写在前面
这边笔记是对于最近看的一篇论文Fuzzware: Using Precise MMIO Modeling for Effective Firmware Fuzzing的总结。
这是一个结合了符号执行技术(angr)和模糊测试技术(fuzz)以及仿真技术(Unicorn)的产物,目的是更有效的模拟固件执行,发现更多的漏洞。使用基于符号执行引导的模型方法,但是提供了一个更细粒度的模型方法来消除fuzzer的输入开销
技术背景
在看这篇论文前,需要了解一些前置知识。
1. 目标固件
这篇论文关注的是monolithic firmware,即https://wsxk.github.io/iot%E5%85%A5%E9%97%A8%E4%B8%80/提到的III型嵌入式设备,没有系统存在。
2. Memory-mapped IO(MMIO)
同样可以看一下https://wsxk.github.io/iot%E5%85%A5%E9%97%A8%E4%B8%80/#iot%E8%AE%BE%E5%A4%87%E7%BB%84%E6%88%90提到的,MMIO是嵌入式设备cpu和外设交互的一种方式(顺道一提,DMA其实是基于MMIO实现的)
通过直接将外设的寄存器或存储区域直接映射到内存中的一个位置,使得CPU可以通过LOAD/STORE指令直接访问数据。
这是一个很高效的方法。
3. Interrupts and DMA
中断也是一种cpu和外设交互的方式,当外设的内容到达时,硬件可以会触发中断,通知cpu立刻处理到达的数据。
DMA是通过MMIO实现的方法,外设拥有权限直接往内存写入东西,不需要通知CPU。(本质上是有一个DMA控制器来管理外设和内存的数据传输,传输完成后会发出中断给cpu,让cpu执行需要的操作)
4. Re-Hosting Embedded Systems
本质是是把嵌入式固件,从嵌入式设备(物理设备)上移动到PC机上,利用PC机的强大资源进行模糊测试。然而模拟固件运行也有许多难题:模拟CPU指令的执行是很容易做到的,但是模拟外设与CPU交互这一方面存在巨大困难。
嵌入式固件中 cpu和外设交互的方式主要有3种:MMIO, Interrupts, DMA(PMIO也有,但是不是很常见)
模拟的主要问题处在对这3种方式的实现上。
这篇论文主要关注的是MMIO的实现。
目前,对MMIO模拟的解决方案有2种。
以qemu为首的重写派: qemu会针对每个MMIO的外设,完全的复现在嵌入式设备上的行为。这种办法在用户体验上来说是很好的,对于qemu开发人员来说还是很累的:他们需要针对每个外设,查看硬件手册。
approximation派: 引入fuzzer来解决MMIO的访问问题。本质上来说,fuzzer生成的随机值是可以作为硬件生成的返回值的。这个方法很好,因为不需要关系外设的实现细节和MMIO的前置知识。然而,要想实现这个技术也有困难:fuzzer需要给每个MMIO外设提供随机输入(这通常有很多个),而大多数的外设提供的值是没有意义的,也就是说,fuzzer很多时候再做无用功,并不能很好的适应现实的嵌入式设备。
有关MMIO的模拟的问题讨论
这一节讨论 为什么用fuzzer解决MMIO问题会导致很大的开销,另外探寻一下现存的去除这些开销的方法。
1. Input Overhead
假设一种天真的方法,其中模糊器生成的随机字节流中的比特被用作硬件生成的值(即,从固件的角度来看,由硬件MMIO寄存器提供的值)。我们将这些比特称为模糊器变异输入空间,然后由固件逻辑进行处理。这个输入空间既包含相关的位,即影响固件逻辑的位,也包含输入开销。对于每个MMIO访问,我们区分两种类型的输入开销。
