前言
学习一下generative ai的课程,课程来自
https://github.com/microsoft/generative-ai-for-beginners
PS:学习该课程属于是最近没事干了,又听闻AI的风声,蛮学着玩玩
0. 环境搭建
第0节环境搭建大家可自行参考文档,写得很详细,甚至可以直接使用github提供的codespace功能一步到位,这里附上我申请open AI api的方法
0.1 申请API key
https://platform.openai.com/api-keys
中创建 API key
当然,最重要的充值是不能忘记的
0.2 安装python环境
pip install openai
pip install python-dotenv
0.3 设置api key进行开发
首先在.gitignore中写入一行.env,随后在你的工作区域下创建.env文件,其中写入你申请到的api key
# Once you add your API key below, make sure to not share it with anyone! The API key should remain private.
OPENAI_API_KEY=sk-xxxx
然后再写代码
from openai import OpenAI
from dotenv import load_dotenv
# 将.env中的变量加载
load_dotenv()
client = OpenAI()
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a poetic assistant, skilled in explaining complex programming concepts with creative flair."},
{"role": "user", "content": "Compose a poem that explains the concept of recursion in programming."}
]
)
print(completion.choices[0].message)
1. generative ai 和 LLM的简单介绍
1.1 历史
ai的历史是比较久远的,人工智能的第一个原型由打字的聊天机器人组成,依赖于从一组专家中提取并表示到计算机中的知识库。知识库中的答案是由输入文本中出现的关键字触发的。然而,很快人们就发现,这种使用打字聊天机器人的方法并不能很好地扩展。
20世纪90年代出现了机器学习:能够从数据中学习模式,而无需显式编程。这种方法允许机器模拟人类语言理解:在文本标签配对上训练统计模型,使模型能够使用代表消息意图的预定义标签对未知输入文本进行分类。
近年来硬件发展迅速,又有了新的ai算法:神经网络
神经网络(特别是循环神经网络 - RNN)显着增强了自然语言处理,能够以更有意义的方式表示文本含义,并重视句子中单词的上下文。
又经过了数十年的研究:一种名为Transformer 的新模型架构克服了 RNN 的限制,能够获得更长的文本序列作为输入。Transformer 基于注意力机制,使模型能够为其接收到的输入赋予不同的权重,“更加关注”最相关的信息集中的地方,而不管它们在文本序列中的顺序如何,最近的LLM也是基于这种架构
1.2 LLM如何运作
输入是人类语言文本
首先经过tokenizer:将人类语言文本分成若干个token,每个token是可变数量的字符组成的文本块,再把不同的token通过某种计算方式转换成数字
其次经过Predicting output tokens步骤,给定n个token作为输入,预测最有可能出现的下一个token,预测出来后,把(n+1)个token作为输入,预测下一个可能出现的token,不断迭代
最后经过Selection process, probability distribution步骤,模型会计算下一个token出现各个不同单词的概率,选择概率最大的那一个作为结果(然而并不总是选概率最大的,通过添加一定程度的随机性,让每次生成的输出都不一样)
LLM 是不确定性的,响应会有所不同,但是您可以通过参数设置来控制其方差。你也不应该期望它能完美地完成事情,它是来为你做繁重的工作的,这通常意味着你在需要逐渐改进的事情上得到了良好的第一次尝试。
2. 探索并比较不同的LLM
本次目标为:
1、了解当前不同类型的LLM ——> 知道如何选用合适的模型
2、测试、迭代、比较不同类型的模型(Azure) ——> 理解如何测试、迭代、提升LLM性能
3、如何部署LLM ——> 知道如何在商业中部署模型
2.1 不同种类的LLM
根据用途大致分为四类:
1. Audio and speech recognition: 即语音和音频识别, 这里的出名模型是 Whisper-type models
2. Image generation: 即图像生成,有DALL-E和Midjourney
3. Text generation: 即文本生成,从GPT-3.5 到 GPT-4.
4. vedio generation: 即视频生成,让我期待一首Sora吧!
