Deep Learning
Deep Learning其实也服从常规的计算方法
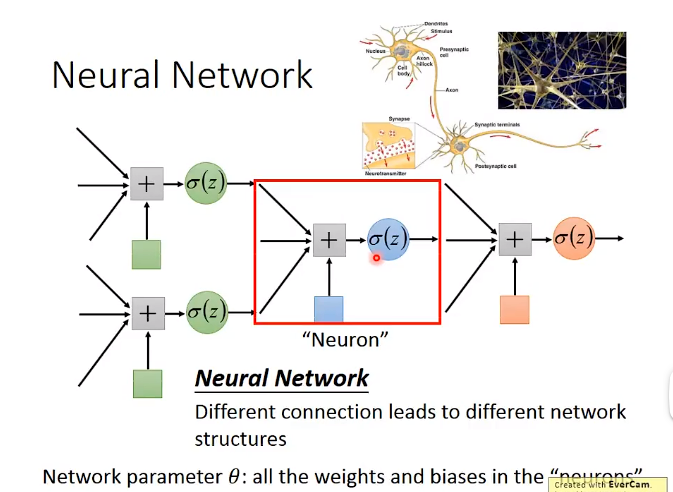
 而且之前的介绍也说过,
而且之前的介绍也说过,Deep Learning其实是Logistic Regression的堆叠
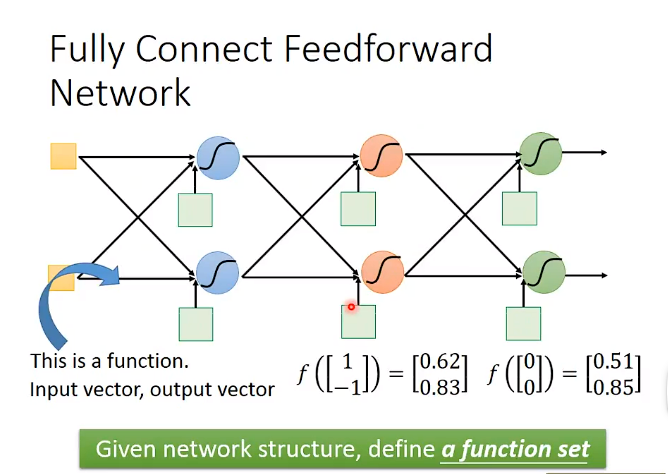
1. Fully Connect Feedforware Network
