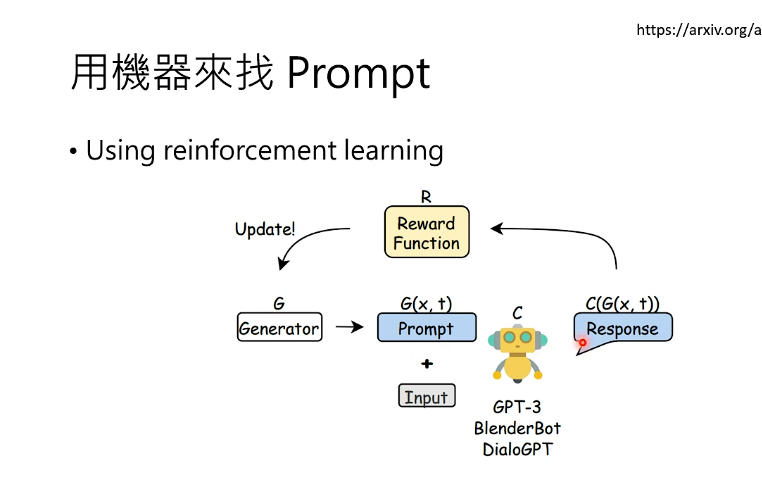
前言:对于大语言模型的期待
讲到大语言模型,除了当今比较流行的Chatgpt以外,还有一个重量级项目,就是Bert
1. Chatgpt vs Bert
其实chatgpt本质上是文字接龙,而Bert本质上是文字填空,这就衍生成了我们对大模型的2个不同期待:
专才(Bert)和通才(chatgpt)
专才很容易理解,就是让大模型解决某一个特定的任务,比如说翻译、提取摘要。
通才也很容易理解,就是让大预言模型能够做到各种事情,比如又能做翻译,又能提取摘要,你想让它做啥它就做啥。
专才的好处就是,专才在某一特定任务的执行情况下,通常会比通才做的更好