Full input overhead : 即fuzzer生成的随机数据,没有一个bit对固件运行是相关的,事实上,这可以用一个任意值替代,不需要fuzzer生成的随机数据。
Partial input overhead : 即,fuzzer生成的随机数据中,只有部分bits是有用的。比如访问一个4字节的内存,然而其中只有1字节是需要用到的。剩下的3字节是没有用的
对于fuzzer来说,有一部分值没有被使用到可以说是十分地浪费资源(因为每一个随机输入都是fuzzer通过变异机制得到的,都需要耗费一定的资源)。
论文作者提出一个例子帮助我们更好的理解。
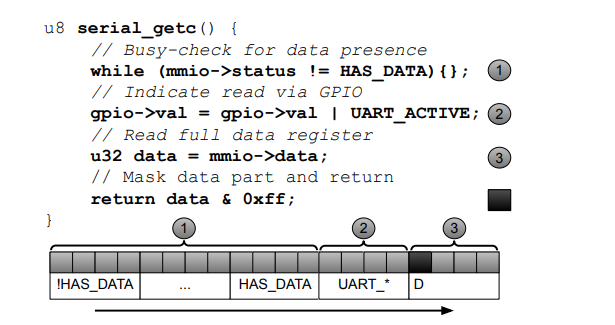 这个函数的功能很简单,首先在轮询,等待有数据进入,需要处理;
这个函数的功能很简单,首先在轮询,等待有数据进入,需要处理;
然后触发GPIO的写操作(可能是开个led灯,anyway)注意,GPIO也利用了MMIO机制
最后取了数据,返回这个数据的第一个字节。
在步骤1,对于fuzzer来说,HAS_DATA是一个4字节的值,通过随机值喂入,让他触发返回数据的逻辑是相对困难的,因为只有一个特定的值可以被接受。这是一个很典型的full input overhead的例子。
在步骤2,虽然向GPIO写入可能被视为MMIO写入操作,但GPIO位通常被打包到寄存器中,32位代表32个GPIO引脚。因此,要在不影响附近位的情况下执行GPIO操作,我们必须读取4个字节,翻转所需位,然后将结果写回。一开始读取的初始化的4字节是没有用的(也是full input overhead)。
在步骤3,你读取的4个字节中,有3个字节其实是固件运行不需要的(partial input overhead),这么算下来,咱们发现,其实fuzzer生成的随机数据,基本上都不需要用到,那生成这些数据就没有意义,耗费了时光了。
咱们再看一下另一个例子
 这个例子中,有一个
这个例子中,有一个mmio->op操作,我们需要喂入4字节的随机数据,然而只有4个选择(可以用2bits表示,这造成了partial input overhead)。另外,还有一个mmio->status操作,也需要4个字节,然而,只需要1bits就能判断这个状态。显然,这也是一个partial input overhead。而且,fuzzzer随机喂入的值能达到目标又要花费巨大时间。
2. 当前的MMIO models 方法
近几年,针对MMIO进行模拟的方法出现了很多。本质上,其实都是基于以下3种策略来解决未知外设的。
- High-level emulation:HLE跳过了对硬件外设进行模型化的步骤,因为它直接避免了MMIO访问机制。当前最先进的工作对固件代码中运行低级别的MMIO访问函数进行了抽象,通过hook,或者手工实现高级别的运行库函数的方法,在执行低级别的MMIO的时候,直接用自己实现的函数功能取代。
- Pattern-based MMIO modeling :基于模式的MMIO模型,它直接解决了MMIO访问。他们允许被模拟的固件运行MMIO访问,并且尝试使用访问模式识别的启发式方法,减少输入空间。这意味着如果观测到了对MMIO寄存器的访问,会把这个观测到访问和普通的、已经建立的模式进行匹配,并且让一个模型来处理这个访问(这个模型随后可以决定如何处理未来跟这个MMIO寄存器相关的访问)。这样的做的话,可能一个pattern就可以处理多个MMIO寄存器访问了,缺点是,可能导致模拟不精确。
