什么是机器学习
机器学习,本质上是让机器自动找一个函数
比如ChatGPT,就是要找一个函数,输入是一个句子,输出是句子后可能跟着的句子。
比如Midjourney,它找的函数就是,输入是一段描述,输出是一张图片
比如AlphaGo,它找的函数是,输入是围棋棋盘的信息,输出是下一次棋子的落子
以函数输出分类的话,机器学习可以分为3种
1. 回归(Regression)
即输出是一个数值
2. 分类(Classification)
即输出是一个类别,就是做选择题
3. 生成式学习(Generative Learning)
也叫Structed Learning,就是生成有结构的物件,比如(影像,文句)
ChatGpt在原理上属于Classification,在用户体验上属于Generative Learning,相当于用分类的办法实现生成式学习
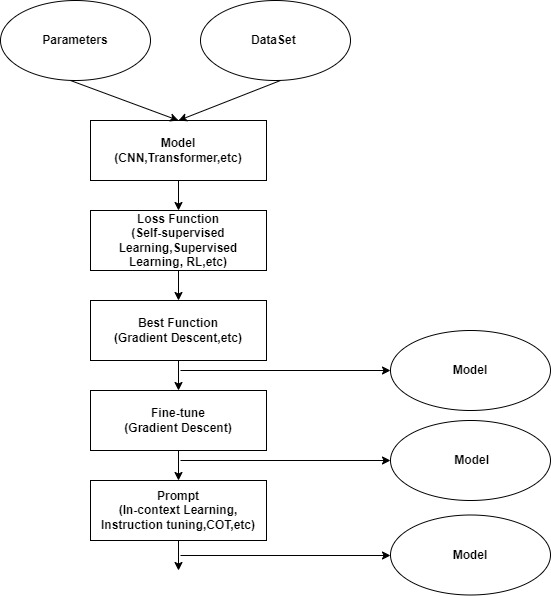
寻找函数的三步骤
1. 找出函数集合(Model)
深度学习中的类神经网络结构(例如CNN,RNN,Transformer等等),指的都是候选函数集合
2. 订出评价函数好坏的标准(Loss Function)
就是之前提到的Loss Function
这里可以根据你训练资料的不同做不同的Function,比如,如果你用的是Supervised Learning,即,每个数据都有想要的专家标注,可以制定简单的Loss Function
