- 图像生成基本概念
- 1. VAE(Variational Auto-encoder)
- 2. Flow-based Generative Model
- 3. Diffusion Model
- 4. Generative Adversarial Network (GAN)
- Stable Diffusion
图像生成基本概念
先前也介绍过,图像生成使用的是NAR(No-autoregressive)
因为AR太耗时了
然而NAR也不是一点坏处都没有,最显著的问题就是,取样时各个像素点是不关联的,就会导致合成一个四不像的图片出来(
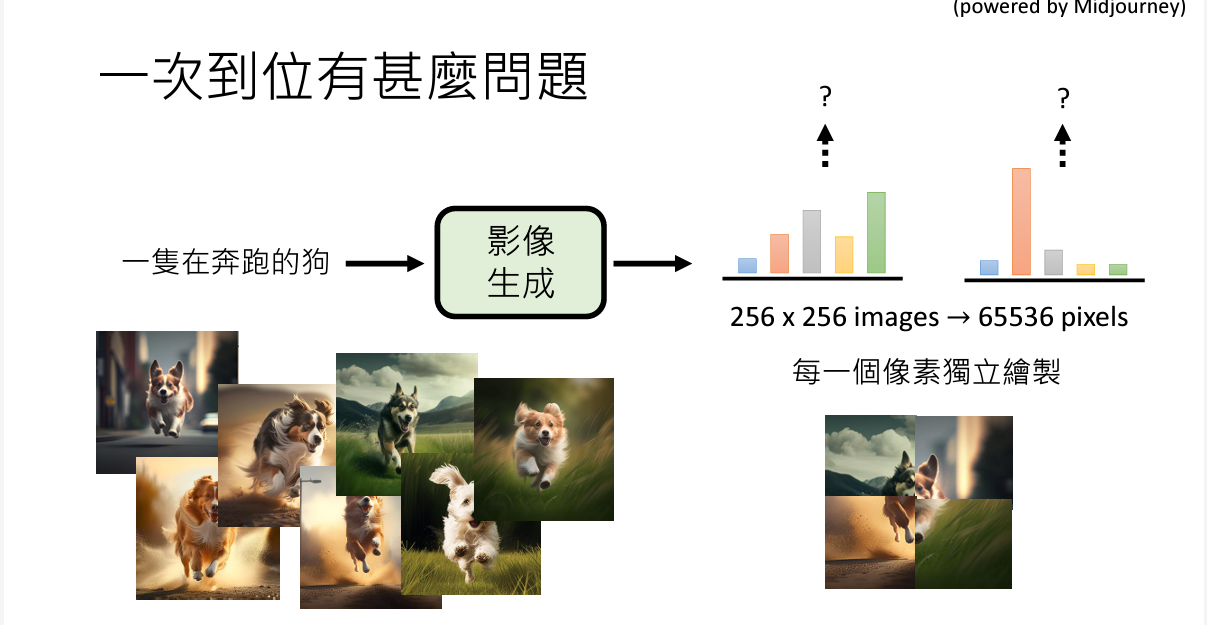 为了解决这个问题,通常的图像生成模型都加入了
为了解决这个问题,通常的图像生成模型都加入了Normal Distribution来增加取样点的相似度
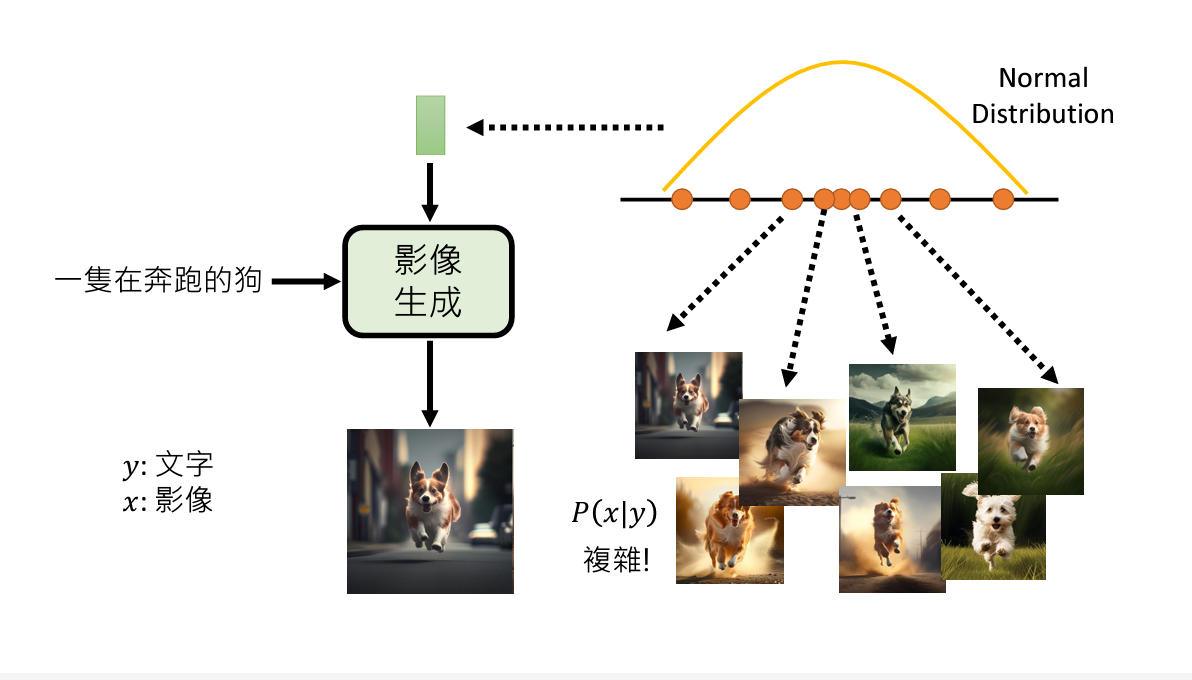 以下是当前图像生成模型的常用方法
以下是当前图像生成模型的常用方法
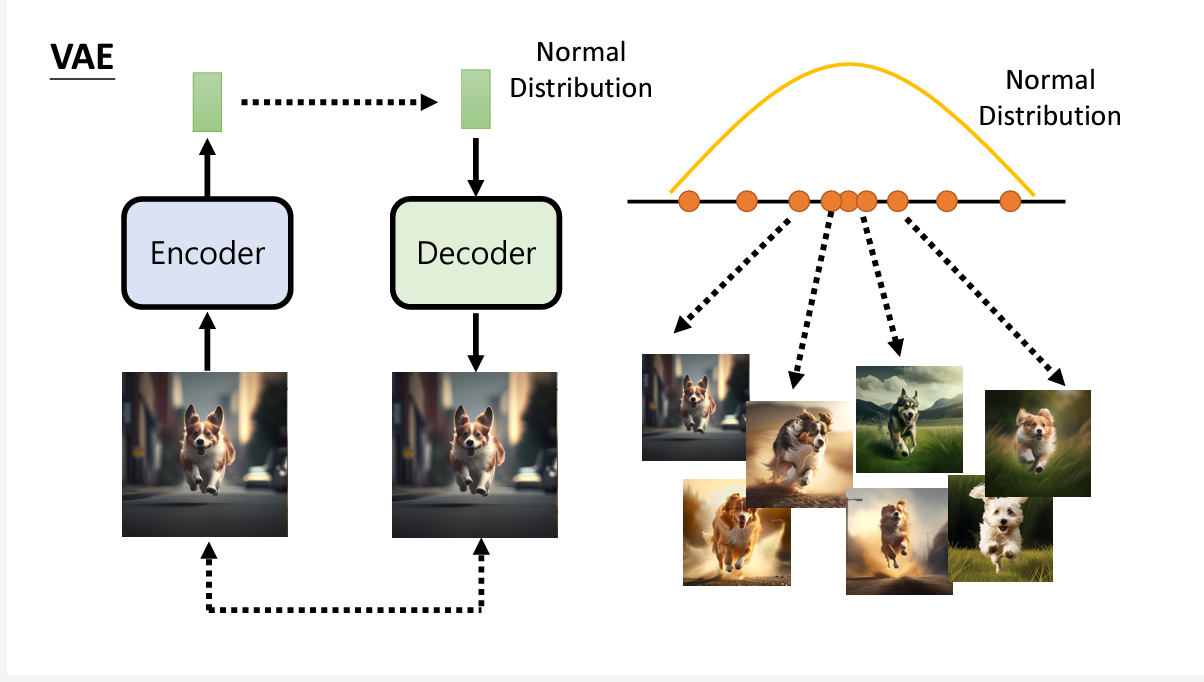
1. VAE(Variational Auto-encoder)
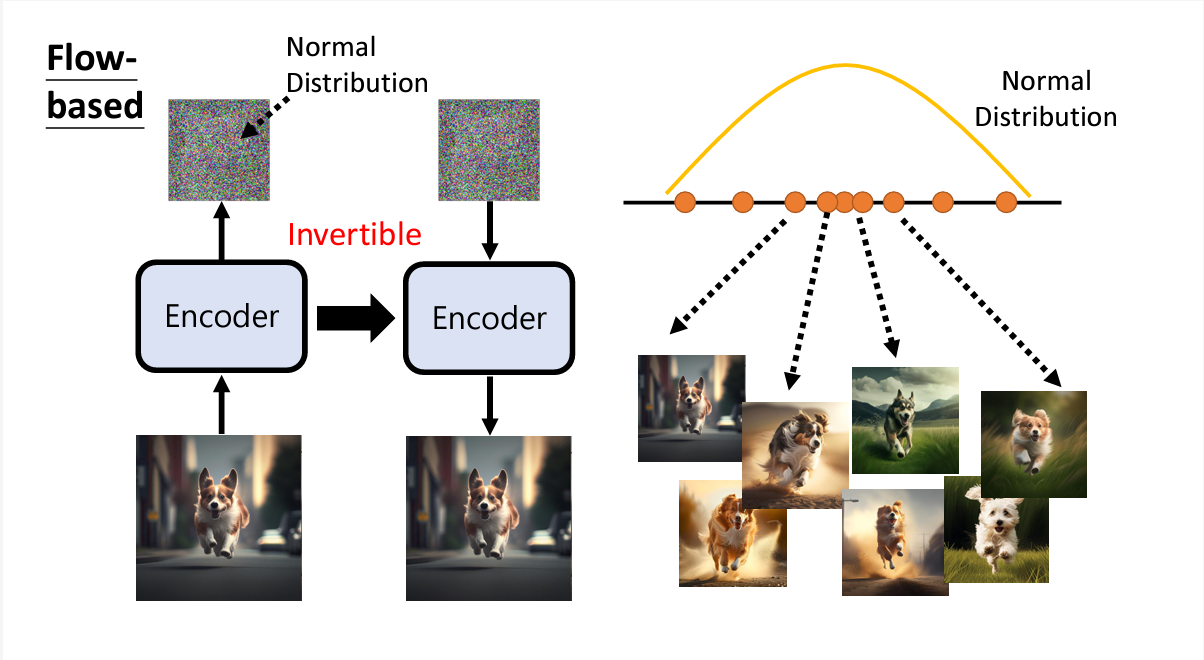