通才的好处就是,重新设计prompt(让模型做什么事),就可以快速地开发新功能,不用再写程序了
专才(Bert)
对于专才,通常的做法是在预训练模型Bert的基础上做一些改造
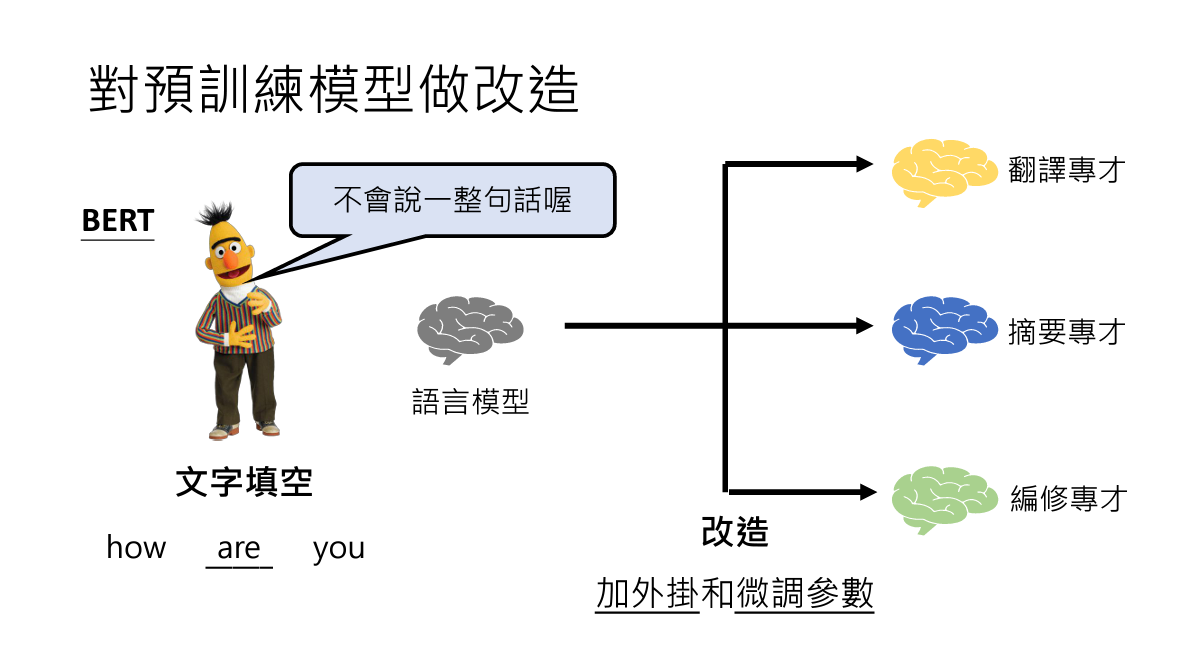 从图中可以看到有2种改造方法,加外挂和微调参数
从图中可以看到有2种改造方法,加外挂和微调参数
1. 加外挂
其实外挂顾名思义,是一些Bert中有提供的办法,这里不做详细了解
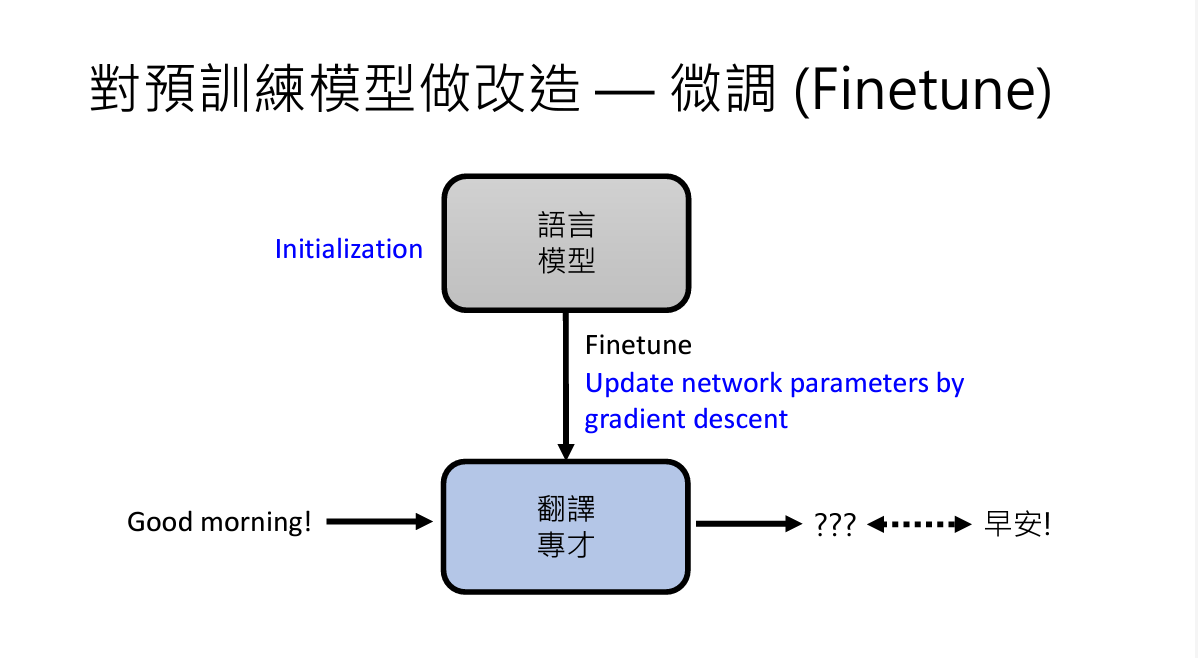
2. 微调参数(Finetune)
顾名思义,做微调