如果你使用的是Semi-supervised Learning,即只有部分数据有标注,就需要较复杂的Loss Function,提高预测度。
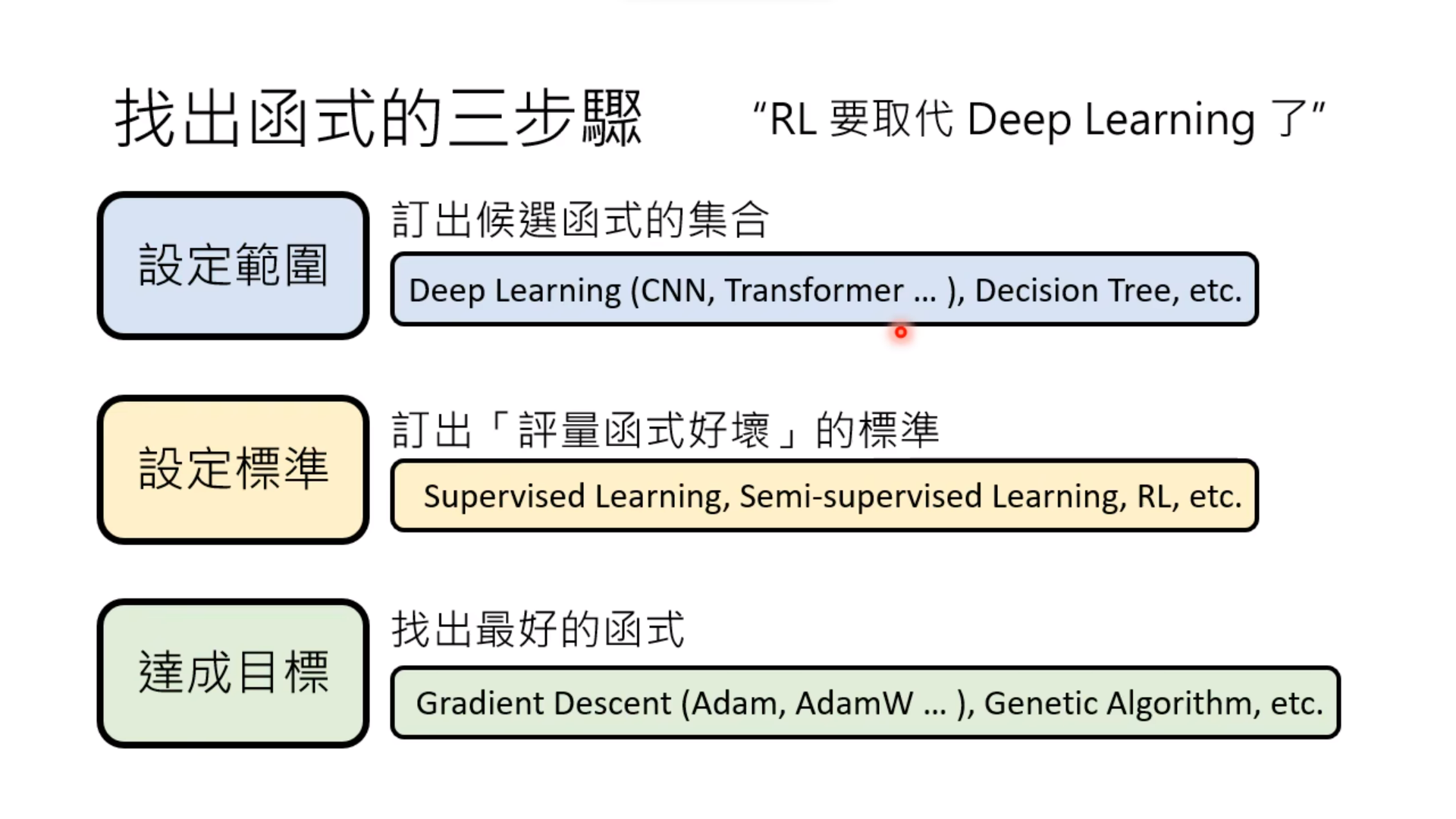
3. 找出最好的函数
使用比如之前说到的Gradient Descent,找到一个最好的函数
总结
 这里需要了解到,不同的什么学习,在机器学习中的定位是什么
这里需要了解到,不同的什么学习,在机器学习中的定位是什么
Extra
在第3步中,虽然理论上可以找到最好函数,实际上,并不总是能跑出来
所以在实际中,我们需要自己设定Learning Rate,Batch Size、初始化方法,等等。为了区分机器学习内部代码的参数,这些人为操控的参数被称为超参数(Hyperparameter)