- 基于符号执行引导的模型方法: 这个方法改善了上述的Pattern-based MMIO modeling方法。 不是用一个静态的基于启发式方法的pattern,对MMIO的访问被视为符号值。当访问MMIO寄存器的具体值被需要时,潜在的符号变量会基于 最期待的路径(约束)求解出合适的值。这可以提高固件逻辑的覆盖率。
本篇论文的作者指出,当前的3个方法有以下的问题存在。
1. 每个固件的人工耗费(Per-firmware manual effort)
2. 不完整的开销去除(Incomplete overhead elimination)
3. 有路径去除现象(Path elimination)
- 每个固件的人工耗费: 先去提到的3个方法当准备特定固件的fuzz策略时,都需要耗费一定的人力。举个例子: 这包含了创建HAL抽象层,修正分类错误的MMIO寄存器,或者识别alive的符号值,去除dead符号值,来引导符号执行引擎。尽管最近的方法部署了启发式方法来减少人力耗费,论文作者注意到,在实际场景中,固件相关的知识仍然是需要的,限制了符号测试的灵活性。
- 不完全的开销去除: 尽管在去除
full input overhead上是很有效的,基于模式的方法大体上 假设硬件的行为 都是基于固件“正常”运行的经典惯例(而不是考虑固件实际的运行逻辑)。然而,它们不能够识别一个输入的哪个部分被固件使用到。即,它们不能去除partial input overheads。 从1. Input Overhead的第一个例子来看,因为pattern-based MMIO modeling方法缺少固件内在逻辑的了解,它们没有意识到实际上4个字节的随机输入中,有3个字节是没有用的。因此,这些方法不能消除75%的partial input overhead。尽管不完全的开销去除 并不影响 re-hosting本身,它在模糊测试时会存在一个问题: 一个模糊器需要花费相当数量的数据来 突变一些对程序逻辑没有影响的值。- 路径去除现象: 尽管
guided symbolic execution-based approaches减少了大量的输入开销,它们也乐意地留下固件某些特定的部分(在fuzz期间并不会探索这些分支),即 从固件中去除了一些可达的执行路径。
总的来说,HLE模拟把固件的所有部分用抽象层取代,pattern-based MMIO 可能会错误地分类某种类型的寄存器,或者错误地把一个给定的MMIO访问归类为一个不相关的pattern model。Guided symbolic execution-based approaches使用启发式方法和人工视野来决定哪个路径是值得探索的。
尽管 路径消除在固件rehosting过程中是允许的,它可能会造成模糊测试中的严重后果。首先,去除特定路径可能导致大量的固件程序中的函数不可达,结果反而导致了不可分析。即使猜到了正确的pattern models,路径消除现象会影响错误处理和恢复的函数,这部分函数可能也包含bug,而且不应该被忽视。更进一步,我们认为 在常规的固件行为和错误处理函数中进行区分是一个不可决定的问题。在大部分样例中,通过复杂的诊断和恢复操作,固件逻辑可能会满足错误条件。 与此同时,不引人注意地等待异步事件的常规固件行为可能表现为不执行任何有意义操作的无限循环,这也不运行任何有意义的操作。这直接反映在最先进的解决方案上,这些解决方案在没有人工协助的情况下会陷入执行停滞。
根据这些见解,我们得出结论,一个有效的模糊测试重新托管解决方案必须避免路径消除,同时减少每个固件的手动工作量,并消除尽可能多的输入开销.
