- 前言
- 10. Building Low Code AI Applications
- 11. Integrating with function calling
- 12. Designing UX for AI Applications
- 13. Securing Your Generative AI Applications
- 14. The Generative AI Application Lifecycle
前言
请看完前面的章节,anyway其实你不看也没什么大问题~
😄
10. Building Low Code AI Applications
目前认识的接触过所谓低代码的朋友都对它嗤之以鼻,让我来鉴定一下他的成分!
目前来看,所谓低代码,指的是让你不需要开发代码,或者使用很少的代码来构建应用程序,类似于少儿编程的那种东西,让你通过拖拽某些代表功能的积木,来搭建你想要的程序。
anyway,我感觉这好像没什么好学的,pass。
11. Integrating with function calling
11.1 Why Function Calling
用函数调用的方式来集成AI功能(anyway,已经说了很多遍了,感觉这也有点水了)。
优势如下:
Consistent response format : 一致的响应格式
如果我们可以更好的控制响应格式,我们就能够更容易的把响应集成到下游的其它系统中。
External data : 拓展的数据
可以在一个对话中,使用来自于其他来源的数据,可以解决LLM训练时数据的时间限制
11.2 Illustrating the problem through a scenario
请看示例代码:
import os
import json
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
client = OpenAI()
deployment = "gpt-3.5-turbo"
student_1_description="Emily Johnson is a sophomore majoring in computer science at Duke University. She has a 3.7 GPA. Emily is an active member of the university's Chess Club and Debate Team. She hopes to pursue a career in software engineering after graduating."
student_2_description = "Michael Lee is a sophomore majoring in computer science at Stanford University. He has a 3.8 GPA. Michael is known for his programming skills and is an active member of the university's Robotics Club. He hopes to pursue a career in artificial intelligence after finshing his studies."
prompt1 = f'''
Please extract the following information from the given text and return it as a JSON object:
name
major
school
grades
club
This is the body of text to extract the information from:
{student_1_description}
'''
prompt2 = f'''
Please extract the following information from the given text and return it as a JSON object:
name
major
school
grades
club
This is the body of text to extract the information from:
{student_2_description}
'''
response1 = client.chat.completions.create(
model=deployment,
messages=[{"role": "user", "content": prompt1}]
)
print(response1.choices[0].message.content)
response2 = client.chat.completions.create(
model=deployment,
messages=[{"role": "user", "content": prompt2}]
)
print(response2.choices[0].message.content)
结果如下:
{
"name": "Emily Johnson",
"major": "computer science",
"school": "Duke University",
"grades": 3.7,
"club": ["Chess Club", "Debate Team"]
}
{
"name": "Michael Lee",