2. Flow-based Generative Model
3. Diffusion Model
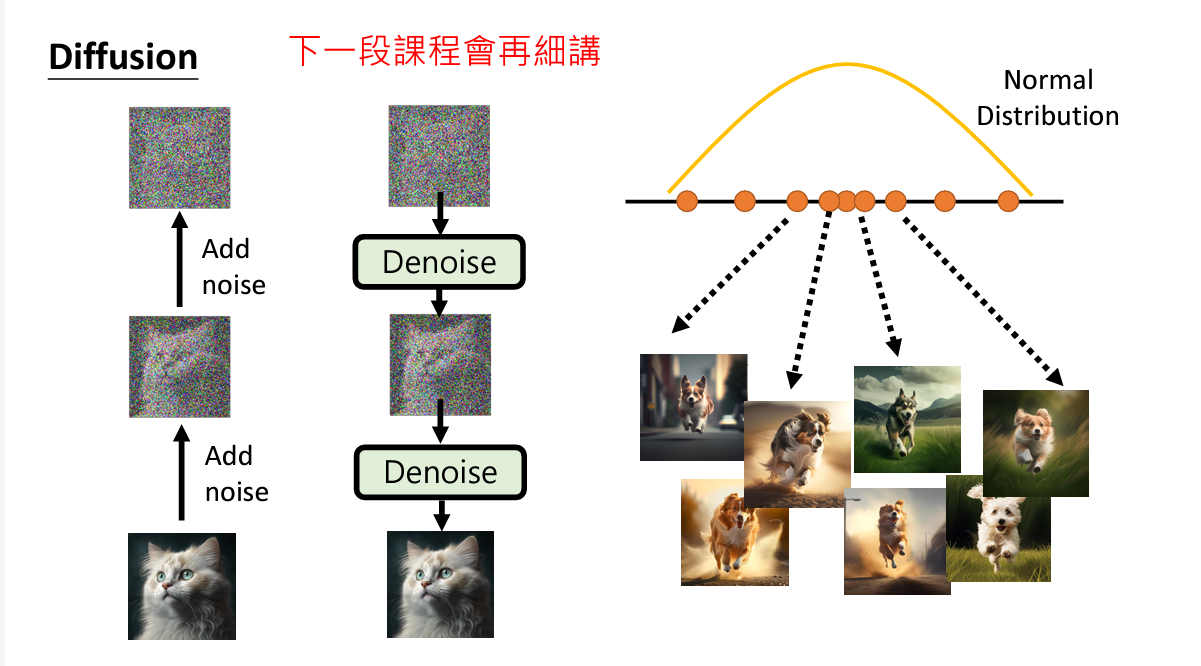 Diffusion Model的本质思想和米开朗基罗的一句话很像:
Diffusion Model的本质思想和米开朗基罗的一句话很像:雕塑其实就在大理石里,我们只是去掉了一些不必要的成分罢了
Diffusion Model是现在很多stoa的框架使用的技术,所以着重学习它
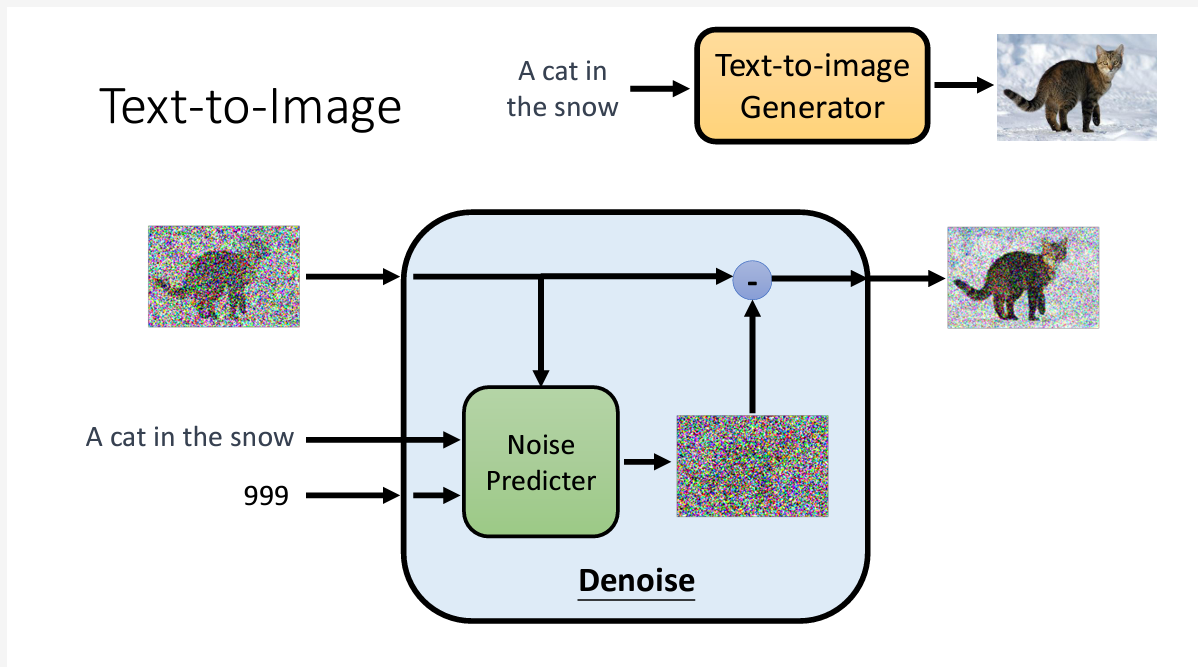
