- 3. 负责任得使用AI
- 4. Prompt Engineering基础
- 5. Advanced Prompt
- 6. text-generation-apps
- 7. building-chat-applications
3. 负责任得使用AI
3.1 为什么应该优先考虑负责任的AI功能
ai有时候会吐出一些奇奇怪怪的输出。
1. hallucinations(幻觉):简而言之就是吐出的答案是没有意义的,或者就是错的
2. Harmful Content: 吐出的答案是有害的,比如18禁,毒药,etc
3. Lack of Fairness:吐出的内容涉及种族歧视等等
为了保护世界的和平,为了保护……,ai安全势在必行!
3.2 如何考虑负责任的AI
总的来说四步走:识别ai风险->衡量ai风险->提出缓解措施->运行 接下来就是不断地迭代~
3.2.1 衡量ai风险的方法
anyway,就是我是用户我会怎么输入,先测试一轮。
3.2.2 缓解措施的分层
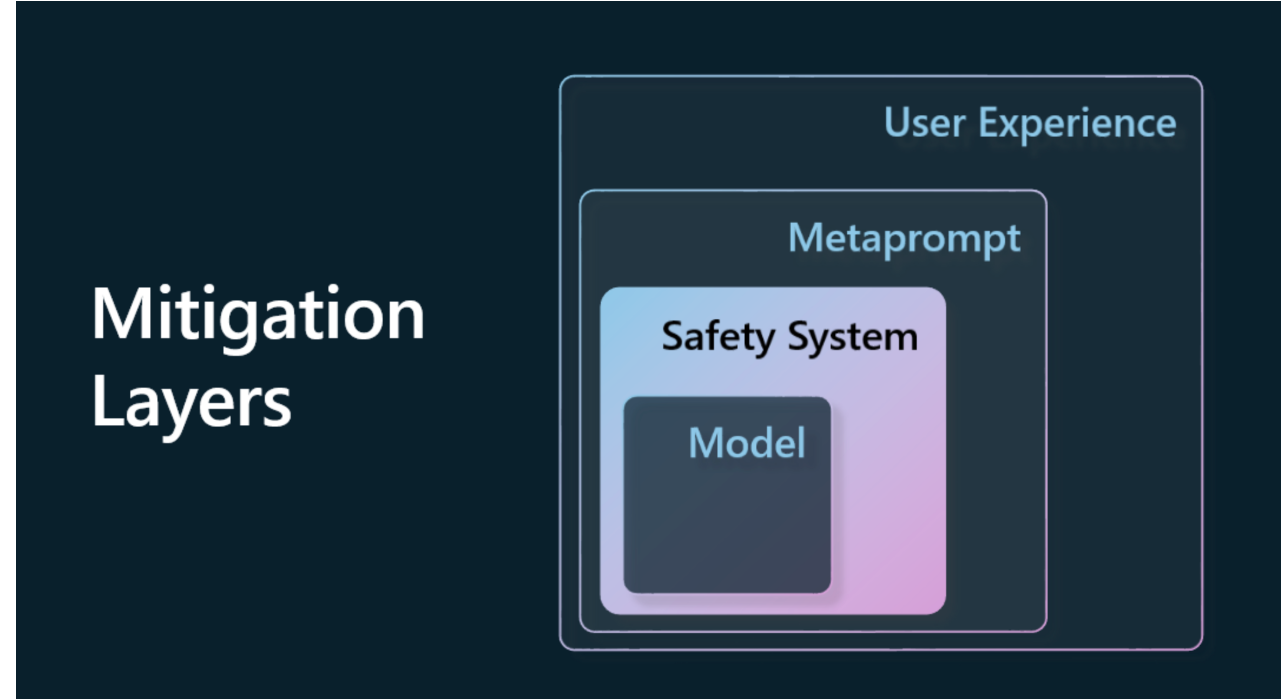
1. model层指的就是对模型进行微调,增加一些安全限制
2. Safety System层指的是一些文本过滤器等等功能
3. meta prompt指的就是在用户输入前在加点prompt
4. User Experience指的就是在用户的ui这里限制一下用户的输入,不要做些非法行为(这个破解也太简单了)
4. Prompt Engineering基础
这节会教大伙如何更好的使用prompt技术从llm那取得更好的效果。(即答得更准确,更有用)
4.1 什么是Prompt Engineering
we define Prompt Engineering as the process of designing and optimizing text inputs (prompts) to deliver consistent and quality responses (completions) for a given application objective and model
Prompt Engineering分为2个步骤:
1. 为给定模型和目标设计初始prompt
2. 迭代完善prompt 以提高响应质量
为了理解这两个步骤,有三个概念需要理解
Tokenization = 模型如何看到 prompt
Base LLMs = 模型如何处理 prompt
Instruction-Tuned LLMs = 模型如何看到任务
4.1.2 Tokenization
Tokenization指的是模型如何把我们输入的prompt分成不同的部分Token
https://platform.openai.com/tokenizer?WT.mc_id=academic-105485-koreyst
这个网址可以看到想要的token
4.1.3 Base LLM
就是用来预测你输入序列的下一个可能值,基石模型
4.1.4 Instruction Tuned LLMs
顾名思义,就是用指令微调后的大模型,相比于基石模型,在特定领域的回答会更精确。
4.2 为什么需要Prompt Engineering
- 模型的响应是随机的,同模型不同版本,不同的模型之间,对同一个问题的答案不完全相同(当然,你也可以通过设置让它们相同,但是这就没有意义了)
- 模型会捏造响应(模型的响应基于已有训练集,对于没有训练集训练的知识,模型通常会捏造出不真实的响应)
- 模型的功能不同(不同版本的模型会出于性能和花费的考虑做出不同的裁剪)
总之就是想要用prompt engineering提高回答的精度。
4.3 Prompt Construction
4.3.1 Basic Prompt
就是没有任何使用方法,上来就直接问,比如:
唱一首中国国歌
4.3.2 Complex Prompt
以OPENAI API为例,其提供了更复杂的机制帮助我们来使用Prompt
给出一个例子:
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "你是一名强大的人工智能专家,博古通今"},
{"role": "user", "content": "谁赢得了2022年世界杯冠军?"},
