Supervised vs Self-supervised
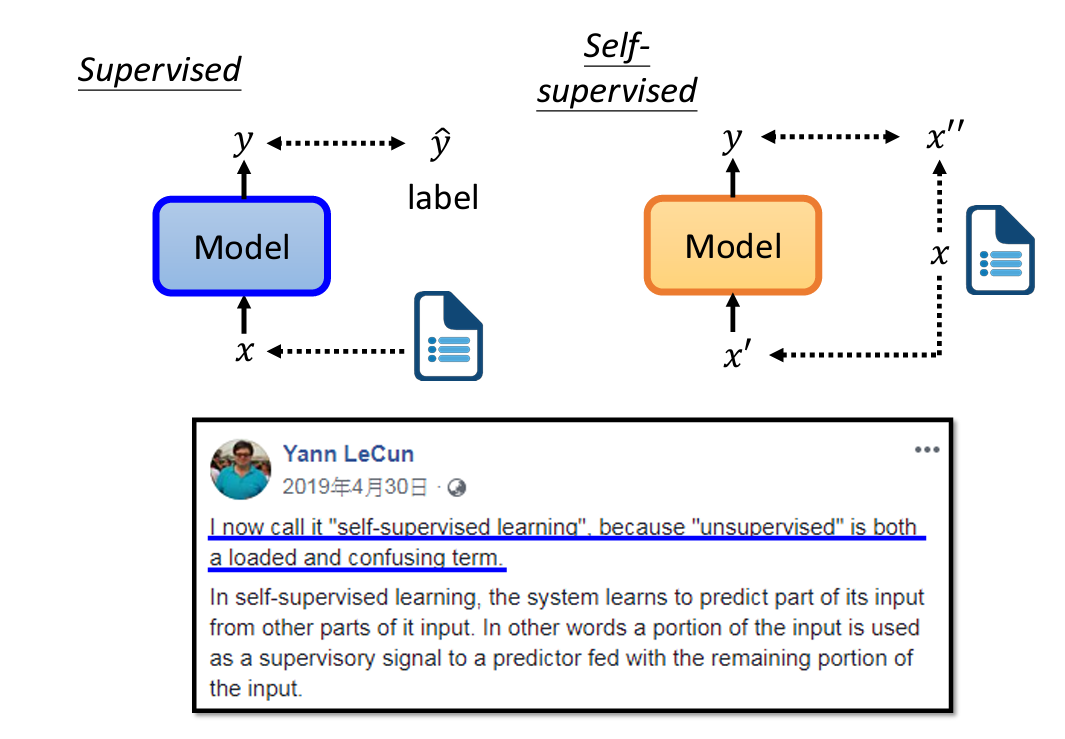
所谓的supervised learning,指的是传统的训练方法。即有输入,也有标准输出作为对比
而supervised learning,它是没有标注输出的,它把输入拆分成2个部分,一个部分用于模型的输入,另一部分用于模型的输出对比,它是没有标准答案的
Bert Self-supervised
Bert是采用了Self-supervised的方法训练得到的模型,之前说过,Bert做的是文字填空
Bert使用的self-supervised的方法主要有2种