从头开始训练模型时,initialization的设置是随机的,要通过训练,得到较好的结果。
我们在已经训练好的模型的基础上再进行一些训练,就叫做微调,其实finetune本质上还是在做gradient descent
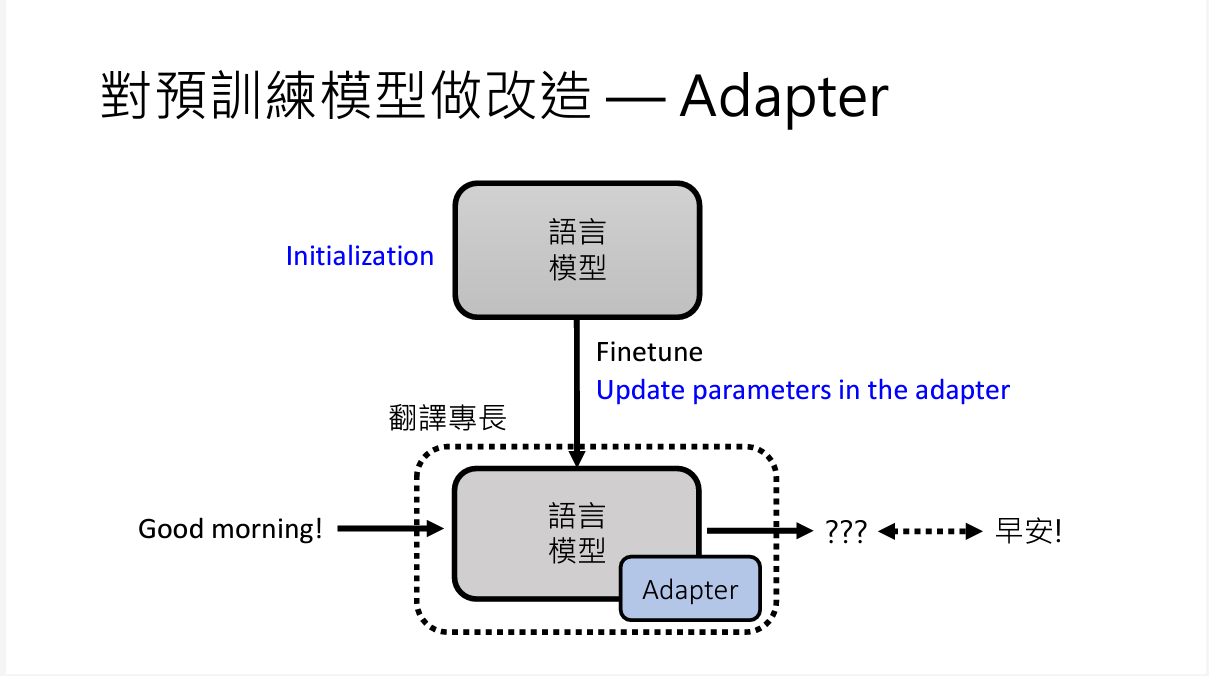
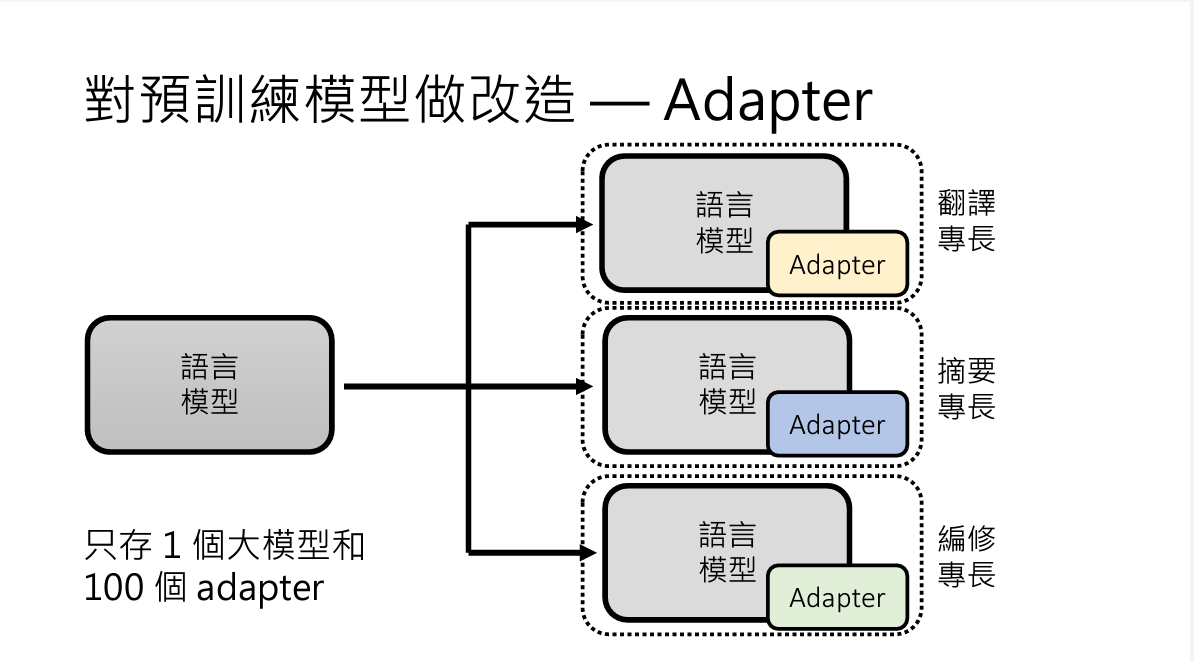
3. adapter
adapter本质上其实还是微调参数的办法
大概就是,如果你对一整个模型做微调,参数还是比较多的。
但是你给这个模型额外设置一些参数,当成一个adapter,你在微调的时候只需要训练adapter中的额外参数就好了,比较省事