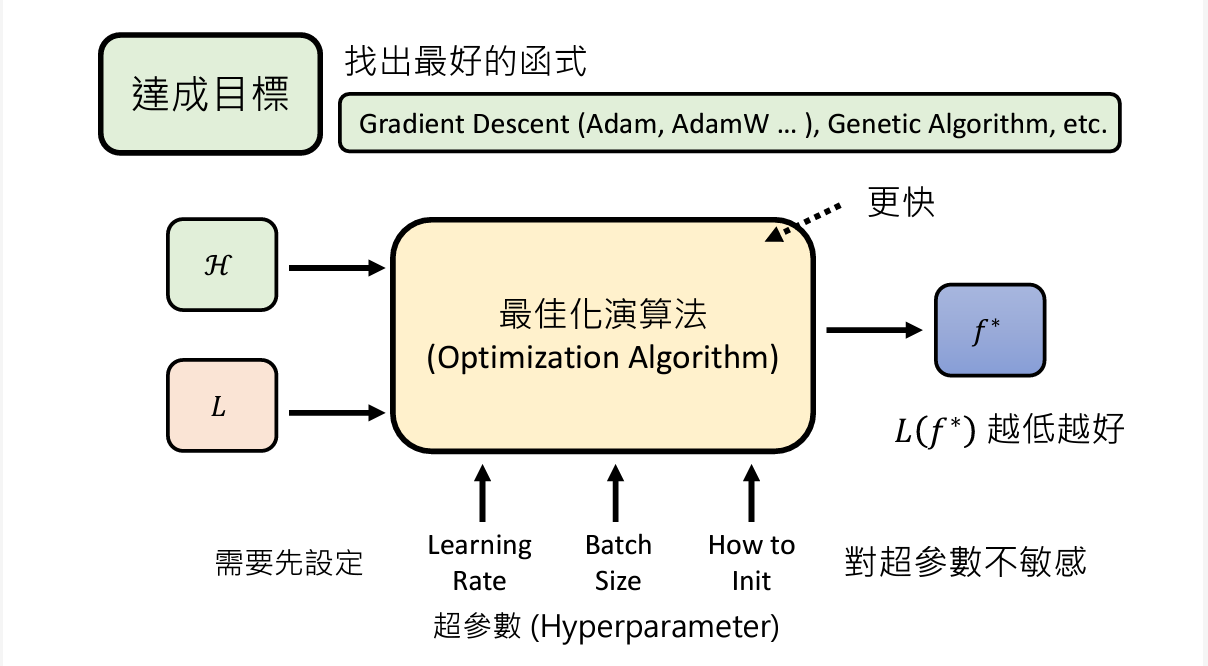 另外在第2步中,有时候在训练数据集上面效果好的函数,在测试数据集上面不一定好,很大程度上是因为训练集不够多,容易过拟合,因此需要在Loss上做额外考量
另外在第2步中,有时候在训练数据集上面效果好的函数,在测试数据集上面不一定好,很大程度上是因为训练集不够多,容易过拟合,因此需要在Loss上做额外考量
在第1步中,为了减少函数集合的数量,提高筛选效率,通常会设定一个合理范围内的函数集合。然而减少了函数集合范围,容易错过较好的函数,如何合理定制函数集合,也是一门技术活
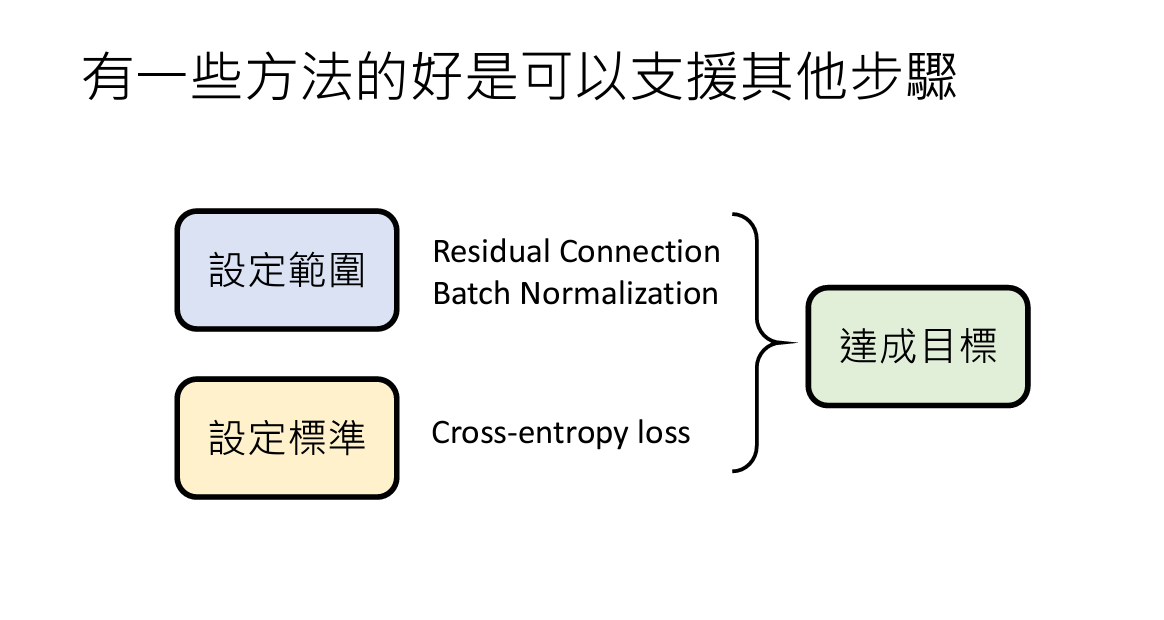