fuzzware设计
在下文中,我们介绍了FUZZWARE的设计,这是一种通用的固件模糊方法,允许模糊器通过精确消除部分和全部输入开销来有效地探索固件行为。
为此,我们将建模建立在轻量级程序分析技术的基础上,这些技术使我们能够发现硬件生成值的部分使用。为了分析固件代码的行为,我们使用了动态符号执行(DSE)。DSE允许我们生成一组约束条件,表示硬件生成值的所有可能用途。
通过评估这些约束,我们可以缩小模糊器要探索的值集。通常,由于状态爆炸问题,使用符号执行进行建模会带来高计算成本。我们通过在本地使用DSE来避免这一缺点,其中DSE仅用于在特定MMIO访问的上下文中执行代码。我们随后会描述限制DSE范围的细节。
1. Prerequisites and Threat Model(前置条件和威胁模型)
FUZZWARE具备以下前提条件和威胁模型:
前提条件。FUZZWARE与所有其他重新托管系统共享两个基本先决条件:首先,我们假设我们能够获得目标设备的二进制固件映像。其次,就像其他重托管系统一样,我们假设提供基本的内存映射,如RAM范围和广泛的MMIO空间。根据目标CPU体系结构,这些通用范围可能是标准化的。
威胁模型。在不了解给定二进制固件映像的特定硬件环境的情况下,我们假设在模糊测试期间攻击者能够控制提供给固件的输入。通常,这些输入可能对应于通过MMIO读取的传入网络数据包的内容、通过串行接口接收的数据或温度测量等传感数据。
2. fuzzware的模拟器组件
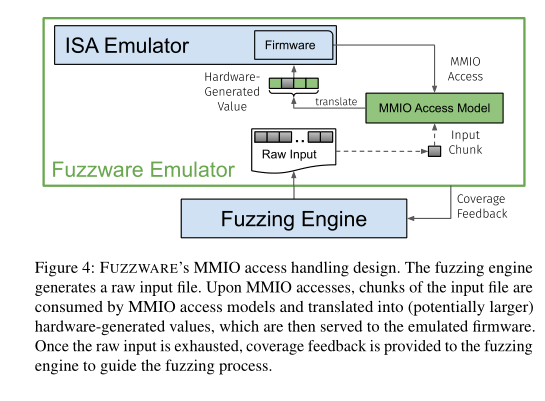
现在我们描述FUZZWARE仿真组件的设计。图4显示,从高级的角度来看,FUZZWARE使用ISA模拟器和覆盖引导的模糊测试引擎(fuzzer)。由于FUZZWARE旨在消除部分输入开销,我们引入了访问模型,这是一种将少量模糊输入位转换为对固件逻辑有意义的值的机制,同时消除了过程中的输入开销。
我们通过加载一个给定的monolithic firmware的镜像文件给 ISA模拟器。我们设置了一个harness来动态地拦截所有MMIO访问,即 由被模拟的固件运行的所有在MMIO地址范围内的内存访问。这个harness被提供了一个输入(即一个空白的二进制文件),这个输入是由基于覆盖率引导的fuzzer生成的。随后,harness开始代码的模拟,这个输入被分成几个块来服务于MMIO的访问.无论何时固件代码运行了一个MMIO访问,harness会检测我们是否已经对这个特定的访问委派了一个MMIO访问模型。如果一个模型是可用的,并且是可以依赖于输入开销的类型,harness能够处理这个访问,而没有花费任何的fuzz生成的输入(full input overhead);否则,harness能够花费一个输入的一小块,并且把它翻译成一个由硬件生成的值(partial input overhead)。这个硬件生成的值随后被使用来服务MMIO访问。模拟器继续运行直到生成的输入已经耗尽而且不再能服务MMIO访问。我们将这个模拟步骤命名为emulation run,因为一个emulation run被归纳好了,harness可以通过清除状态来恢复固件,并且把先前一轮的覆盖率的反馈报告给fuzzer。基于这个反馈,fuzzer生成另一个输入,并且把它提供给harness来进行下一轮emulation run
然而,在模拟的期间中,如果一个特定的MMIO访问没有模型来委派,那么生成的输入会被直接用来当做硬件生成的值,没有通过翻译步骤。在进行模糊测试的通知,FUZZWARE会为每一个新发现的MMIO访问上下文(当前程序运行地址以及MMIO地址的元组),生成一个模型。在一个分离的模拟器实例中,我们为固件的状态(例如寄存器和内存)创建了一个快照,就在MMIO访问的之前。我们使用符号执行来从这个快照中派生一个匹配的模型,随后我们用新的模型来重新配置模拟器,这允许fuzzer在更少的输入开销下更有效的发现进一步的逻辑。