adapter的另一个好处是,如果你要在一个大模型上开发100个不同的专项模型,你可能需要保存100个训练好的专项模型,如果模型很大,就很占空间啦
如果使用adapter的话,你只要保留一个大模型和100个adapter就好了,adapter比模型小很多,能够节省资源
通才(chatgpt)
chatgpt朝着通才的方向努力,一个模型能够做很多事情(如果你有用chatgpt,你也能感受到它的强力)
为了让模型能够做通才,有很多训练办法
主要思路有,让模型读范例(In-context Learning)和让模型读题目描述(Instruction tuning)

1. In-Context Learning
让模型读范例然后做其他题目的方法,叫做In-context Learning
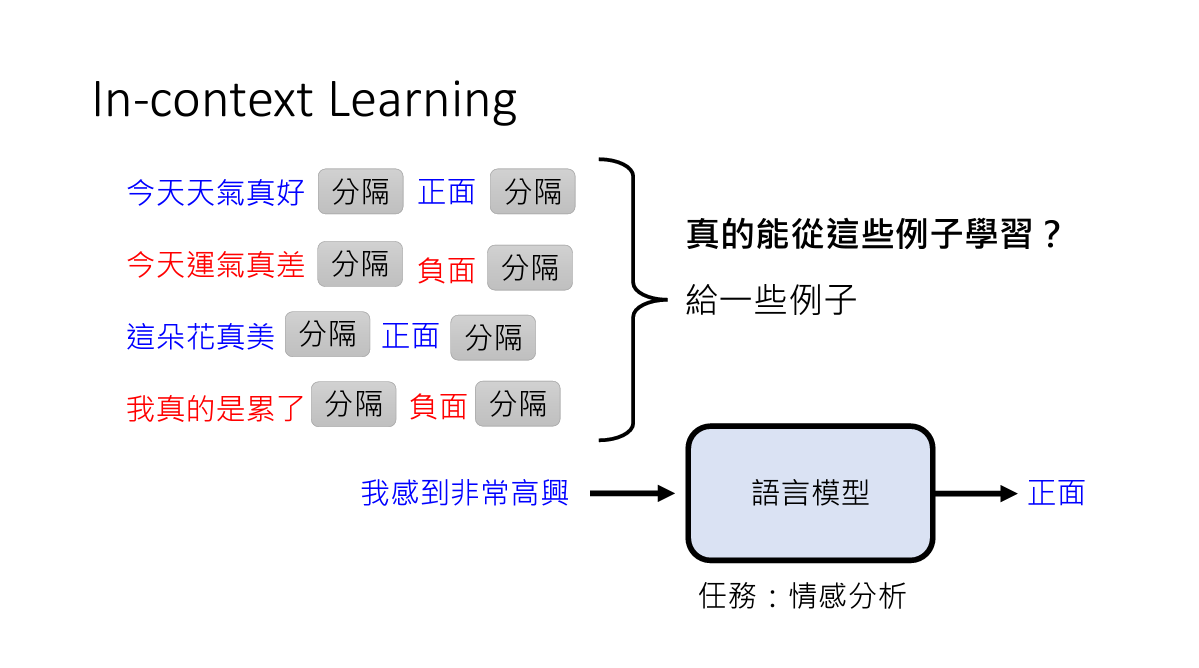 其实这个方法还遭到了质疑,在小模型情况下,可能学不到什么东西,然而在大模型的情况下,这个方法还是有效果的
其实这个方法还遭到了质疑,在小模型情况下,可能学不到什么东西,然而在大模型的情况下,这个方法还是有效果的
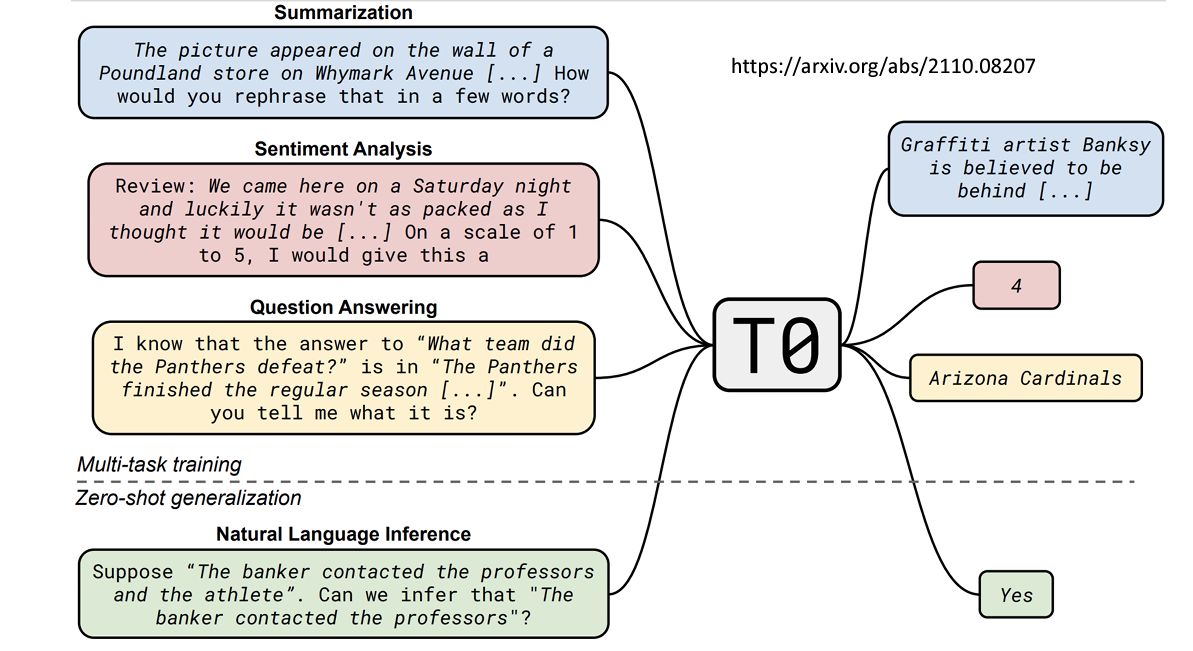
2. Instruction tuning
当模型试图理解题目表达的含义,叫做Instruction tuning
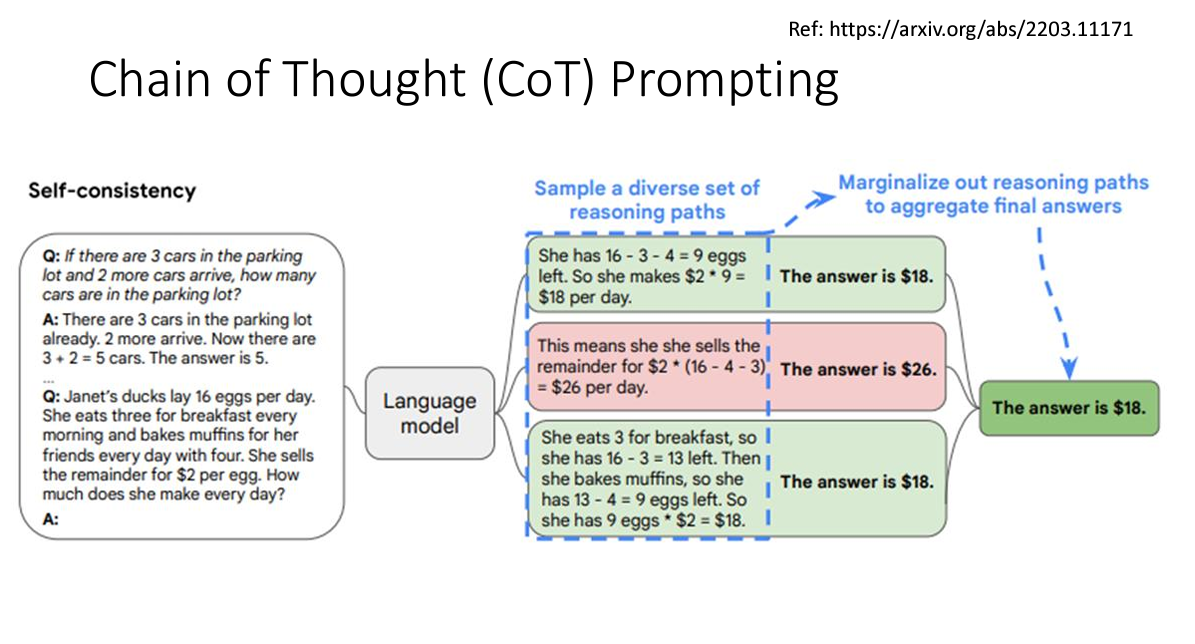