最后,其实某些步骤的额外考虑在这个步骤里面不一定会有作用,但是可以帮助到其他步骤。
Generative Learning
这里详细介绍一下Generative Learning
先前讲过,这里指的是生成有结构的复杂物件,比如文句、影像、语言
Generative Learning中有2个主要方法AR(Autoregressive Model)和NAR(Non-autoregressive Model)
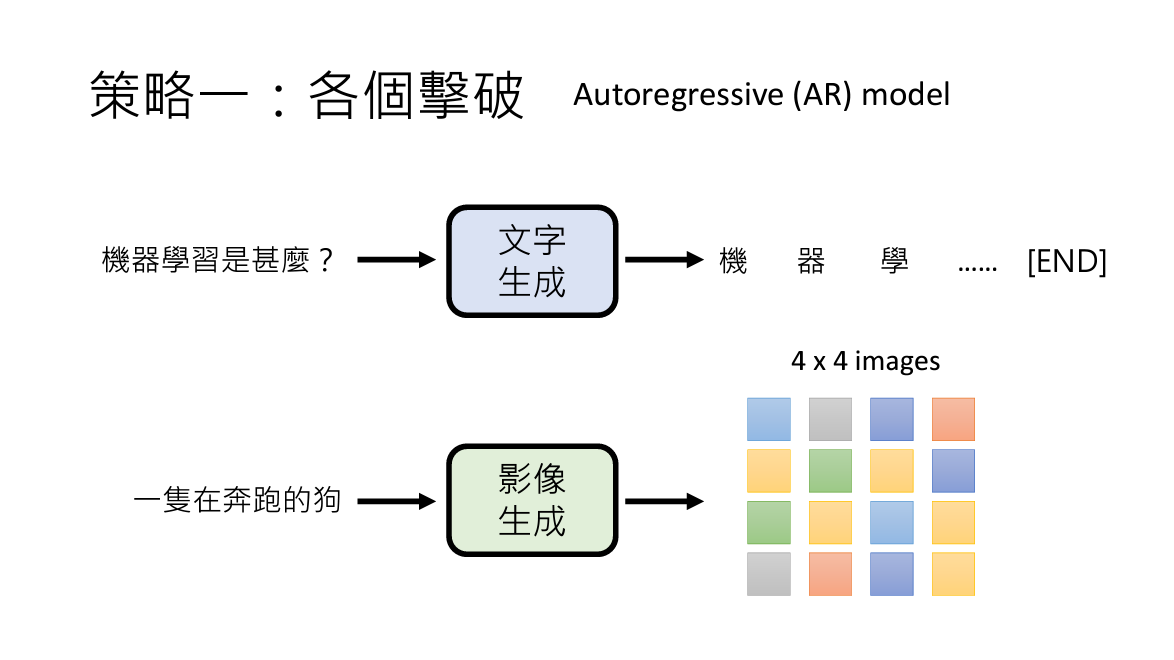
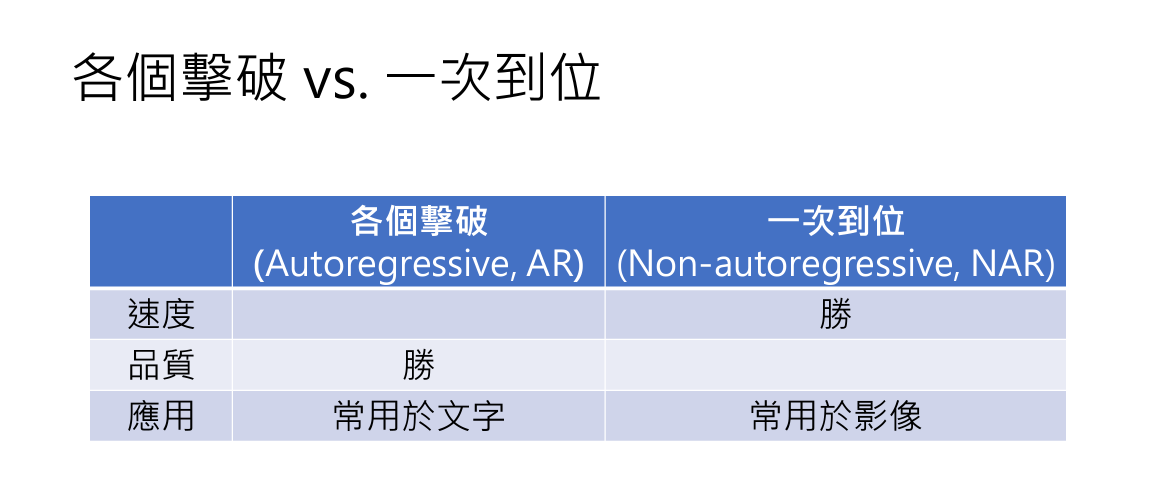
1. AR(Autoregressive Model)
俗称逐个击破
用生成句子来理解,就是一次生成一个字,直到遇到停止符号。