{"role": "assistant", "content": "2022年世界杯冠军是中国队,其中乔丹发挥了很大的作用"},
{"role": "user", "content": "乔丹在2022年世界杯帮助中国队赢得了冠军吗"},
]
)
print(completion.choices)
这是使用OpenAI 的python库和API来进行的对话,发送消息的格式如上
其中:
| role | name |
|---|---|
| system | 通常是用来为模型设置某些初始设定 |
| user | 来自用户的提问 |
| assistant | 模型的回答 |
发送的信息其实相当于历史对话,即你之前对模型做出的设定,做了一些题目和回答,以及模型的回复。
当然了,这也表明你可以伪造模型的回复,这有好有坏,如果使用不当,说不定可以骗到模型意想不到的回答;使用得当,有效的回复会帮助你更有效的得到接下来提问的结果
4.3.3 Instruction Prompt
我们可以通过更详细的制定提问,来提高模型的回答准确性。
| Prompt (Input) | Completion (Output) | Instruction Type |
|---|---|---|
| 如何做一个优秀的人 | 返回一段话 | Simple |
| 如何做一个优秀的人,给出关键点和训练方法 | 返回一段话,带有关键点和训练方法 | Complex |
| 如何做一个优秀的人,提供3个关键点和它的解释,并给出每个关键点至少3个训练方法 | 返回一段话,带有3个关键点和每个关键点的至少3个训练方法 | Complex 和 formatted |
4.3.4 Primary Content
字面意思是通过将Prompt分成2部分:指令和会影响指令回应的相关内容:
Examples - 就是举个例子来让模型推断做什么
Cues - 就是说一大段话,然后最后来一句cue:总结一下这句话,
Templates - 提前定义好的Prompt,可以拿来即用
4.3.5 Supporting Content
以某种形式影响LLM输出的内容被叫做Supporting Content,它可以是调整参数,格式化输出,主题分类等等
4.3.4 总结
其实prompt = instruction + Primary Content + Supporting Content
不一定全要加,用就完事了。
给个用上的例子:
from openai import OpenAI
from dotenv import load_dotenv
load_dotenv()
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a sarcastic assistant."}, # 背景设定,算作complex的一环
{"role": "user", "content": "请用诙谐的、嘲讽的风格来回答问题,每个问题回答一个词语即可"}, # instruction
{"role": "user", "content": "xxx => 傻子"}, # primary_content: example
{"role": "user", "content": "otto => 小丑"},# primary_content: example
{"role": "user", "content": "请回答下列的问题"},# primary_content: cue
{"role": "user", "content": "中国队 => "},
]
)
print(completion.choices)
# [Choice(finish_reason='stop', index=0, logprobs=None, message=ChatCompletionMessage(content='得意', role='assistant', function_call=None, tool_calls=None))]
5. Advanced Prompt
第四节的Prompt只是小case,现在开始上强度教你用各种各样有趣的办法来提高prompt水平喽
5.1 basic prompt的缺陷
比如问题:Generate 10 questions on geography.