"major": "computer science",
"school": "Stanford University",
"grades": "3.8 GPA",
"club": "Robotics Club"
}
即使prompt是相同的,描述也很类似,但是grades这个变量的值并不是一样的。
这是因为LLM以写下的prompt的方式来提取非结构化的数据,并返回非结构化的数据。所以我们需要有一个结构化的格式,以便我们知道当存储或使用数据时,会发生什么
这就是要用function calling的原因。
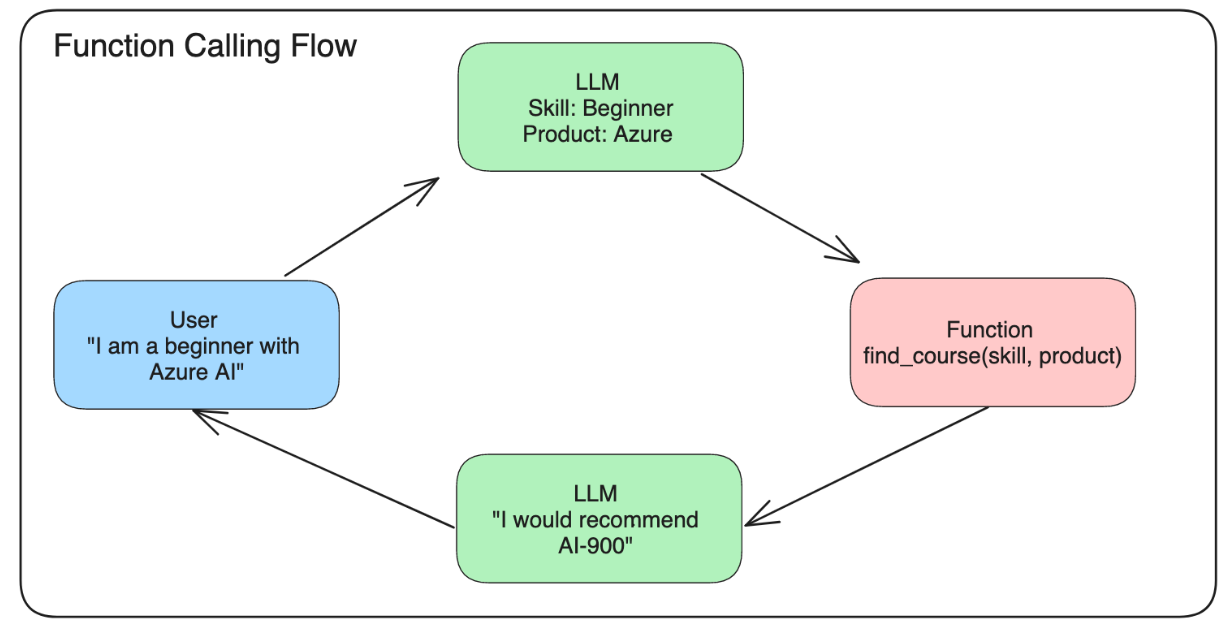
11.3 Use Cases for using function calls
总之,使用所谓的function calling还有其他好处(有时候我真的挺佩服老美的,能想这么多奇葩好处
Calling External Tools. 使用拓展工具
Chatbots are great at providing answers to questions from users. By using function calling, the chatbots can use messages from users to complete certain tasks. For example, a student can ask the chatbot to "Send email to my instructor saying I need more assistance with this subject". This can make a function call to send_email(to: string, body: string)
Create API or Database Queries. 创建API或者数据库查询
Users can find information using natural language that gets converted into a formatted query or API request. An example of this could be a teacher who requests "Who are the students that completed the last assignment" which could call a function named get_completed(student_name: string, assignment: int, current_status: string)
Creating Structured Data. 创建结构化数据
Users can take a block of text or CSV and use the LLM to extract important information from it. For example, a student can convert a Wikipedia article about peace agreements to create AI flash cards. This can be done by using a function called get_important_facts(agreement_name: string, date_signed: string, parties_involved: list)
创建function call有3个主要步骤
1、Calling the Chat Completions API with a list of your functions and a user message.
2、Reading the model's response to perform an action ie execute a function or API Call.
3、Making another call to Chat Completions API with the response from your function to use that information to create a response to the user.
如下图所示:
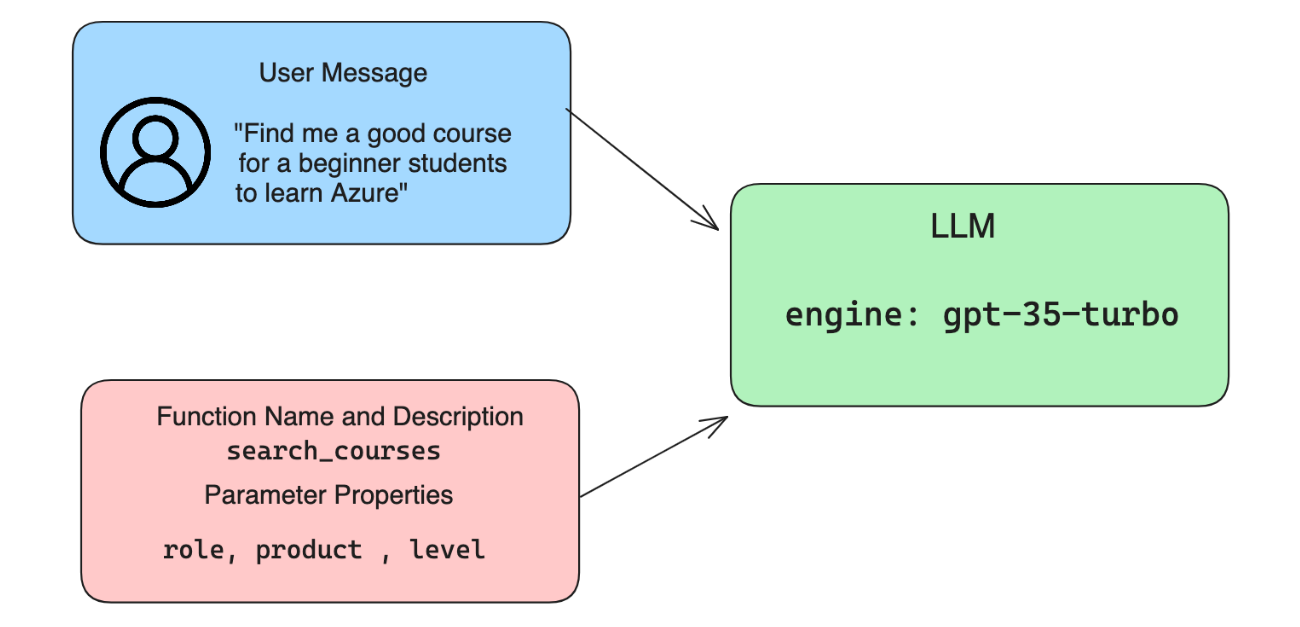 小小的举个例子:
小小的举个例子:
import os
import json
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
client = OpenAI()
deployment = "gpt-3.5-turbo"
# step 1 : creating messages
messages= [ {"role": "user", "content": "Find me a good course for a beginner student to learn Azure."} ]
# step 2 : creating functions
functions = [
{
"name":"search_courses",
"description":"Retrieves courses from the search index based on the parameters provided",
"parameters":{