一、工作原理
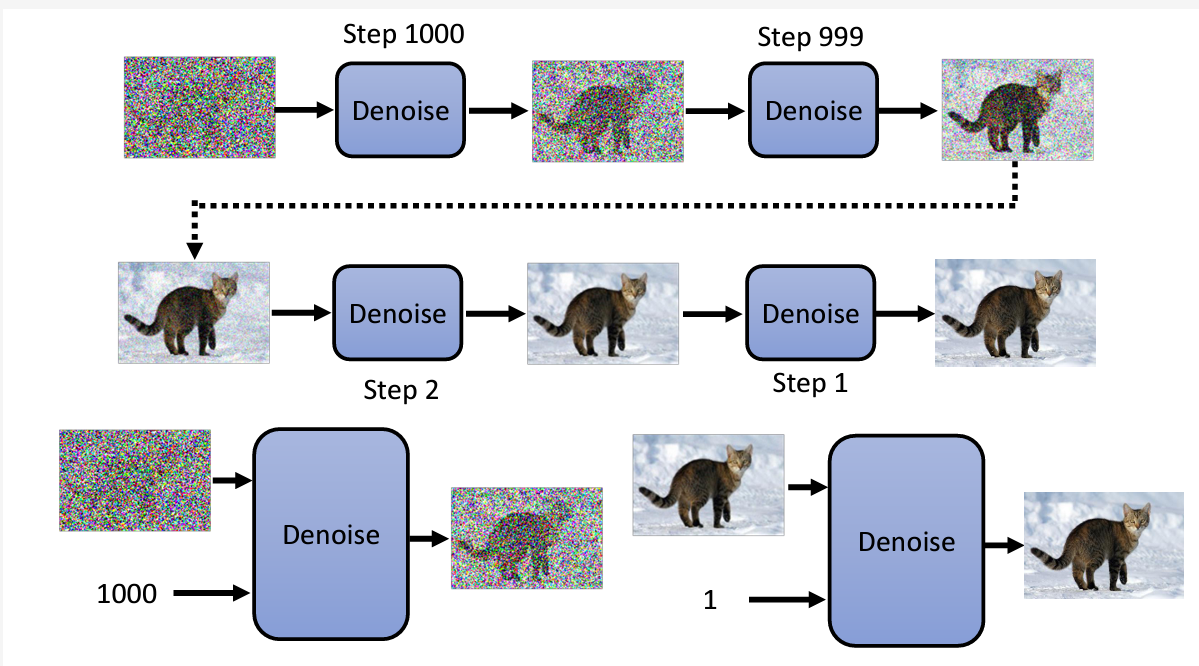 实际上一个
实际上一个Denoise要做的事情,其实是生成一个噪音,然后在输入的图片中减去这个噪音而已
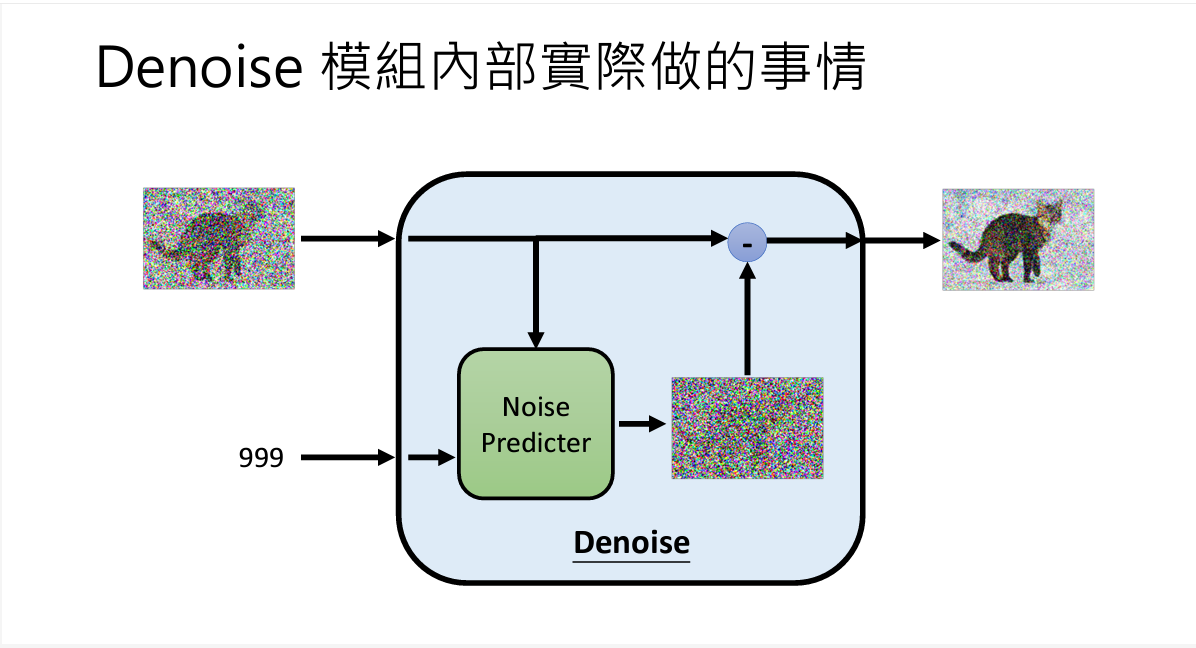
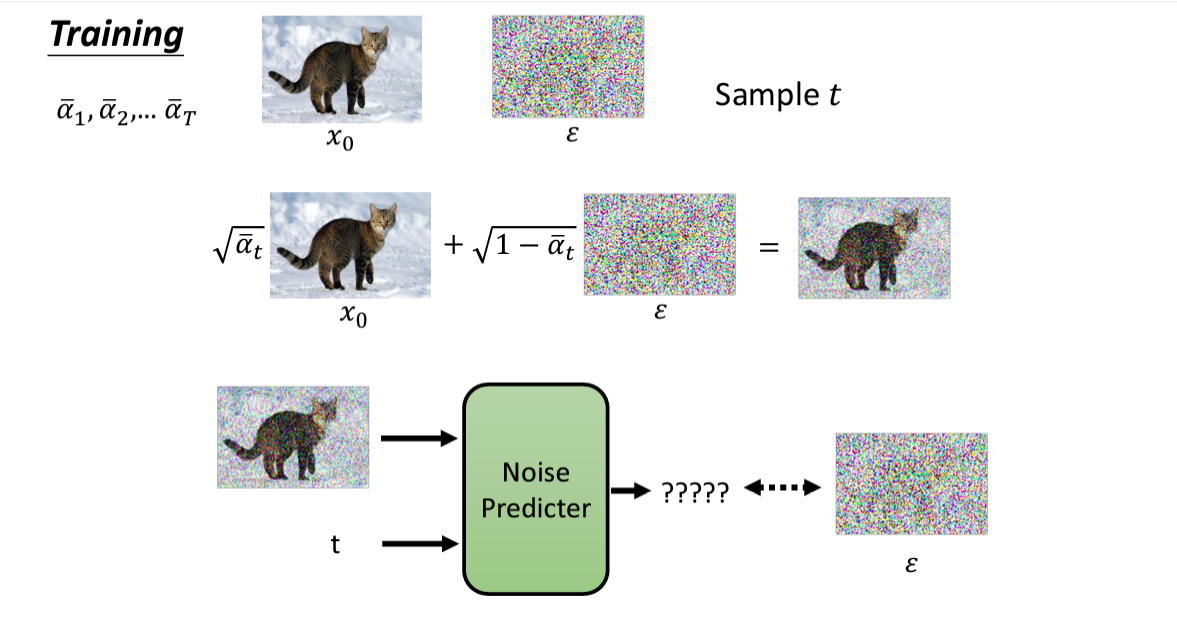
二、如何训练Noise Predicter
下图可以比较直观的显示:
在训练时,使用正常图片,然后随机添加噪音;随机添加的噪音就是样本数据!
 当然,实际上是需要有文本输入的模型,如下图所示:
当然,实际上是需要有文本输入的模型,如下图所示:
 大致情况是:
大致情况是:
- 文本-图像生成器根据文本t 生成图片p1;
- 对p做随机噪音处理1,2,…n次,保留第i次添加的噪音noise_i,以及最终的噪声图片p2
- 将p2和t和i喂入Noise Predicter,生成的噪音niose2_i与noise_i进行对比,修正误差
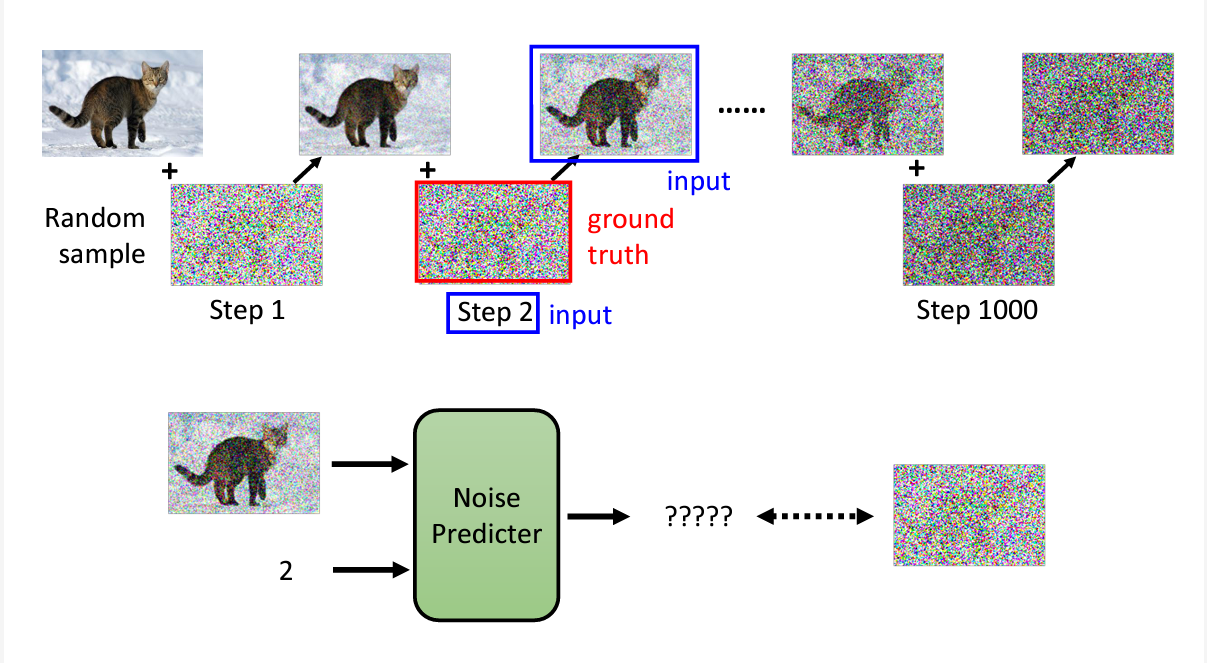
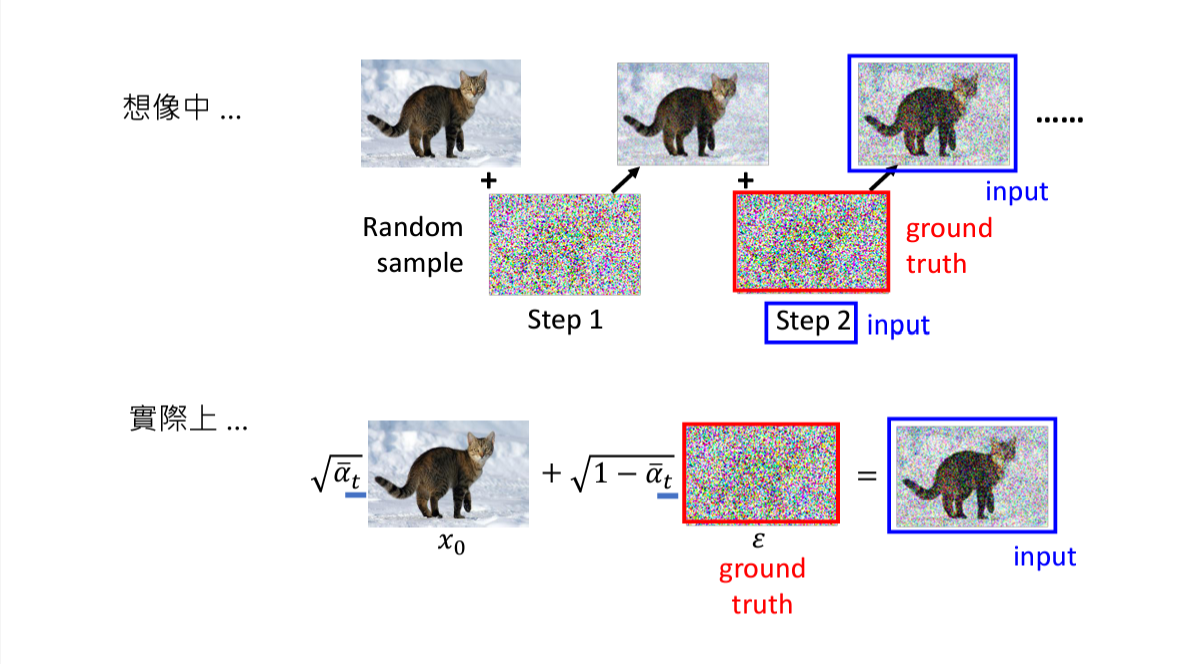
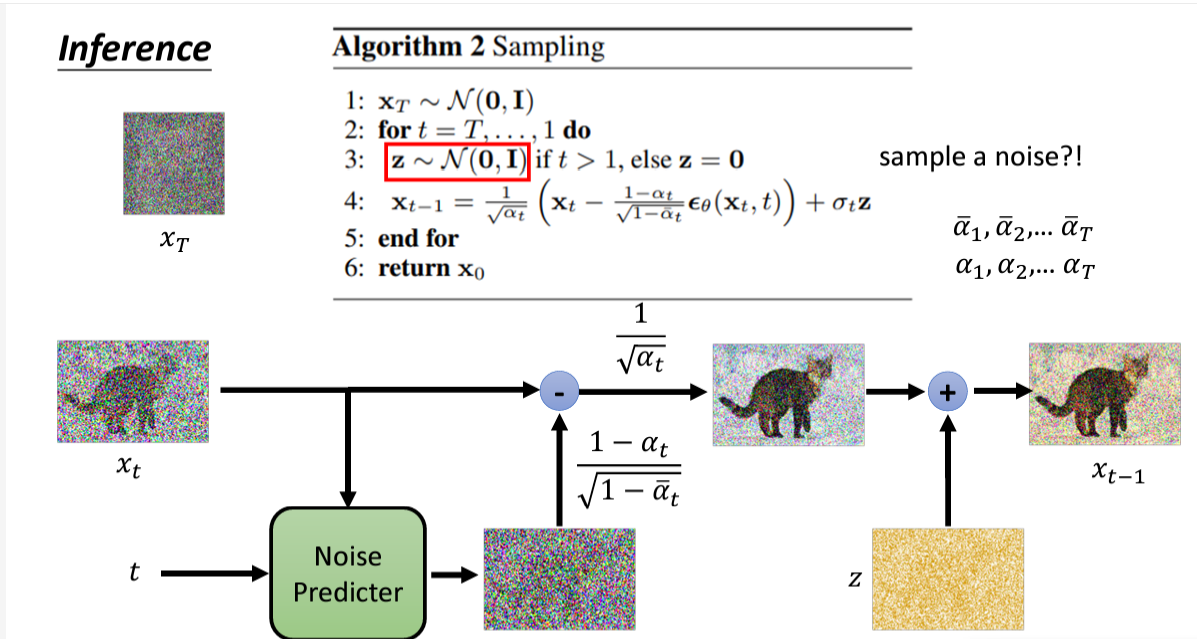