看起来很大,却有2个大问题:
1. 话题太大,地理相关内容可太多了
2. 格式问题,它不知道以何种格式输出
5.2 Advanced Prompt技巧
1. Zero-shot prompting
this is the most basic form of prompting. It's a single prompt requesting a response from the LLM based solely on its training data.
2. Few-shot prompting
this type of prompting guides the LLM by providing 1 or more examples it can rely on to generate its response.
3. Chain-of-thought
this type of prompting tells the LLM how to break down a problem into steps.
4. Generated knowledge
to improve the response of a prompt, you can provide generated facts or knowledge additionally to your prompt.
5. Least to most
like chain-of-thought, this technique is about breaking down a problem into a series of steps and then ask these steps to be performed in order.
6. Self-refine
this technique is about critiquing the LLM's output and then asking it to improve.
7. Maieutic prompting
What you want here is to ensure the LLM answer is correct and you ask it to explain various parts of the answer. This is a form of self-refine.
emm,其实对于prompt的技术分类也不是很明确就是了,你一定要说的话,我觉得Chain of Thought其实也算few-shot的一种,Chain of Thought和 Least to most好像有差不多,都是在提供LLM分析问题/解决问题的例子
anyway,用就完事了~
5.3 Using temperature to vary your output
PS: 在api中,可以通过temperature参数来确定答案的随机程度,从0到1,随机性越强
6. text-generation-apps
开始实操一下,其实和之前写得代码差不太多
from openai import OpenAI
import os
import dotenv
# import dotenv
dotenv.load_dotenv()
# configure OpenAI service client
client = OpenAI()
#deployment=os.environ['OPENAI_DEPLOYMENT']
deployment="gpt-3.5-turbo"
# add your completion code
no_recipes = input("No of recipes (for example, 5: ")
ingredients = input("List of ingredients (for example, chicken, potatoes, and carrots: ")
filter = input("Filter (for example, vegetarian, vegan, or gluten-free: ")
prompt = f"Show me {no_recipes} recipes for a dish with the following ingredients: {ingredients}. Per recipe, list all the ingredients used, no {filter}"
messages = [{"role": "user", "content": prompt}]
# make completion
completion = client.chat.completions.create(model=deployment, messages=messages)
# print response
print(completion.choices[0].message.content)
old_prompt_result = completion.choices[0].message.content
prompt = "Produce a shopping list for the generated recipes and please don't include ingredients that I already have."
new_prompt = f"{old_prompt_result} {prompt}"
messages = [{"role": "user", "content": new_prompt}]
completion = client.chat.completions.create(model=deployment, messages=messages, max_tokens=1200,temperature=0.5)
# print response
print("Shopping list:")
print(completion.choices[0].message.content)
7. building-chat-applications
为了构建一个好用的chat application,首先需要回答如下2个问题:
1. 构建app: 我们如何针对特定用例高效构建和无缝集成这些人工智能驱动的应用程序?
2. 监控: 部署后,我们如何监控并确保应用程序在功能方面和遵守负责任人工智能的六项原则,能够以最高质量水平运行?
7.1 Integrating Generative AI into Chat Applications
我们首先需要了解chatbot和Generative AI-Powered Chat Application的区别:
| Chatbot | Generative AI-Powered Chat Application |
|---|---|
| 专注于任务,基于规则 | 上下文感知 |
| 通常集成在一个大系统中 | 可以持有一个或多个chatbots |
| 限制于编程功能 | 包含generative ai models |
| 专业且结构化的交互 | 能够进行开放领域的讨论 |
总之就是各种吹Generative AI集成的聊天应用啦
为了更方便的开发ai应用程序,使用现成的先进SDKs and APIs是很重要的,好处如下:
1. Expedites the development process and reduces overhead:
加速开发步骤并减少开销,很直观的原因,让你专注于逻辑
2. Better performance:
不用考虑程序的可拓展性或者突发的用户浏览徒增的问题,SDK和API已经提供了现成的解决方案
3. Easier maintenance:
更新只需要更换library即可
4. Access to cutting edge technology:
利用在广泛的数据集上经过微调和训练的模型,为您的应用程序提供自然语言功能
7.2 User Experience (UX)
用户体验是很重要的!