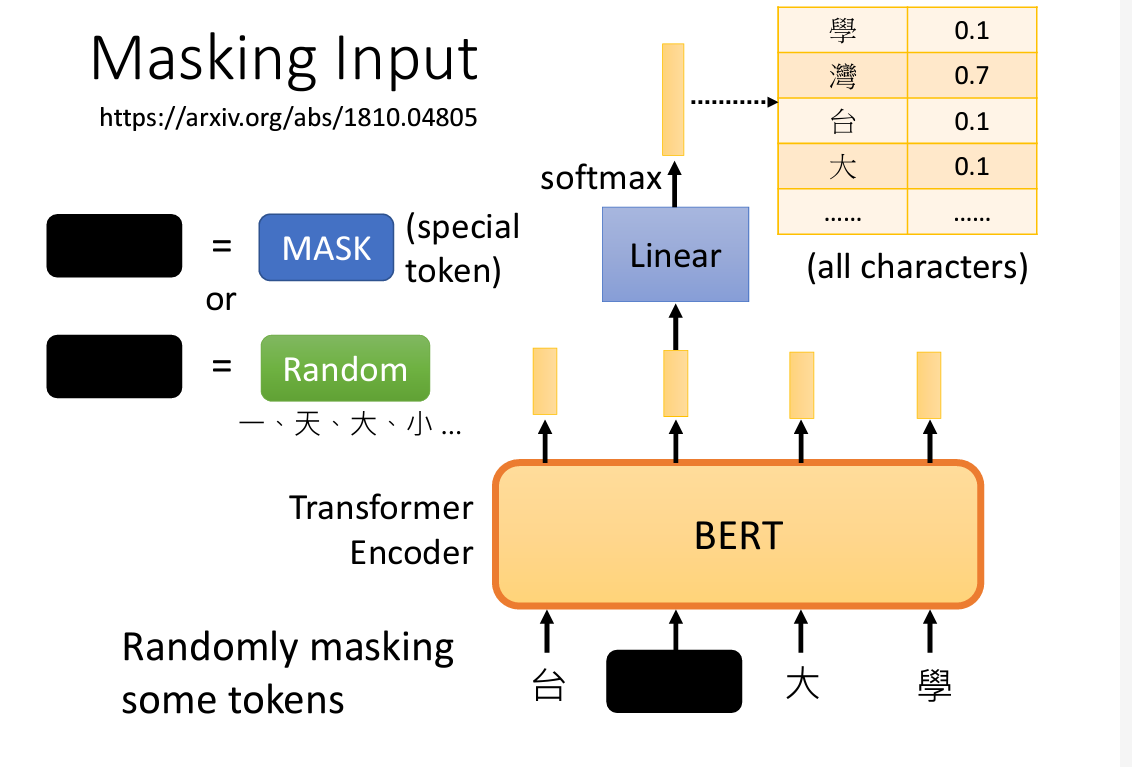
1. Masking input
将输入的一部分用某种符号表示,模型得到的结果和真正内容进行对比
顺道一提,把那个输入藏起来,用什么符号进行替换(mask或随机字符)都是随机的
另外,对比也是采用的常用的交叉熵(cross-entropy)
2. Next Sentence prediction
顾名思义,让Bert判断下一句是不是接在当前句子的后面的
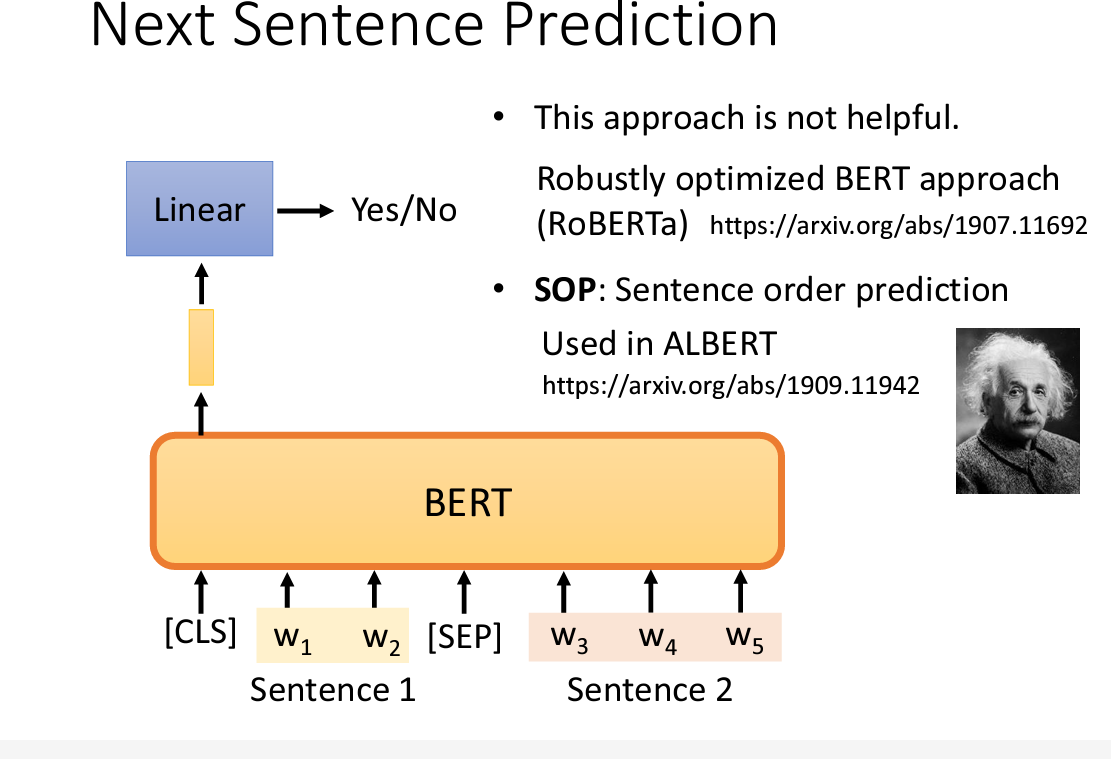 不过很多实验表明,这个方法貌似没什么用,然而
不过很多实验表明,这个方法貌似没什么用,然而SOP作为变种取得了不错的结果