"type":"object",
"properties":{
"role":{
"type":"string",
"description":"The role of the learner (i.e. developer, data scientist, student, etc.)"
},
"product":{
"type":"string",
"description":"The product that the lesson is covering (i.e. Azure, Power BI, etc.)"
},
"level":{
"type":"string",
"description":"The level of experience the learner has prior to taking the course (i.e. beginner, intermediate, advanced)"
}
},
"required":[
"role"
]
}
}
]
# step 3 : Making the function call
response = client.chat.completions.create(model=deployment,
messages=messages,
functions=functions,
function_call="auto")
print(response.choices[0].message)
个人感觉creating functions这个步骤很精髓啊
name- The name of the function that we want to have called.description- This is the description of how the function works. Here it’s important to be specific and clear.parameters- A list of values and format that you want the model to produce in its response. The parameters array consists of items where item have the following properties:type- The data type of the properties will be stored in.properties- List of the specific values that the model will use for its responsename- The key is the name of the property that the model will use in its formatted response, for example,product.type- The data type of this property, for example,string.description- Description of the specific property.
There’s also an optional property required - required property for the function call to be completed.
11.4 Integrating Function Calls into an Application
直接看实例
这个实例告诉我们如何让LLM和function call联动起来,十分高级
import os
import json
import requests
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
client = OpenAI()
deployment = "gpt-3.5-turbo"
# step 1 : creating messages
messages= [ {"role": "user", "content": "Find me a good course for a beginner student to learn Azure."} ]
# step 2 : creating functions
functions = [
{
"name":"search_courses", # 函数名称
"description":"Retrieves courses from the search index based on the parameters provided", # 函数功能描述,简介准确
"parameters":{ # 函数参数
"type":"object", # 参数的类型,为object,即字典
"properties":{ # 参数的属性有哪些,即字典中包含哪些属性
"role":{ # 属性名称
"type":"string", # 属性类型
"description":"The role of the learner (i.e. developer, data scientist, student, etc.)" # 属性描述
},
"product":{
"type":"string",
"description":"The product that the lesson is covering (i.e. Azure, Power BI, etc.)"