三、实际训练步骤
其实,实际上的noise predictor训练和推导过程和上述说的答题思路一致,但是实际做法有差异

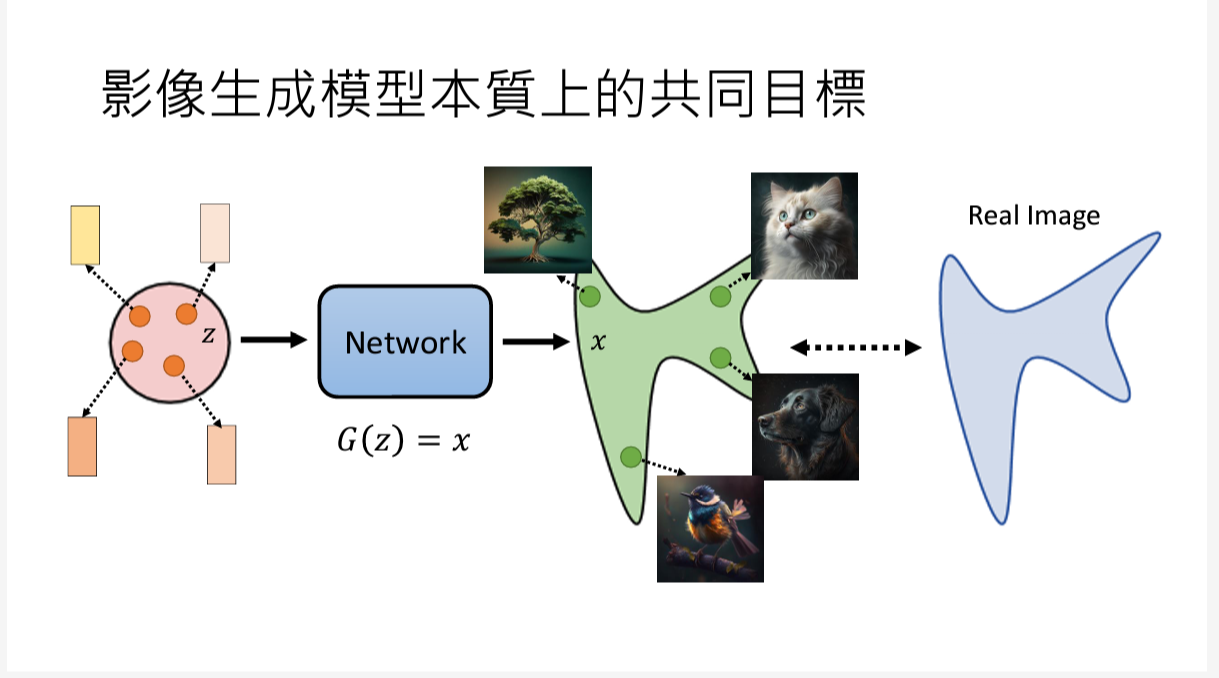
4. Generative Adversarial Network (GAN)
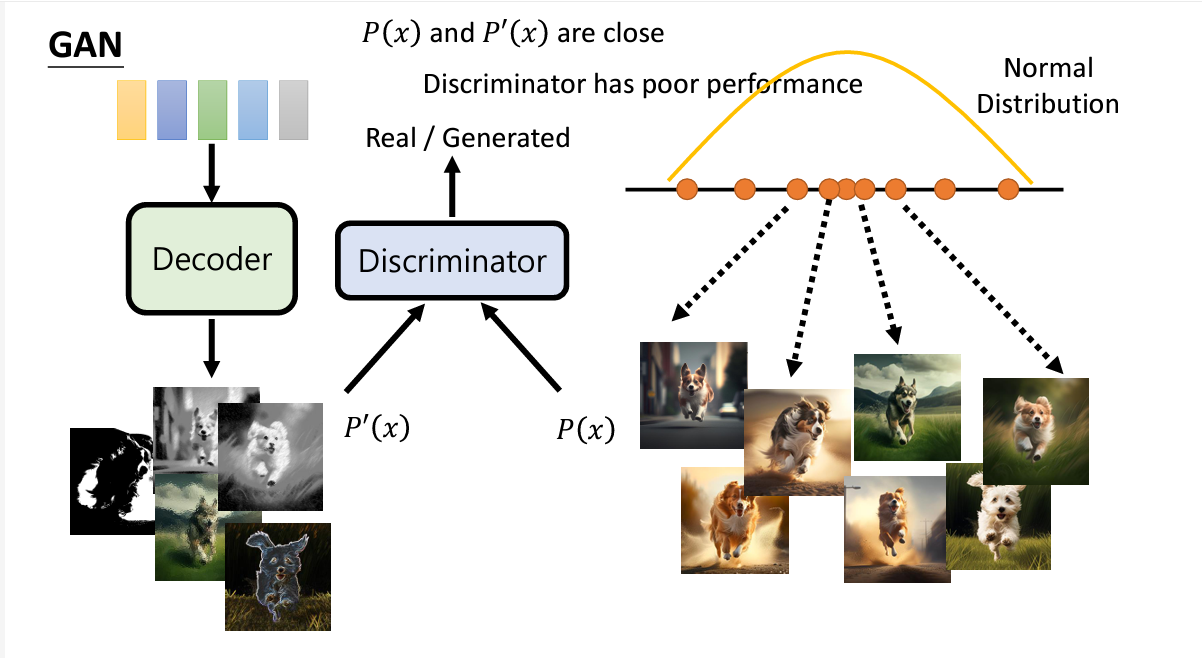
Stable Diffusion
这个最新最热的技术所用的流程如下图所示
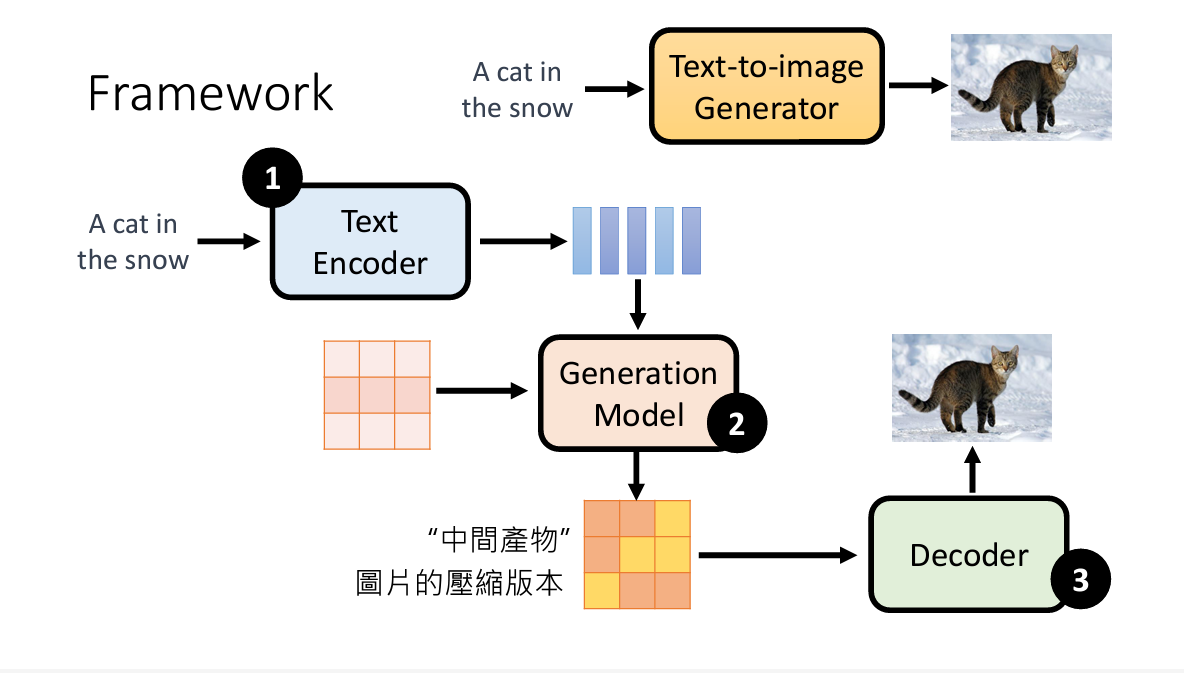