Fully Connect Feedforware Network是深度学习中一种常见的链接方式。
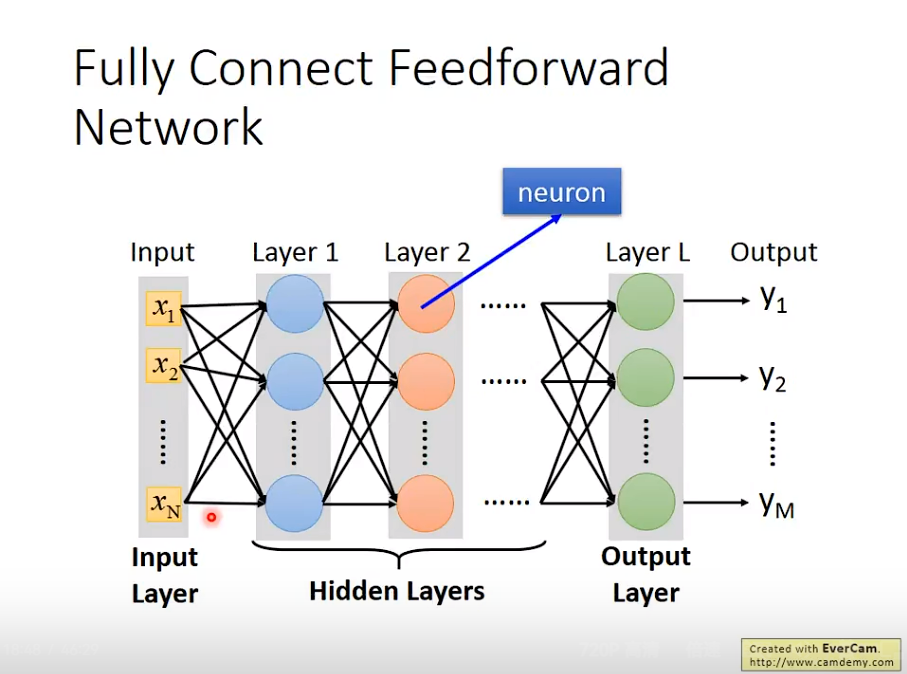
2. 本质
本质上,深度学习是矩阵运算
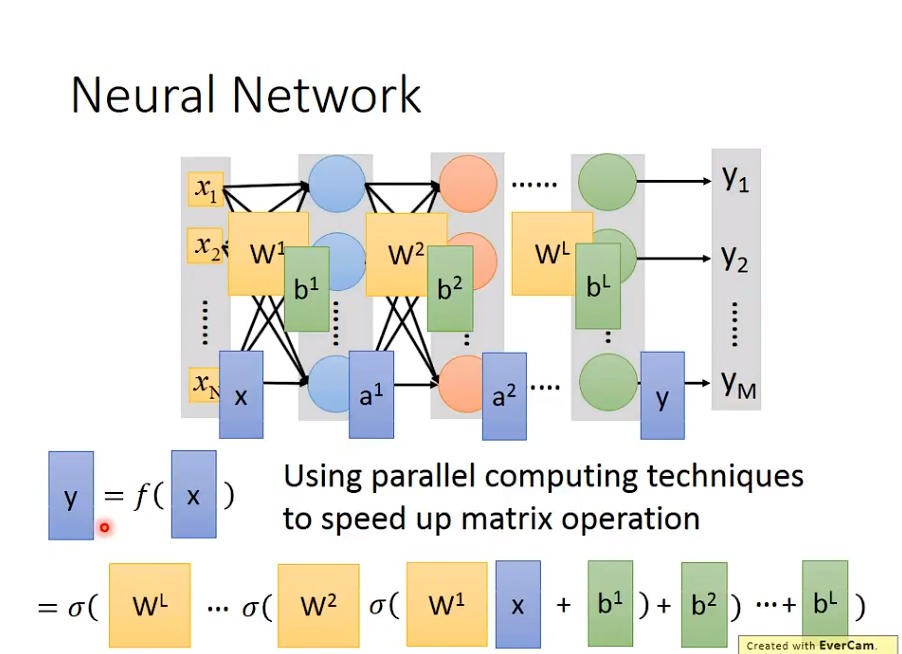 使用
使用GPU可以加速。
并且,其实很符合Logistic Regression的逻辑
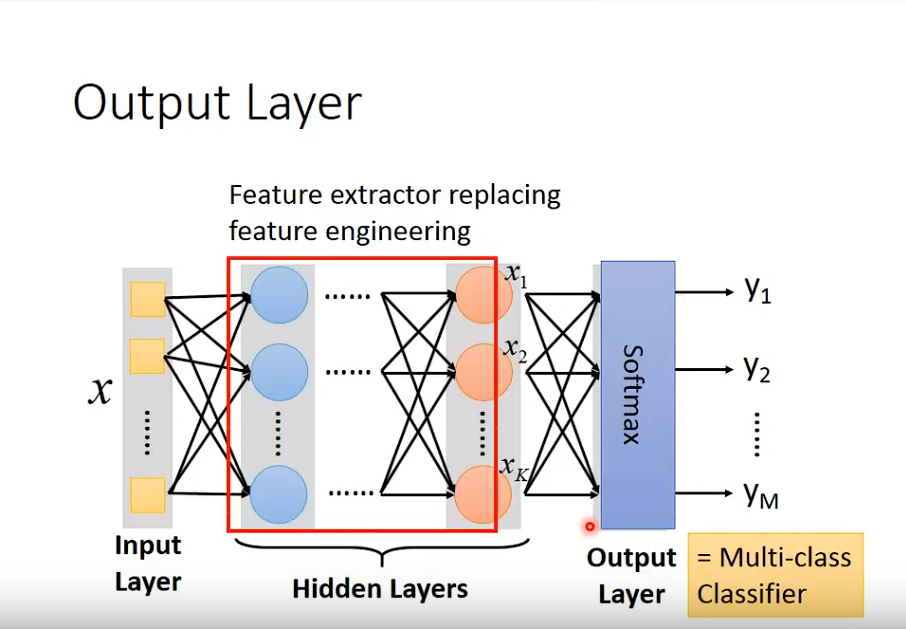