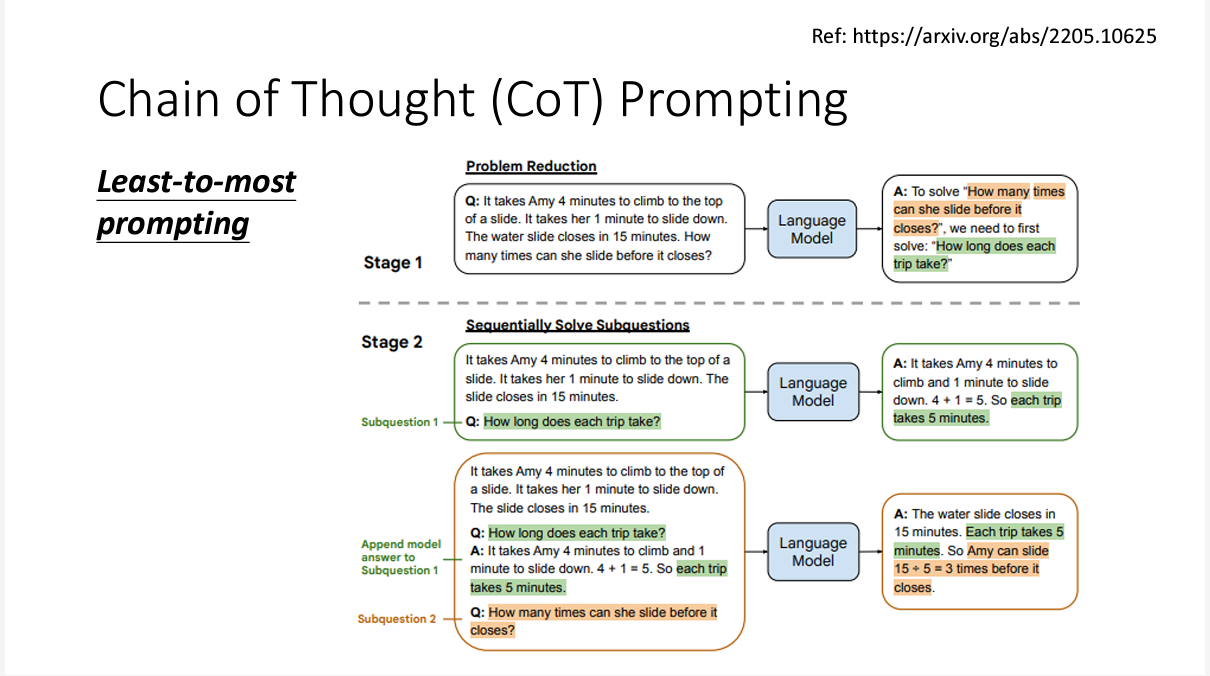
3. Chain of Thought(COT) prompting
这个方法非常的神奇啊,大概就是让大模型回答问题的时候,让它输出推理过程(如何得到答案的),大模型的回答正确率就大大提高了。
 这个方法还有许多的配套方法
这个方法还有许多的配套方法
比如Self-consistency让模型重复推导同一个问题的答案,选一个最多被推导的答案作为最终答案输出
 还有叫做
还有叫做Least-to-most-prompting的方法,这个方法让模型学会将一个问题拆解成小问题来解决
还有一个神秘的方法,让模型自己寻找最合适的prompting