2.2 Foundation Model
Foundation Model的定义如下:
1. 使用无监督学习或自监督学习
它们使用无监督学习或自监督学习进行训练,这意味着它们是在未标记的多模态数据上进行训练的,并且它们的训练过程不需要人工注释或数据标记。
2. 它们是非常大的模型
基于经过数十亿参数训练的非常深的神经网络。
3. 它们通常旨在作为其他模型的“基础”
这意味着它们可以用作构建其他模型的起点,这可以通过微调来完成。
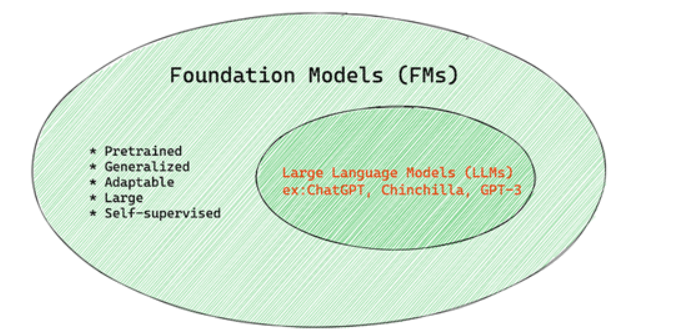 图来源于
图来源于2.3 开源模型和私有模型
开源模型,顾名思义,即免费,任何人都可以使用的模型,这些模型可以被修改、观察和定制,然而性能上很难跟私有模型媲美
常见的开源模型有Alpaca, Bloom , LLaMA
私有模型虽然不能被定制,又要花钱,但是性能和通用性往往比较强,例如 OpenAI models, Google Bard , Claude 2
2.4 Embedding、Image generation、Text and Code generation
根据LLM的输出,可以分为大致3种:
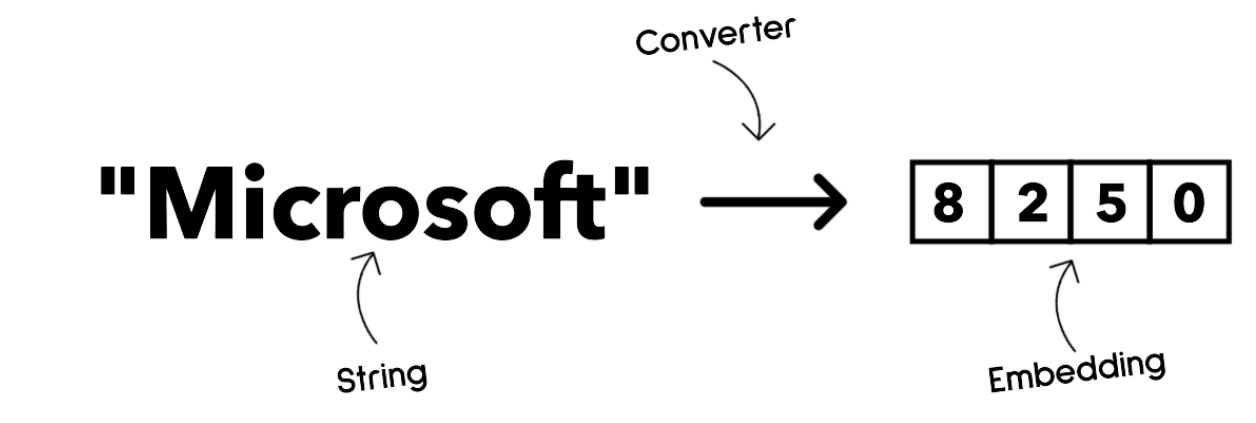
1. embedding: 说白话就是把文本转换为数字
好处是让机器更容易理解词和句子之间的关联
输出的内容还可以作为其他模型的输入,例如分类模型,聚类模型(无监督学习的一种,根据数据相关性将数据分成不同簇)
例子: OpenAI embeddings
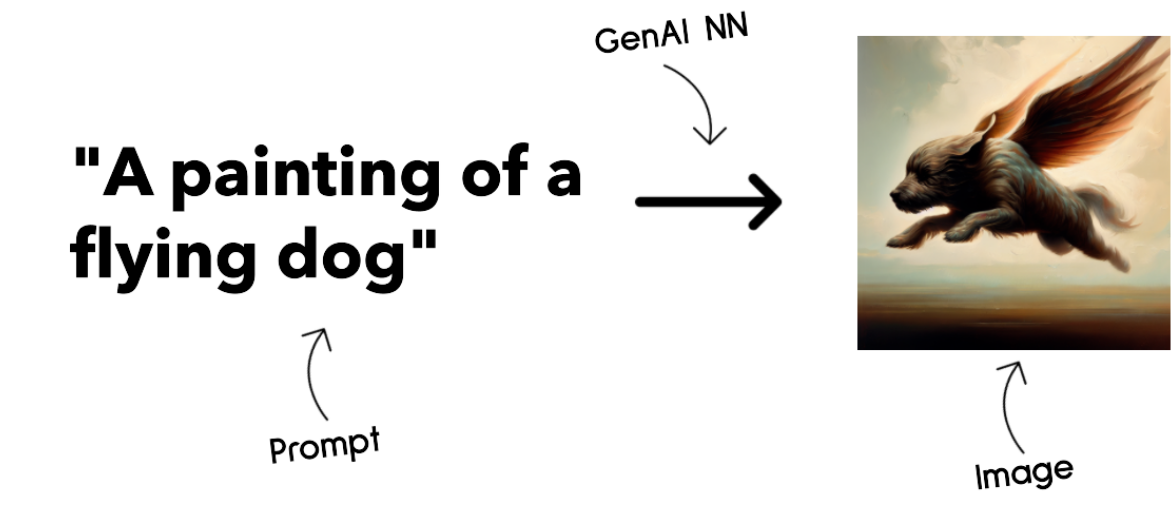
2. Image generation:输出就是图像啦
通常被用于图像编辑、合成、翻译
一般基于 LAION-5B 的图像数据集进行训练