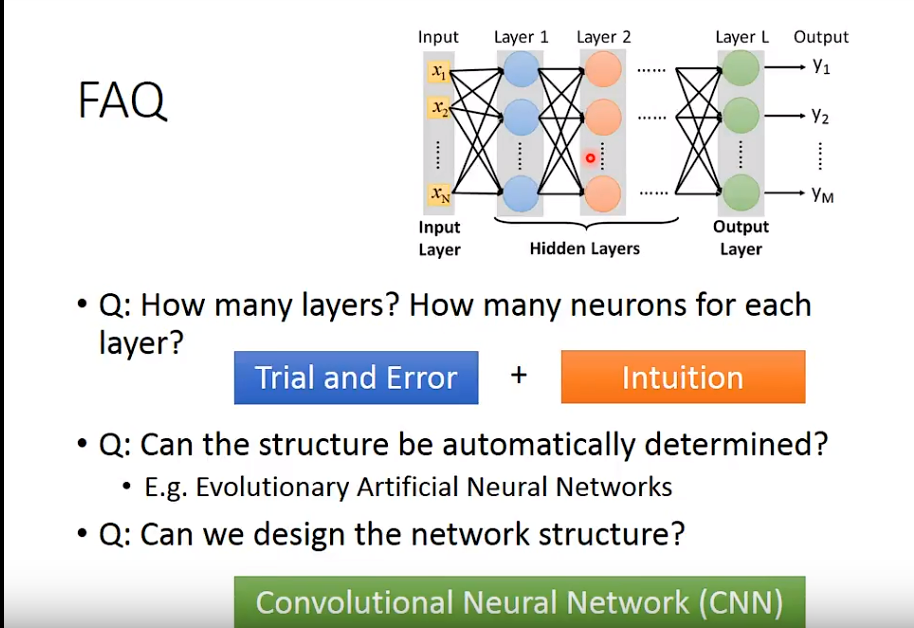 其实还有一个最重要的问题:
其实还有一个最重要的问题:
深度学习,Hidden Layer越多越好,其实是一个很直觉的结果;即使不用深度学习,参数(parameters)越多,模型效果比较好是很正常的;那么用深度学习有什么优势吗?

Gradient Descent
Gradient Descent有许多小tips要学习。
1. Learning Rate
首先关于Learning Rate,必须要调整其为合适的值。