3. Bert Application
将self-supervised Learning预训练得到的bert模型,再进行微调(Finetune),得到可以满足各个子任务的模型
为什么Bert学会做填空题了之后就进行微调就可以得到很多专才呢,这之间有什么关联?我也不知道,后续或许就知道了
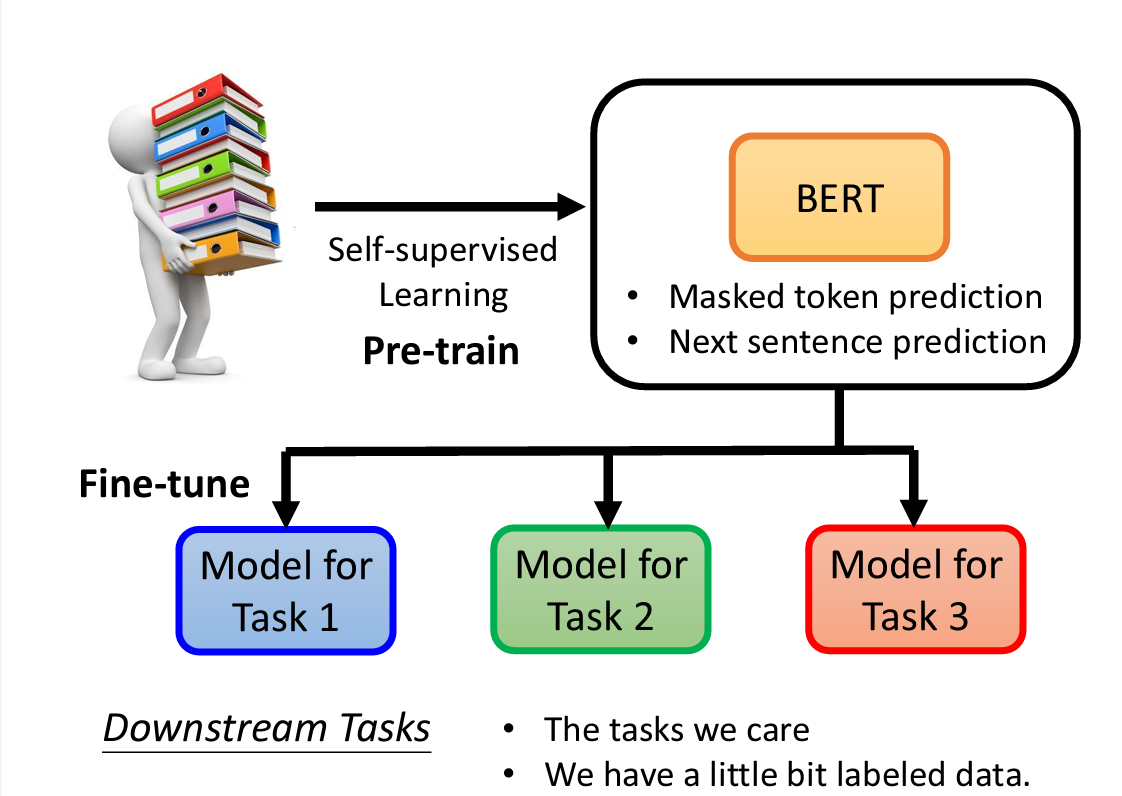 进行微调时,
进行微调时,Linear的参数是随机初始化的,然而Bert的初始化是设置好的
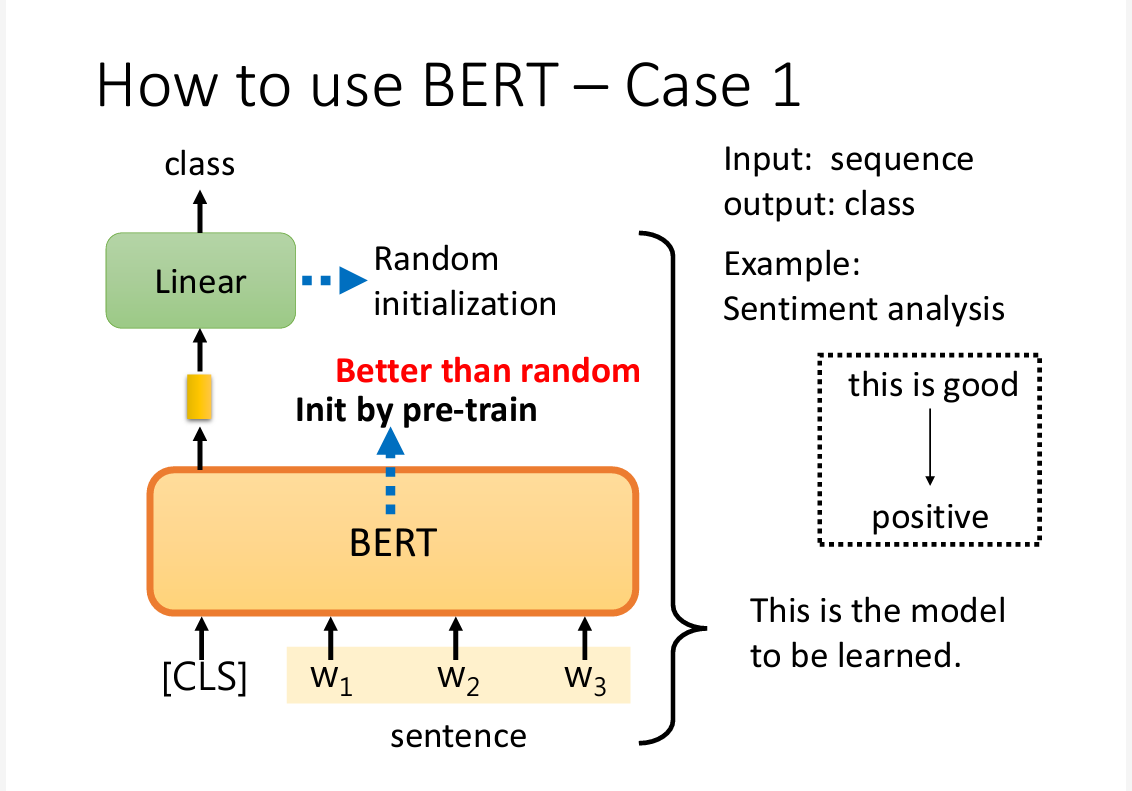 事实表明,经过预训练的模型微调后的结果会比没有预训练的模型在同一数据集下,得到更好的表现