可以被用来生成新图像,或者对已有图像进行修复、提高分辨率、着色 等等
例子: DALL-E-3 Stable Diffusion models
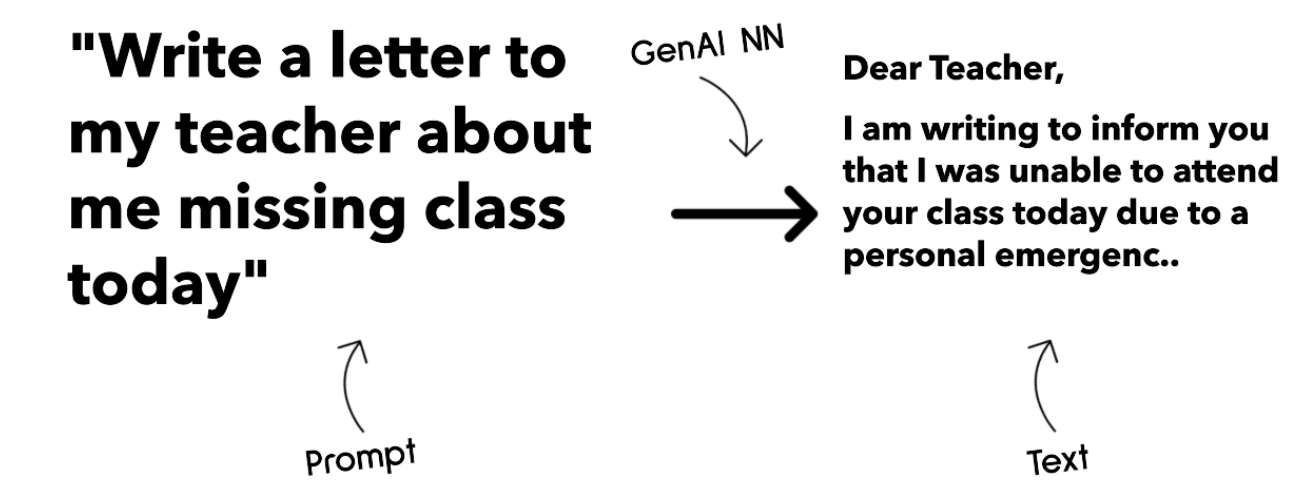
3. Text and Code generation: 就是生成文本和代码的模型
通常用于文本总结、翻译,以及回答问题
文本模型 通常基于 BookCorpus 这种数据集进行训练
被使用来生成新的文本、回答问题
代码生成模型通常,像 CodeParrot 通常基于github里的代码训练
可以被使用生成代码,或改善代码
2.5 Encoder Decoder
Decoder: GPT-3
善于创造内容丰富的文本内容
不擅长理解和学习目标
Encoder: BERT
善于理解和学习目标
不擅长创造内容
Encoder-Decoder : Bard T5
两者结合一下
2.6 服务和模型之间的关系
模型(model)指的是一个服务的核心组件
服务(service)包括模型、数据、其他相关功能(例如用户界面),由云厂商提供相关功能,比如 Azure OpenAI service
2.7 在Azure上测试、迭代不同的模型,理解性能
(感觉有点打广告的嫌疑
首先是针对使用场景选择合适的模型候选
下一步就是用自己的数据来进行测试以及确认工作负载。(迭代过程,靠实验和测量来找到最合适的)
以Azure为例,选择模型来玩需要经过好几个步骤:
Find the Foundation Model of interest in the catalog, filtering by task, license, or name. It’s also possible to import new models that are not yet included in the catalog.