},
"level":{
"type":"string",
"description":"The level of experience the learner has prior to taking the course (i.e. beginner, intermediate, advanced)"
}
},
"required":[ # 必须参数,即参数中必须包含的属性名称
"role"
]
}
}
]
# step 3 : Making the function call
response = client.chat.completions.create(model=deployment,
messages=messages,
functions=functions, # 把函数描述放入这里,对于LLM来说,这就是可调用的函数列表
function_call="auto") # 让LLM决定何时调用函数
print("response_message:")
print(response.choices[0].message)
print()
response_message = response.choices[0].message
def search_courses(role, product, level): # 函数的实际实现
url = "https://learn.microsoft.com/api/catalog/" # 从目标api获取数据
params = {
"role": role,
"product": product,
"level": level
}
response = requests.get(url, params=params)
modules = response.json()["modules"]
results = []
for module in modules[:5]:
title = module["title"]
url = module["url"]
results.append({"title": title, "url": url})
return str(results)
# Check if the model wants to call a function
if response_message.function_call.name: # 这里在返回值会告诉你要调用函数
print("Recommended Function call:")
print(response_message.function_call.name) # 打印要调用的函数名称
print()
# Call the function.
function_name = response_message.function_call.name
available_functions = {
"search_courses": search_courses,
}
function_to_call = available_functions[function_name]
function_args = json.loads(response_message.function_call.arguments)
print("function_args:")
print(function_args)
print()
function_response = function_to_call(**function_args) # 实际根据函数名称,调用了真的函数,**在这里的作用是将一个字典展开为关键字参数(keyword arguments)
print("Output of function call:")
print(function_response)
print(type(function_response))
print()
# Add the assistant response and function response to the messages
messages.append( # adding assistant response to messages
{
"role": response_message.role,
"function_call": {
"name": function_name,
"arguments": response_message.function_call.arguments,
},
"content": None
}
)
messages.append( # adding function response to messages
{
"role": "function",
"name": function_name,
"content":function_response,
}
)
print("Messages in next request:")
print(messages)
print()
second_response = client.chat.completions.create(
messages=messages,
model=deployment,
function_call="auto",
functions=functions,
temperature=0
) # get a new response from GPT where it can see the function response
print(second_response.choices[0].message.content)
12. Designing UX for AI Applications
本节可以简单概述为,基于用户体验和用户需要,基于合作和反馈机制,构建可信透明的ai应用。
12.1 影响UX的因素
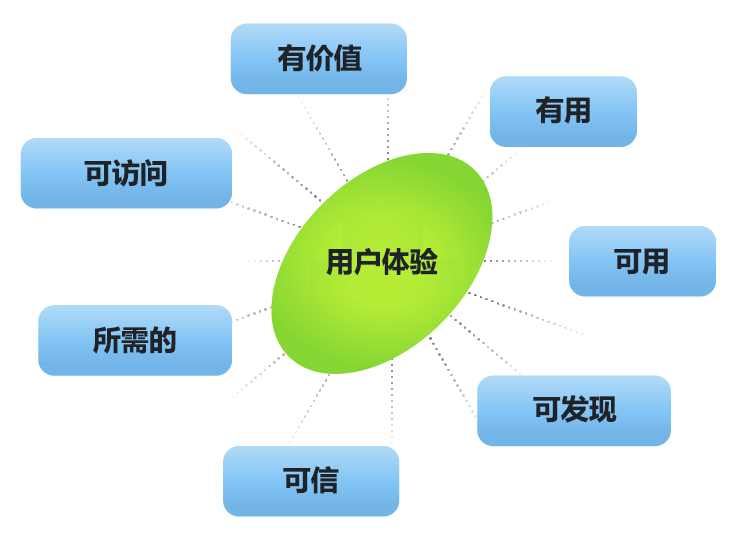
有价值(需求和市场):首要的一点是,产品必须提供价值。 在时刻考虑到价值因素的同时,你需要确认正在构建的产品确实有需求和市场,并且产品在相关市场很可能会成功。
有用(虽然主观,但必须考虑):
从用户角度看,他们关心的是“此产品有何功用?”虽然产品对用户是否有用是主观的,但你仍希望提供的产品与竞争对手的相比具有更高的重要性。
可用(用户能用):
可用性决定了用户使用产品时的有效性和高效性。 从创始人的角度看,你希望创建一个以满足用户最终目标为宗旨的解决方案。
可查找(曝光度要高):
在数字媒体和信息丰富的时代,你的产品必须要能够很容易被发现。
产品内容也必须随时可发现。 换句话说,如果用户都找不到该产品,那就更难说要购买和使用该产品了。
可信赖(信任):
无论是通过口碑、相关性还是评论,用户都希望能够确认你的产品他们不仅能用而且能有效满足其需要。
当你能够在诚实和为用户着想的基础上交付有意义的产品时,你就能赢得用户的信任。
有吸引力(魅力):
由于市场上有大量的解决方案和产品,你必须让自己的产品能够与其他产品相区分。
在设计和 UX 方面,必须要在更具辅助性的产品组成中投入时间和精力,例如品牌打造、资产和整体美学。
简单而言,你的产品越有吸引力,用户就越倾向于使用你的产品。
易于使用:
拥有完美设计的每一个产品都应能提供能满足各界人士的体验。
你不希望忽视用户体验中的辅助功能。
UX 术语中的辅助功能意味着用户体验能够适合不同能力(包括但不限于残障人士)的用户。
13. Securing Your Generative AI Applications
就是ai的安全性很重要,核心的思考点有3个:
1. Impact of AI/ML:
AI/ML have significant impacts on daily life and as such safeguarding them has become essential.
