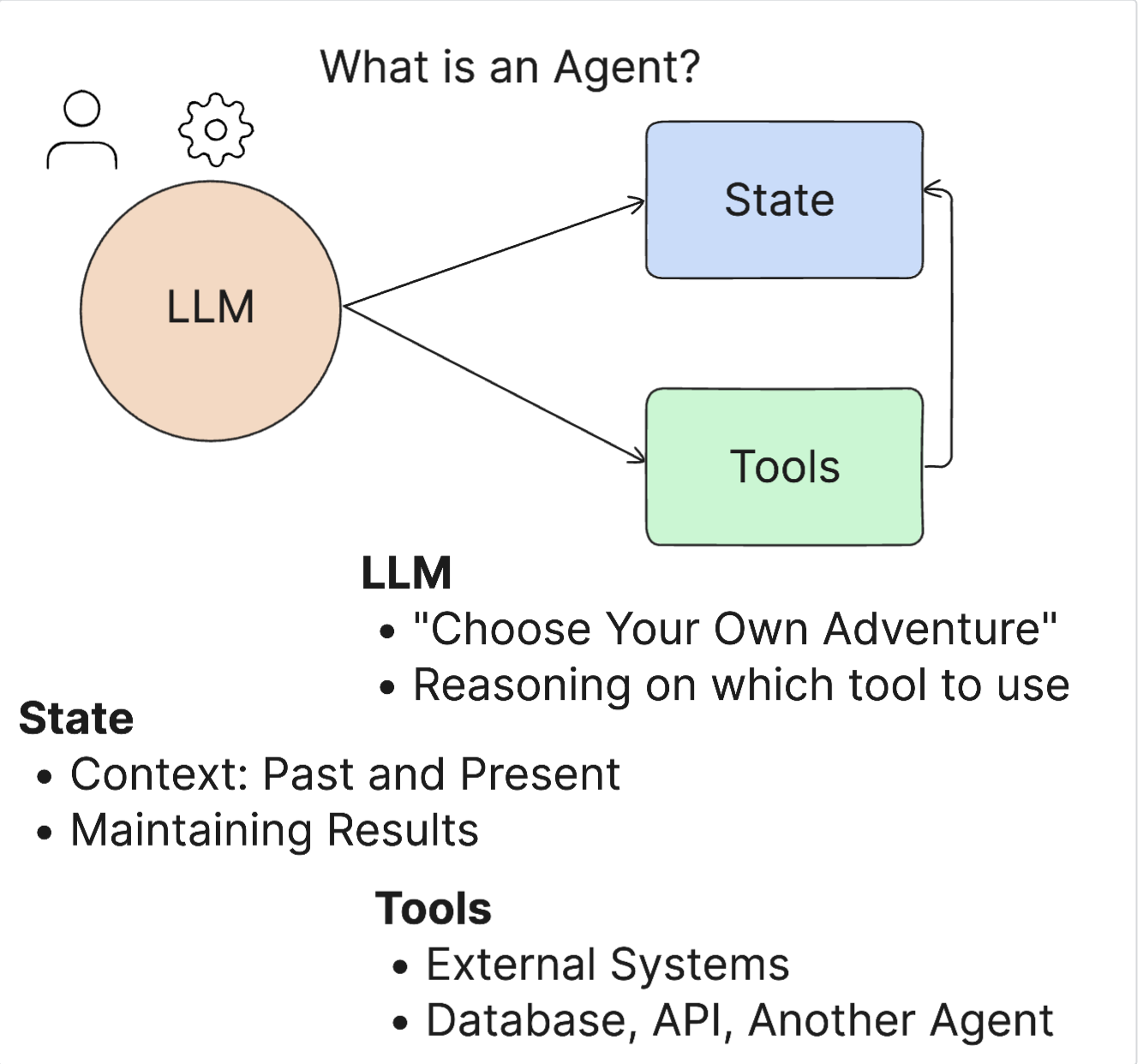 开源项目
开源项目LangChain agent就是其中之一,其工作原理如下:
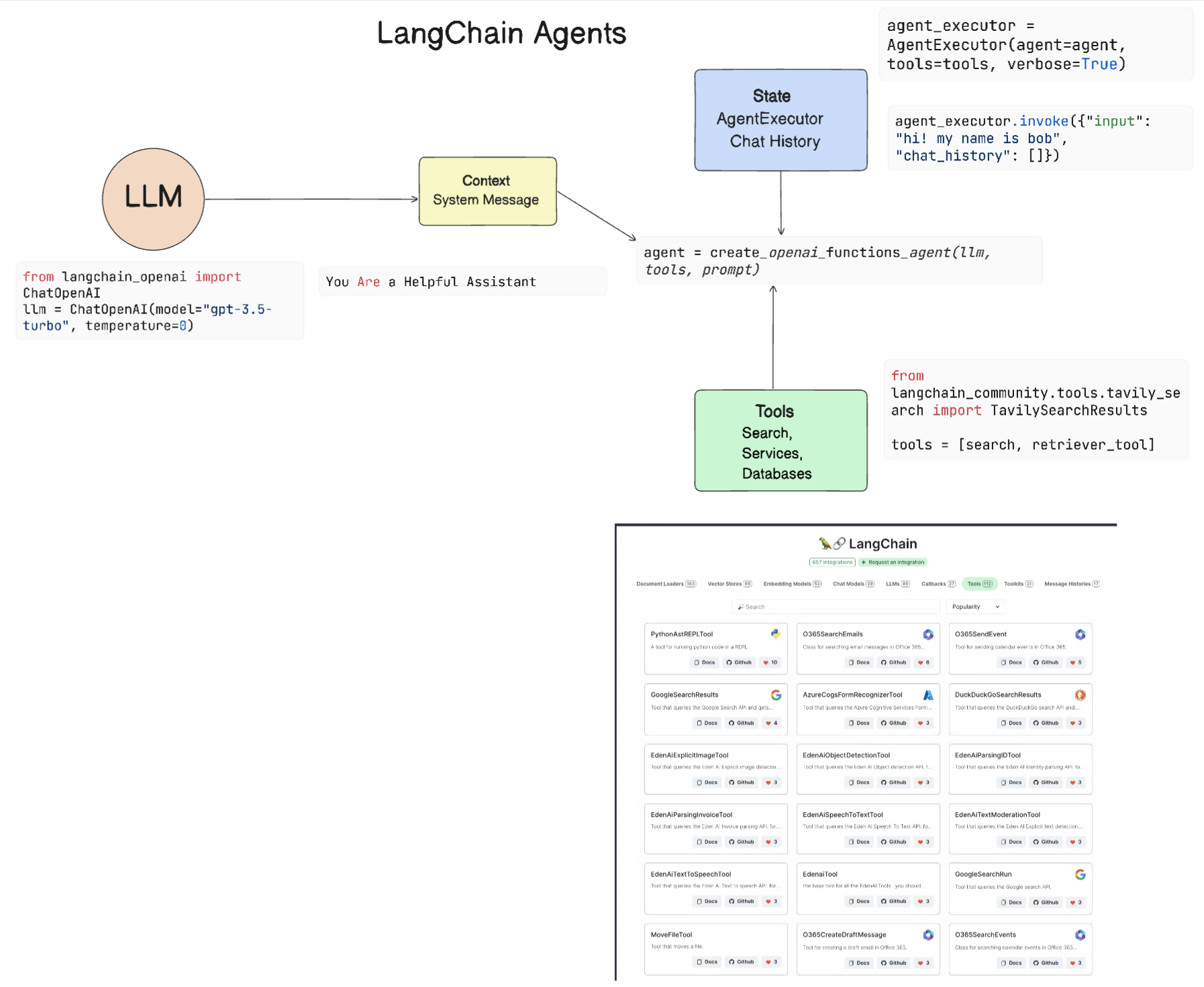
langchain agent的大致原理可以看:https://python.langchain.com/v0.2/docs/concepts/#agents
18. Fine Tuning
微调模型,即用新的数据集训练预训练好的模型,调整模型参数
在使用微调前,需要确保自己思考了如下问题:
1. 用例:微调的用例是什么? 您希望改进当前预训练模型的哪些方面?
2. 替代方案:您是否尝试过其他技术来实现预期结果?使用它们创建基线作为对照。
提示工程(prompt engineering):尝试使用诸如小样本提示之类的技术,并提供相关提示响应的示例。评估响应的质量。
检索增强生成(retrieval augmented generation):尝试使用通过搜索数据检索到的查询结果来增强提示。评估响应的质量。
3. 成本:您是否已确定微调的成本?
可调性——预先训练的模型是否可供微调?
努力——用于准备训练数据,评估和改进模型。
计算 - 用于运行微调作业并部署微调模型
数据——获取足够质量的示例以进行微调影响
4. 好处:您是否已确认微调的好处?
质量——微调模型是否优于基线?
成本——通过简化提示是否减少了token的使用?
可扩展性——您能将基础模型重新用于新的领域吗?
微调模型需要如下环境:
1. 预先训练的模型进行微调
2. 用于微调的数据集
3. 运行微调作业的训练环境
4. 部署微调模型的托管环境
体验模型微调就留待后续吧~