事实表明,经过预训练的模型微调后的结果会比没有预训练的模型在同一数据集下,得到更好的表现
其实这也是很直觉的表现,毕竟预训练也事先也进行了很多训练
4. extra
事实证明,训练一个Bert是十分困难的,十分耗费资源
为了减少消耗,还出现了关于Bert 胚胎学的学问,专门研究,Bert是在训练的那一个阶段获得了神奇的填空能力和自我学习能力
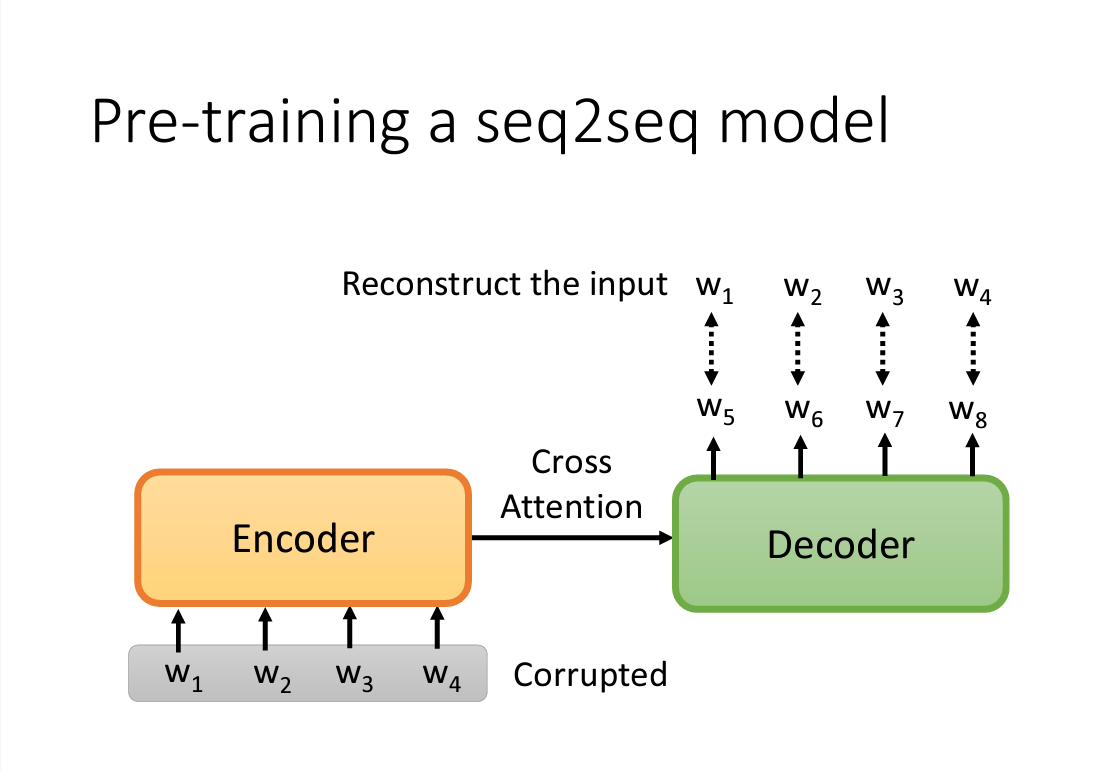
Bert 是一个transformer encoder,我们可以训练出一个相应的Decoder,采用的方法如下图所示,放入进行一些扰动后的输入,Decoder生成的输出应该跟完好的输入越接近越好
Chatgpt