我们通过不提供初始MMIO访问模型来引导这个模糊循环。当模糊器处于活动状态时,模型不断生成并添加到仿真器配置中。该设计提供了一个通用的、自适应的固件仿真环境,允许模糊测试引擎以最小的输入开销来探索未知的固件。
3. 建模方法
就像先前解释过的,每个MMIO访问上下文,我们会创建一个访问模型。为了达成这个目标,我们会重放能够让新的MMIO访问被指向的输入,就在固件将要运行MMIO访问之前,给这时的模拟器的寄存器和内存状态拍摄快照。我们将这个快照传给我们的DSE引擎来建模,并且从这个快照开始,符号化地运行代码。每个在符号执行期间被观察到的MMIO访问都会被当成一个独自的符号变量。
建模分析的范围 我们会跟踪第一个MMIO访问(当然还有相同的访问上下文中的其他 MMIO访问),以跟踪是否所产生的符号变量还存在,即,至少要有一个符号表达存在于内存中,或者一个寄存器值仍然依靠它。这个符号执行会一直运行直到如下的情况发生:
- 所有被跟踪的符号变量都以及不存在了。
- 当前函数返回了
- 一个跟踪的符号变量移开了分析的范围(即,它被写入了全局内存或调用堆栈中一个更高的函数栈帧中
- 一个预先定义的计算资源以及达到了。(即,超时,符号状态的数量,或者DSE的步骤数量达到了)
使用这些退出条件,我们把DSE限制到一个小的、可管理的范围,在这范围内,我们可以观察固件采取的所有基于MMIO访问的动作。同时,我们并没有为超过这个范围的硬件生成的值建模。这一范围界定决策背后的基本原理是 MMIO寄存器状态的短暂性,这强迫固件频繁的访问MMIO并且很快地忽视硬件生成的值。
直到碰到了其中一个退出条件,建模逻辑会分析生成的符号状态。每一个符号状态都代表固件代码依赖于硬件生成的值运行的一个可能路径。一个符号状态有一个不同的路径约束的集合,即硬件生成的值需要满足的条件,还有包含被跟踪的仍然存在的符号表达式。这些符号状态随后被使用来作为输入来委派和配置 被分析的MMIO访问的模型。
模型设计考虑 基于先前的讨论,有2个方面对我们的模型设计来说是重要的:首先,模型需要提供可复制的翻译。在给定一个fuzzer生成的输入条件下,运行一个emulation run多次都必须要产生一样的固件执行。我们要求一样的行为,因为我们为在单独的模拟器实例中建模而生成MMIO访问快照,并与正在进行的模糊测试并行。为了保持翻译的可重复性,我们只从模糊输入块中获得硬件生成的值。
第二,我们设计我们的模型是为了保存固件代码路径,尽管我们立志于消除尽可能多的输入开销,我们保守的运用模型而不至于 在进程中 让固件代码的路径不可达。因此,我们只基于我们可以完全观察到的变量使用来建模访问。在活动变量离开我们的分析范围的情况下,我们基于固件逻辑已经在建模变量上放置的约束(例如,在返回数据之前已经应用了位掩码)来建模。
错误处理和执行停滞 自然地,通过保存所有的固件代码路径,我们运行fuzzer执行错误路径。这是有意为之的:与先前的建模方法相反,我们显式地不 给特定的路径做优先级划分,或者去除一整条看起来不怎么令人感兴趣的路径。相反,我们认为处理异常条件的代码也可能包含bug,并且同样的需要被包含在分析之中。这不可避免地导致输入导致固件执行停滞。然而,我们注意到这些情况是由fuzzer无缝处理的:每当执行停滞时,fuzzer将识别缺失的代码覆盖率。因此,相应的输入将被视为无趣而丢弃,并且突变引擎将快速生成具有更大代码覆盖率的输入。我们想要强调,这些有意识的决定来探索错误处理函数 不仅可以发现之前没发现的bug,也可以构建 固件自动fuzz的真正的鲁棒性,因为既不需要人类分析师也不需要启发式来识别有趣的路径。