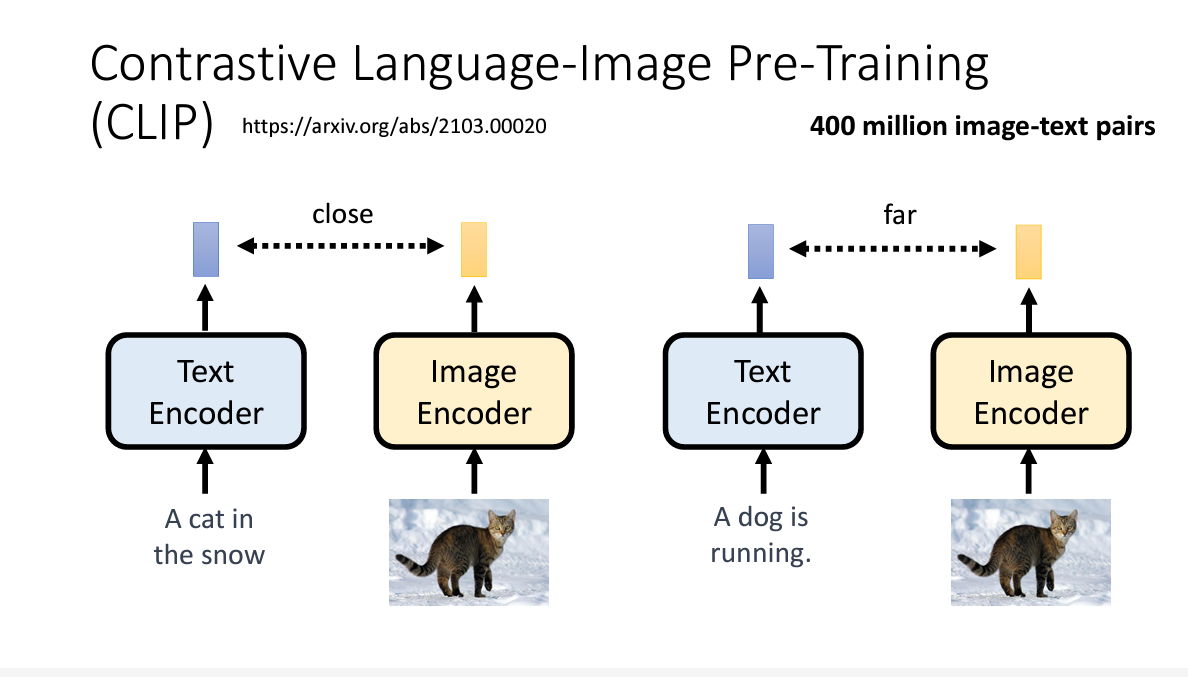
一、 Text Encoder
这个东西据当前最新最热实验证实,是很重要滴,图片画的好不好,很大程度取决于它,具体怎么造它,我也不知道
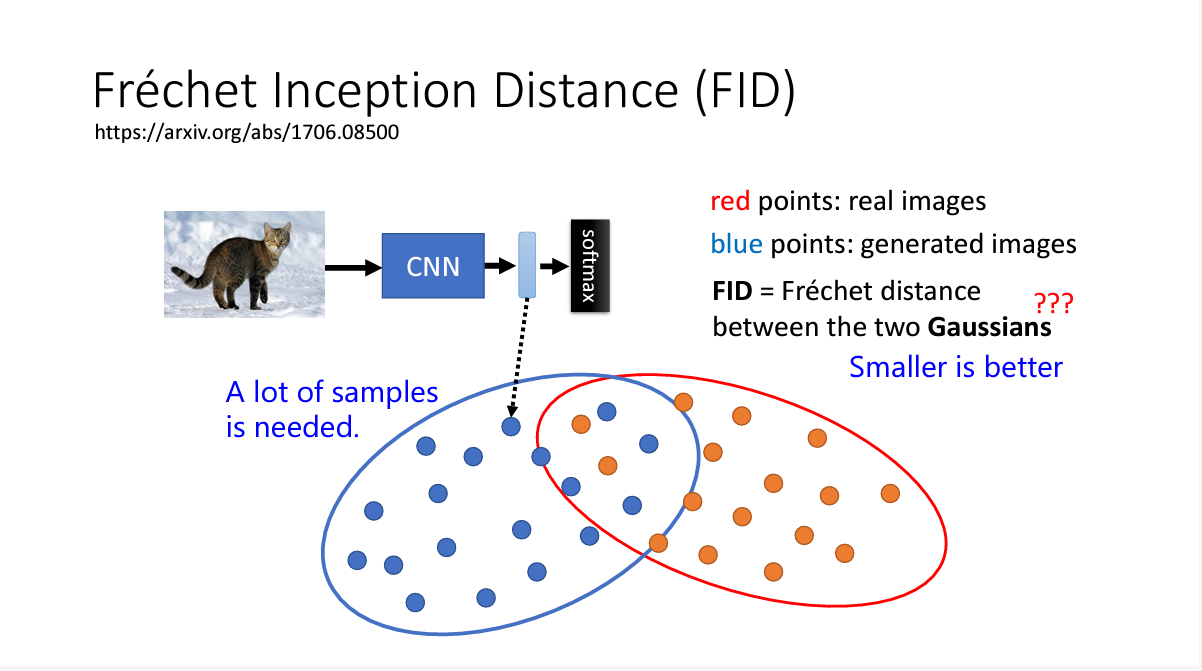
衡量它的标准主要有2个FID(越小越好)和CLIP(越大越好)
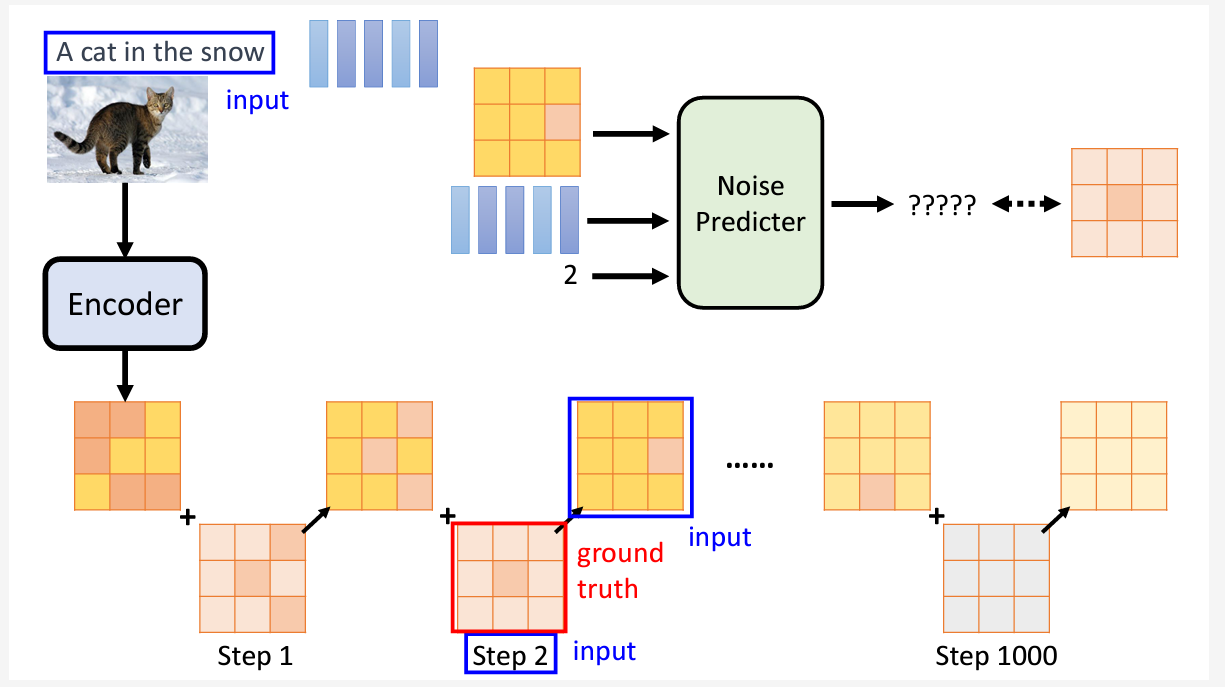
二、 Generation Model
这个就完全是Diffusion Model的操作
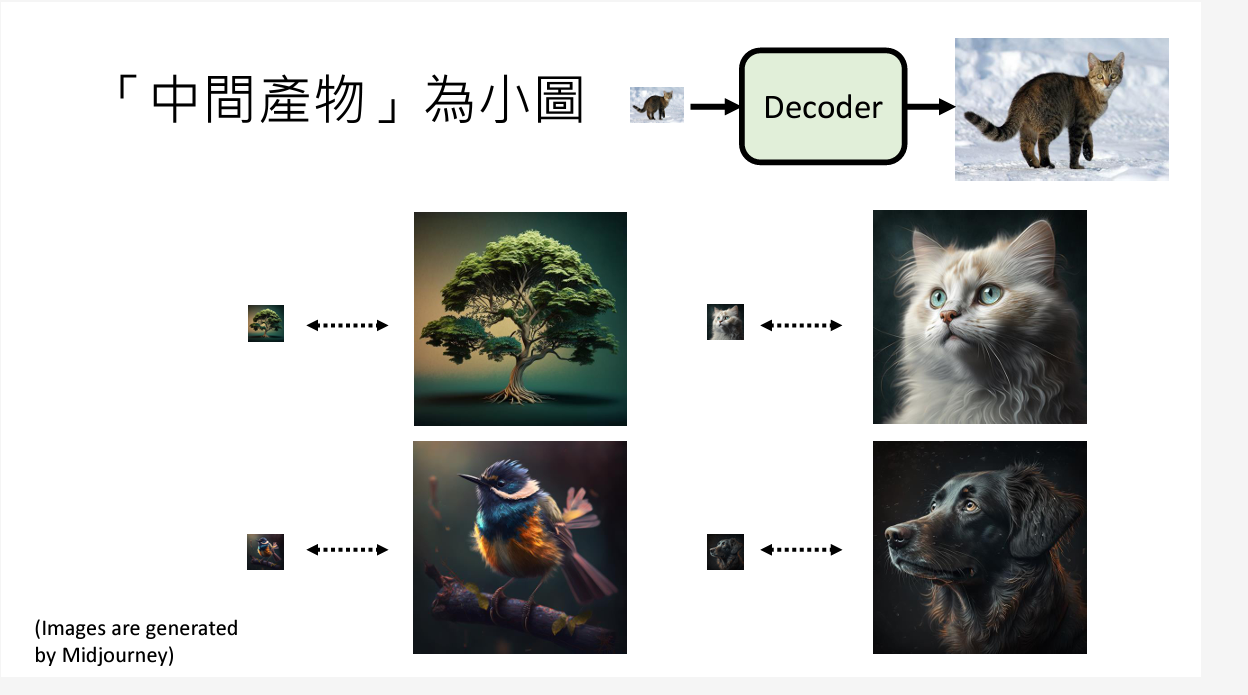