Chatgpt的做法和Bert略有不同,使用的是方法是Predict Next Token
1. Predict Next Token
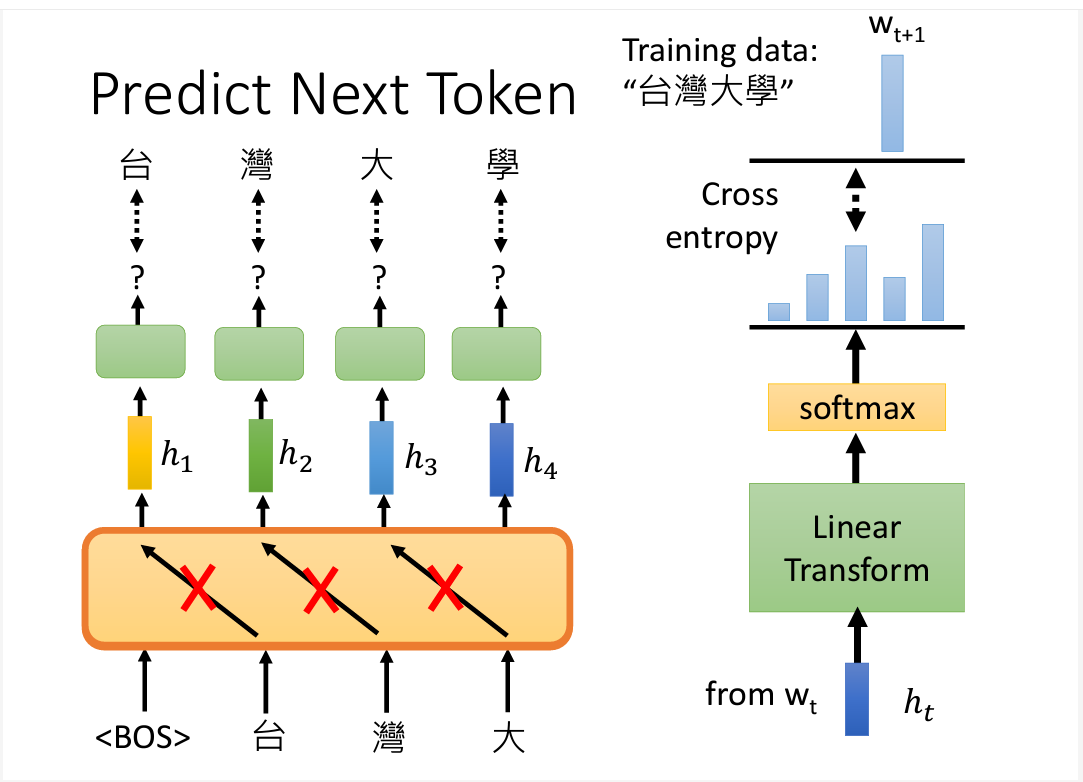
2. How to use Chatgpt
使用Chatgpt也和Bert不同,可能是因为Chatgpt模型真的太大了,以至于微调都很难进行,这就出现了之前说过的In-Context Learning 和 Instruction tuning 和 Chain of Thought Prompting
Self-supervised extra
Self-supervised 还有很多其他的做法和用途,可见下图