2. NAR(Non-autoregressive Model)
俗称一次到位
同样还是生成句子来理解,就是一次想把生成的字都生成了。
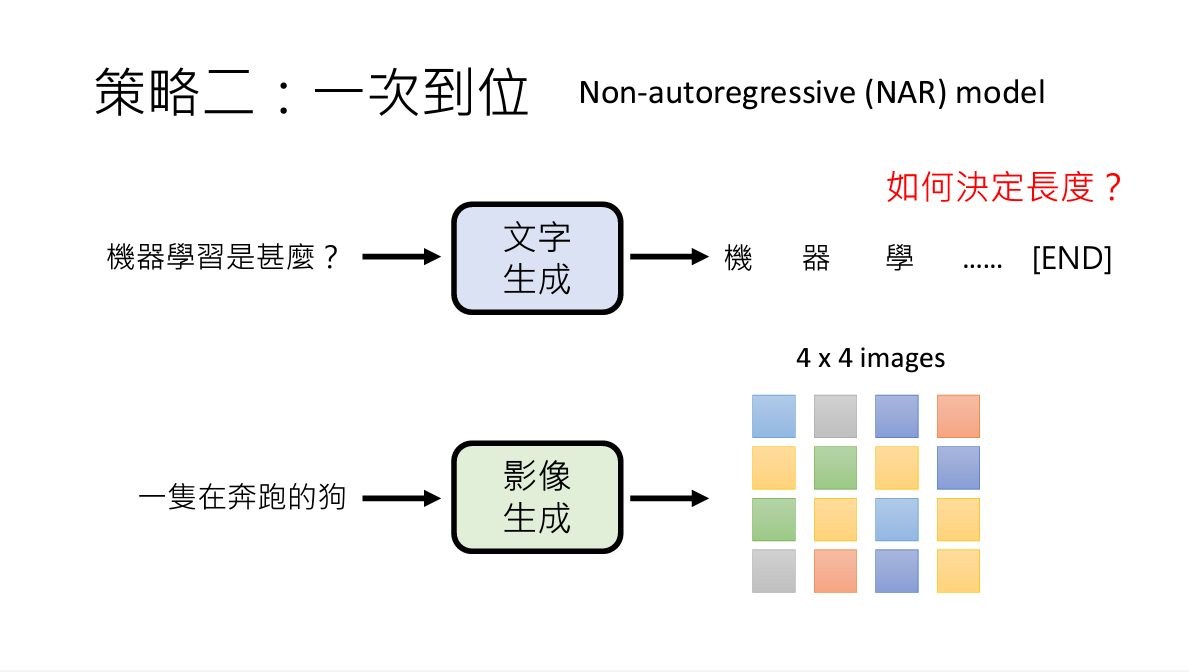 但是此时会遇到如何停止的问题。
但是此时会遇到如何停止的问题。
大体有2个办法比如预设500长度,让Model生成500长度,把停止符号后的文字全仍了;或者无论如何,都生成100长度的文字
3. AR vs NAR
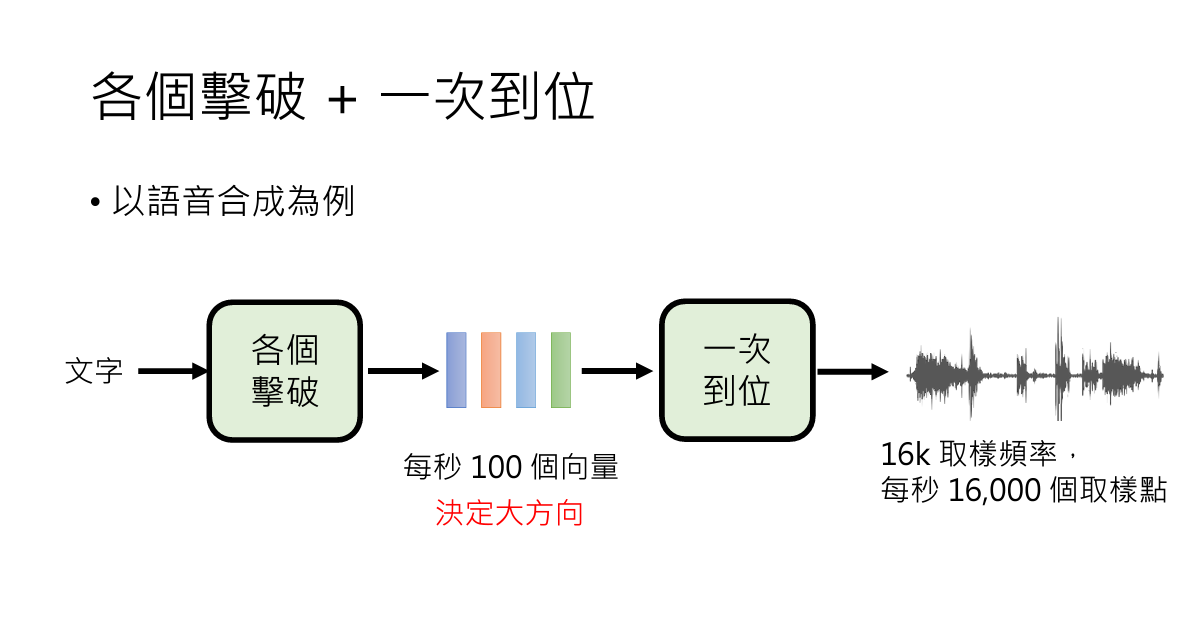
4. AR/NAR 结合
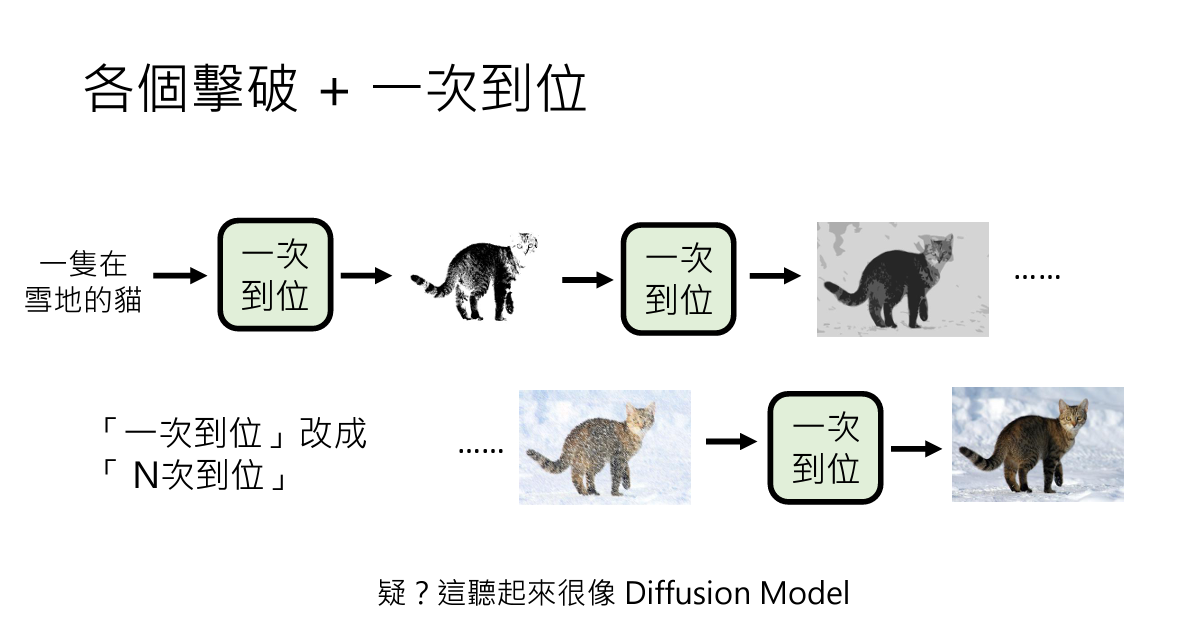
Total Training Process