4. fuzzware模型定义
我们定义了5个通用的MMIO访问模型,它们可以从DSE生成的一组符号状态中被分发。这些模型中的每一个都为仿真器提供了一个蓝图,说明如何处理特定的MMIO访问并系统地全部或部分地消除输入开销,无论是典型的基于控制流的MMIO使用(即,根据值采取不同的操作)还是基于数据的MMIO使用(即,读取数据并删除全部或部分数据)。其中一些通用模型接受定制参数。我们使用符号状态首先分配一个通用模型,然后通过给定MMIO访问的参数实例化它。通用模型包含模拟器的规范,说明如何应用模型参数来确定硬件生成的值。对于处理全部输入开销的模型,仅模型参数就足以处理访问,而无需消耗任何模糊输入。对于处理部分输入开销的模型,仿真器需要模糊化输入来应用模型。在这些情况下,它使用模型的参数将模糊输入块转换为硬件生成的值。
现在我们详细介绍五个通用模型。对于每个模型,表1显示了它处理哪种类型的输入开销(overhead)、使用哪些参数(parameters)、访问消耗多少原始模糊处理位(# fuzzing bits)以及模型如何使用参数将原始模糊处理输入转换为硬件生成的值(Output)。

- 常数模型。该模型描述了使用特定常量作为比较的一部分的MMIO访问,必须满足该常量才能继续执行(上述图片中的①)
- 直通模型。此模型分配给硬件生成值确定不影响固件状态的访问。我们将MMIO访问视为常规的内存访问。例如,这些包括对配置寄存器的访问(上述图片的②)。
- 位提取模型。当固件只使用从MMIO读取的部分位时,使用位提取模型。例如,如果从MMIO寄存器中读取四个字节,并且应用位掩码只保留几个位,而丢弃其他位(参见上图中的③),就会出现这种情况。请注意,对于位移位、截断和等效指令组合也会发生类似的效果。示例:使用模型计算的位掩码0x00ff0000执行4字节宽的MMIO访问。仿真器消耗一个字节的模糊输入,例如0x4e。模拟器将0x004e0000作为硬件生成的MMIO访问值。对于位掩码0xfff0000f和消耗的原始输入块0xabf8,模拟器提供0xabf00008。
- 设置模型。set模型处理这样一种情况:将硬件生成的值(一部分)与不同的值进行检查,以确定控制流。如果可以预先计算出离散的值列表,使得每个值恰好代表可能的控制流选项之一,则应用该模型。一大块原始模糊测试输入被解释为模糊器从每个单独访问的不同选项中做出的选择。可能的实例包括状态和标识寄存器,其中固件根据硬件生成的值执行不同的操作(参见下图)。
- 身份模型。如果DSE确定硬件生成值的所有位都是有意义的(即,由固件使用),则分配此模型。在没有约束的符号变量脱离分析范围的情况下,或者在DSE没有在其资源限制内完成的情况下,它也被用作回退。在这些情况下,我们保守地假设硬件生成的每一位值以后都可能被固件使用。因此,我们允许fuzzer尝试所有值,从而发现所有固件路径。在实践中很少需要这种回退。
5. 中断,定时器和DMA处理
如中断是固件逻辑的异步输入源。由于ISA模拟器不包含任何引发中断的外设概念,因此这种行为必须由FUZZWARE触发。默认情况下,FUZZWARE在执行一定数量的基本块后以滚动方式引发每个当前启用的中断。在执行期间,通过检查CPU中断控制器的状态来跟踪启用的中断集。
在其他外设行为中,FUZZWARE以这种方式模拟基于中断的定时器外设。为了在探索固件逻辑如何响应特定时间事件时提供额外的灵活性,FUZZWARE允许精确控制何时以及应该引发哪些中断。
与访问模型使用模糊测试输入来确定硬件生成的值类似,模糊测试输入可用于确定下一个中断的时间及其数量。这允许模糊器发现非常具体的中断时间对固件行为的影响。