一般用户体验原则适用于聊天应用程序,但由于涉及机器学习组件,这里有一些额外的考虑因素变得特别重要。
解决歧义的机制:
生成式人工智能模型有时会生成歧义的答案。如果用户遇到此问题,允许用户要求澄清的功能可能会有所帮助。
上下文保留:
先进的生成式人工智能模型能够记住对话中的上下文,这可能是用户体验的必要资产。赋予用户控制和管理上下文的能力可以改善用户体验,但会带来保留敏感用户信息的风险。考虑这些信息的存储时间(例如引入保留策略)可以平衡上下文需求和隐私。
个性化:
人工智能模型具有学习和适应能力,为用户提供个性化体验。通过用户个人资料等功能定制用户体验,不仅让用户感到被理解,而且还有助于他们寻求特定答案,创造更高效、更令人满意的交互。
7.3 Customization
Customization,定制化,目前有两种方法来为特定应用做定制:
Using a DSL:
DSL stands for domain specific language.
You can leverage a so called DSL model trained on a specific domain to understand it's concepts and scenarios.
Apply fine-tuning:
Fine-tuning is the process of further training your model with specific data.
7.4 Considerations for a High Quality AI-Driven Chat Experience
思考高质量的ai驱动的聊天体验的关键衡量标准
| Metric | Definition | Considerations for Chat Developer |
|---|---|---|
| Uptime | Measures the time the application is operational and accessible by users. | How will you minimize downtime? |
| Response Time | The time taken by the application to reply to a user’s query. | How can you optimize query processing to improve response time? |
| Precision | The ratio of true positive predictions to the total number of positive predictions | How will you validate the precision of your model? |
| Recall (Sensitivity) | The ratio of true positive predictions to the actual number of positives | How will you measure and improve recall? |
| F1 Score | The harmonic mean of precision and recall, that balances the trade-off between both. | What is your target F1 Score? How will you balance precision and recall? |
| Perplexity | Measures how well the probability distribution predicted by the model aligns with the actual distribution of the data. | How will you minimize perplexity? |
| User Satisfaction Metrics | Measures the user’s perception of the application. Often captured through surveys. | How often will you collect user feedback? How will you adapt based on it? |
| Error Rate | The rate at which the model makes mistakes in understanding or output. | What strategies do you have in place to reduce error rates? |
| Retraining Cycles | The frequency with which the model is updated to incorporate new data and insights. | How often will you retrain the model? What triggers a retraining cycle? |
| Anomaly Detection | Tools and techniques for identifying unusual patterns that do not conform to expected behavior. | How will you respond to anomalies? |
7.5 Implementing Responsible AI Practices in Chat Applications
衡量负责任的AI的评价标准
| Principles | Microsoft’s Definition | Considerations for Chat Developer | Why It’s Important |
|---|---|---|---|
| Fairness | AI systems should treat all people fairly. | Ensure the chat application does not discriminate based on user data. | To build trust and inclusivity among users; avoids legal ramifications. |
| Reliability and Safety | AI systems should perform reliably and safely. | Implement testing and fail-safes to minimize errors and risks. | Ensures user satisfaction and prevents potential harm. |
| Privacy and Security | AI systems should be secure and respect privacy. | Implement strong encryption and data protection measures. | To safeguard sensitive user data and comply with privacy laws. |
| Inclusiveness | AI systems should empower everyone and engage people. | Design UI/UX that is accessible and easy-to-use for diverse audiences. | Ensures a wider range of people can use the application effectively. |
| Transparency | AI systems should be understandable. | Provide clear documentation and reasoning for AI responses. | Users are more likely to trust a system if they can understand how decisions are made. |
| Accountability | People should be accountable for AI systems. | Establish a clear process for auditing and improving AI decisions. | Enables ongoing improvement and corrective measures in case of mistakes. |