三、 Decoder
这个很好理解,如果中间生成物是缩略图,那么放大就可以了
 如果中间生成物是未知表示,如下图进行操作
如果中间生成物是未知表示,如下图进行操作
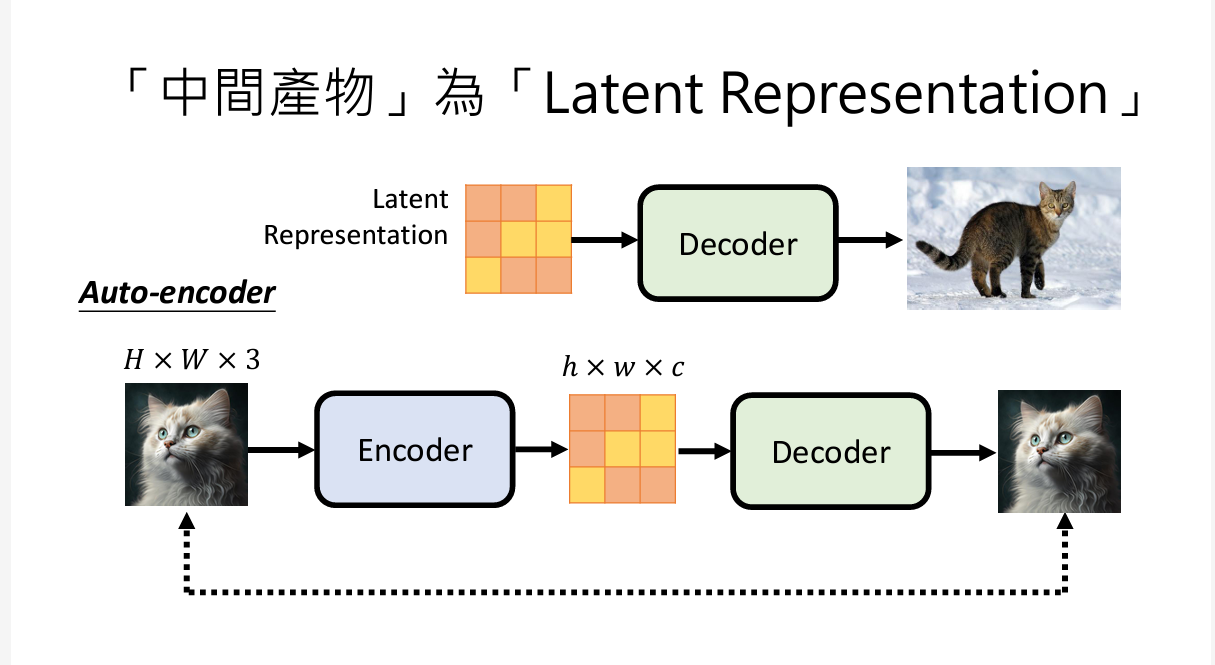 除了Decoder,你需要自己训练一个encoder,输入图片,输出是中间表示,把其输出放入Decoder,判断decoder是否能生成理想的图片
除了Decoder,你需要自己训练一个encoder,输入图片,输出是中间表示,把其输出放入Decoder,判断decoder是否能生成理想的图片