Review the model card, including a detailed description and code samples, and test it with the Sample Inference widget, by providing a sample prompt to test the result.
Evaluate model performance with objective evaluation metrics on a specific workload and a specific set of data provided in input.
Fine-tune the model on custom training data to improve model performance in a specific workload, leveraging the experimentation and tracking capabilities of Azure Machine Learning.
Deploy the original pre-trained model or the fine-tuned version to a remote real time inference or batch endpoint, to enable applications to consume it.
2.8 改善LLM的性能
目前给出4个方法:
1. Prompt engineering with context
就是你说话给的条件要细,描述详细场景,给LLM足够信息做推理
总之就是能够有条理的描述你的需求,还能给出例子,LLM的回答往往越贴近你的期望,算是高性价比
2. Retrieval Augmented Generation, RAG
说人话就是,外部提供一个数据库(包含你自己的信息),在提问的时候把数据库的某些信息作为提示输入。
因为大模型只知道用来训练的数据,不知道之后发生的事件的数据,也不知道保密信息
通过外置一个向量数据库,把信息作为prompt也带入文本
3. Fine-tuned model
动动自己的小手用自己的数据在微调一波模型吧~
微调一下让模型能力更差,但是速度更快,更有性价比
为了延迟问题,可能限制输入的prompt的数量来加快输出
利用企业的数据保持模型最新状态
4. 从头训练模型
难度极大,需要某个特定领域的大量数据、极强的训练手法、充足的运算资源
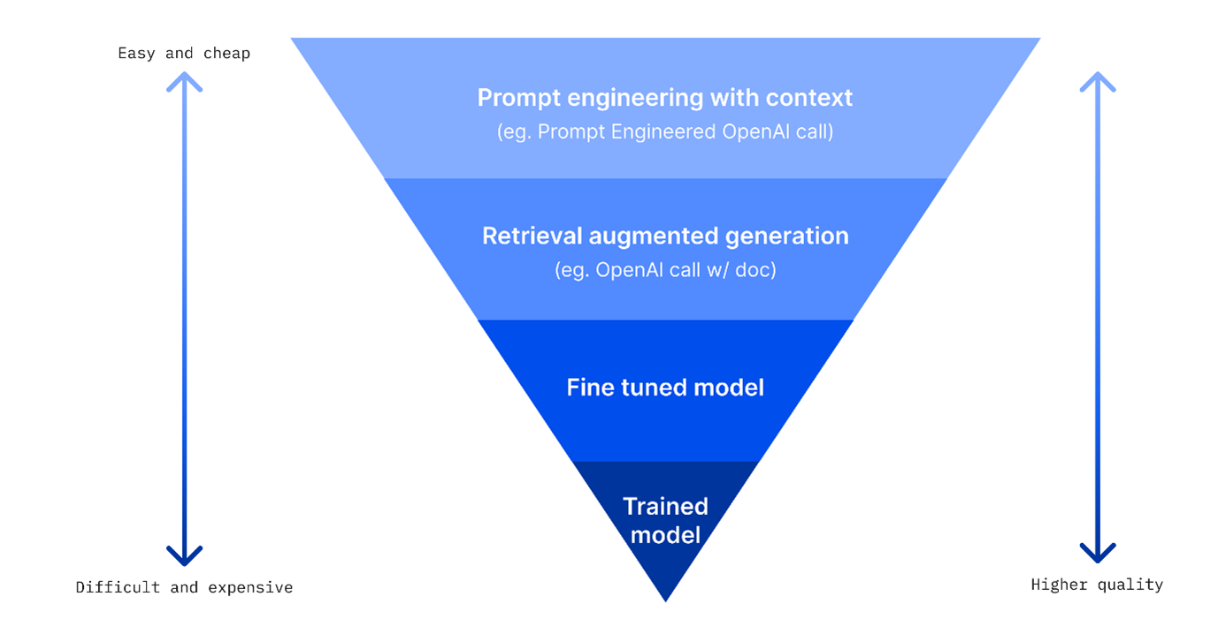 来源:https://www.fiddler.ai/blog/four-ways-that-enterprises-deploy-llms?WT.mc_id=academic-105485-koreyst
来源:https://www.fiddler.ai/blog/four-ways-that-enterprises-deploy-llms?WT.mc_id=academic-105485-koreyst