2. Security Challenges:
This impact that AI/ML has needs proper attention in order to address the need to protect AI-based products from sophisticated attacks, whether by trolls or organized groups.
3. Strategic Problems:
The tech industry must proactively address strategic challenges to ensure long-term customer safety and data security.
13.1 Understanding the threats and risks of AI
接下来具体AI有哪些威胁和风险:
1. Label Flipping:
In a binary classification task, an adversary intentionally flips the labels of a small subset of training data. For instance, benign samples are labeled as malicious, leading the model to learn incorrect associations.
Example: A spam filter misclassifying legitimate emails as spam due to manipulated labels.
2. Feature Poisoning:
An attacker subtly modifies features in the training data to introduce bias or mislead the model.
Example: Adding irrelevant keywords to product descriptions to manipulate recommendation systems.
3. Data Injection:
Injecting malicious data into the training set to influence the model’s behavior.
Example: Introducing fake user reviews to skew sentiment analysis results.
4. Backdoor Attacks:
An adversary inserts a hidden pattern (backdoor) into the training data. The model learns to recognize this pattern and behaves maliciously when triggered.
Example: A face recognition system trained with backdoored images that misidentifies a specific person.
其实整了半天,都只是对训练数据集做手脚,区别在于对训练集哪部分数据做手脚罢了
另外The MITRE Corporation基于ATT&CK做了AI攻击模式库 ATLAS这个链接里降了AI的全部风险…
另外,OWASP把Prompt Injection、Supply Chain Vulnerabilities、Overreliance列为AI的重要风险
13.2 LLMS和AI systems的安全测试
涵盖重要的测试方法:
1. Data sanitization:
这是从训练数据或 AI 系统或 LLM 的输入中删除或匿名化敏感或私人信息的过程。数据清理可以通过减少机密或个人数据的暴露来帮助防止数据泄露和恶意操纵。
2. Adversarial testing:
这是生成对抗性示例并将其应用于 AI 系统或 LLM 的输入或输出的过程,以评估其对对抗性攻击的稳健性和弹性。对抗性测试可以帮助识别和减轻可能被攻击者利用的 AI 系统或 LLM 的漏洞和弱点。
3. Model verification:
这是验证 AI 系统或 LLM 的模型参数或架构的正确性和完整性的过程。模型验证可以通过确保模型受到保护和认证来帮助检测和防止模型窃取。
4. Output validation:
这是验证 AI 系统或 LLM 输出质量和可靠性的过程。输出验证可通过确保输出一致且准确来帮助检测和纠正恶意操纵。
5. Emulating real-world threats - AI red teaming:
通过使用类似的工具、策略和程序来识别系统风险并测试防御者的反应,模拟现实世界的威胁现在被认为是构建弹性人工智能系统的标准做法。
https://github.com/openai/evals/tree/main这个网址里还有openai提供的用于验证模型安全性的数据集~
13.3 LLMS和AI systems的保护要点
1. 模型和算法
2. ai安全:即模型的偏见、歧视、道德问题要少;决策时的可问责性、透明度和可解释性要高
3、用户隐私数据
14. The Generative AI Application Lifecycle
个人感觉没用,pass