注意,FUZZWARE可以通过将传输缓冲区定义为MMIO区域来支持某些形式的DMA。然而,FUZZWARE目前没有明确地以自动化的方式建模DMA,因为这超出了本工作的范围。
implementation
我们实现了一个针对ARM Cortex-M标准的FUZZWARE原型。我们之所以选择这个平台,是因为它在实践中被广泛采用,并预计未来的流行程度。该实现的设计使得将来可以支持其他目标isa。
1. FUZZWARE的模拟器
我们的实现基于Unicorn Engine作为基础ISA模拟器,我们使用传统的AFL作为模糊测试引擎,以便与其他建模方法进行公平的比较。
我们还集成了afl++,以获得其扩展的特性集和基准性能。我们通过使用原生Unicorn API为MMIO区域注册内存访问钩子来处理MMIO访问。在执行读操作之前,我们通过将分配模型的输出写入被访问的MMIO地址来处理挂钩读访问。我们通过MMIO访问上下文(即程序计数器和MMIO地址对)将内存访问与其相应的模型关联起来。如果不存在关联模型,则默认根据身份模型处理访问。我们使用三个通用文件作为初始模糊测试输入(每个文件的大小为512字节):所有的零位、所有的位和连接的32位值,每个值移动1位。
根据经验,我们发现,在位粒度级别上消费由未修改的面向字节的模糊器提供的原始模糊输入与驱动模糊器输入突变过程的启发式冲突。因此,为了处理MMIO访问,我们在字节粒度级别上使用原始输入。例如,虽然对包含四个元素的集合模型的每次访问都需要至少两位模糊输入,但在我们当前的实现中消耗了一个字节。
定时器和中断。定时器和中断是固件执行中不确定性的来源。如先前所述,我们要求模拟运行完全可再现。为了实现精确的可重复计时行为,我们通过模拟基本块的数量来测量运行时间。我们还通过中断控制器(NVIC)和系统计时器(SysTick)的实现扩展了独角兽引擎,这是在Cortex-M标准中定义的。
2. MMIO访问建模
对于DSE,我们选择了angr作为引擎,因为它-就像Unicorn engine一样-很容易支持广泛的isa,并且适合包含更多的架构。
在将固件状态快照加载到angr中并为表示跟踪的MMIO访问的硬件生成值创建符号变量之后,我们通过引用计数来跟踪变量的活跃度。每当DSE将包含跟踪变量的符号表达式写入寄存器或内存时,就增加引用计数,每当重写这样的表达式时,就减少引用计数。
为了跟踪来自具体恢复状态快照的寄存器值赋值是否会影响建模结果,我们在加载快照后污染寄存器。
在达到上文中描述的退出条件后,我们检查结果状态上的活动符号表达式和约束,以确保遵守下面详细介绍的每个模型定义。
- 常数模型:所有跟踪的变量不再被引用,但约束结果状态。对于最近跟踪的变量,在所有结果状态之间存在一个单一的公共值v,具有以下属性:对于任何上一个变量,赋值v不满足状态约束。常数v是模型的参数。
- 直通模型:所有跟踪的变量不再被引用,并且不约束任何结果状态。
- 位提取模型:在每个状态下对每个跟踪的符号变量应用位掩码后,所有状态约束和符号表达式保持不变。汉明权重最小的位掩码将模型参数化。
- 设置模型:不再引用所有变量,而是约束结果状态。对于每个状态和引用计数变量,可以找到一个不满足任何其他状态的路径约束的值。换句话说,每个路径上的约束集合形成了状态之间输入空间的分区。每个分区的最小代表被选为配置集合中的一个值,它将模型参数化。
- 身份模型:以上模型均不适用,或者没有在DSE范围内找到模型。
如果应用多个模型,则选择输入开销减少最多的模型。作为DSE计算的限制,我们将每个模型的默认运行时间设置为5分钟,并将最多1,000个符号执行的基本块设置为5分钟,我们发现这在实践中工作得很好。