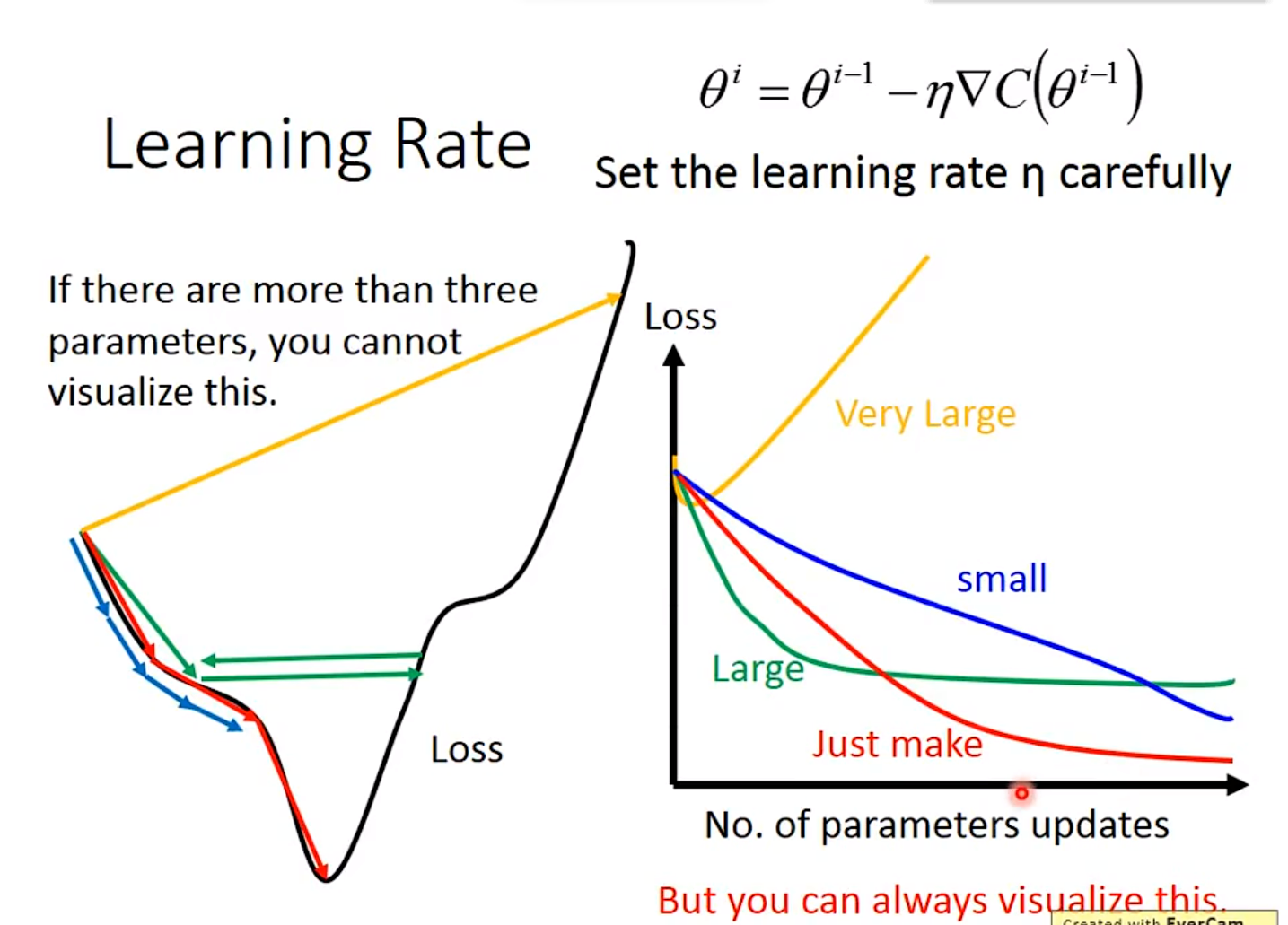 自己手动调整比较麻烦,于是出现了自动调整的办法
自己手动调整比较麻烦,于是出现了自动调整的办法
 比较好用的是叫做
比较好用的是叫做Adagrad的办法,原理如下图所示。


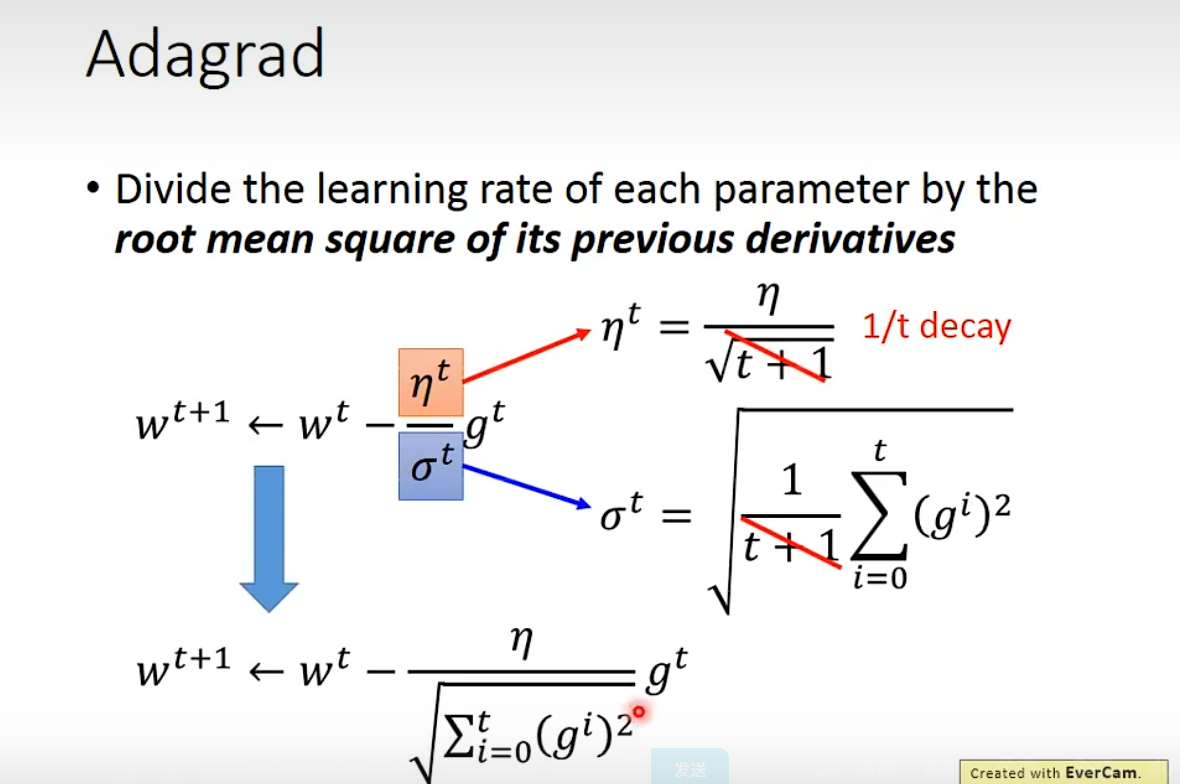 Adagrad是当前比较稳定的方法
Adagrad是当前比较稳定的方法
Adagrad为什么比较好呢?
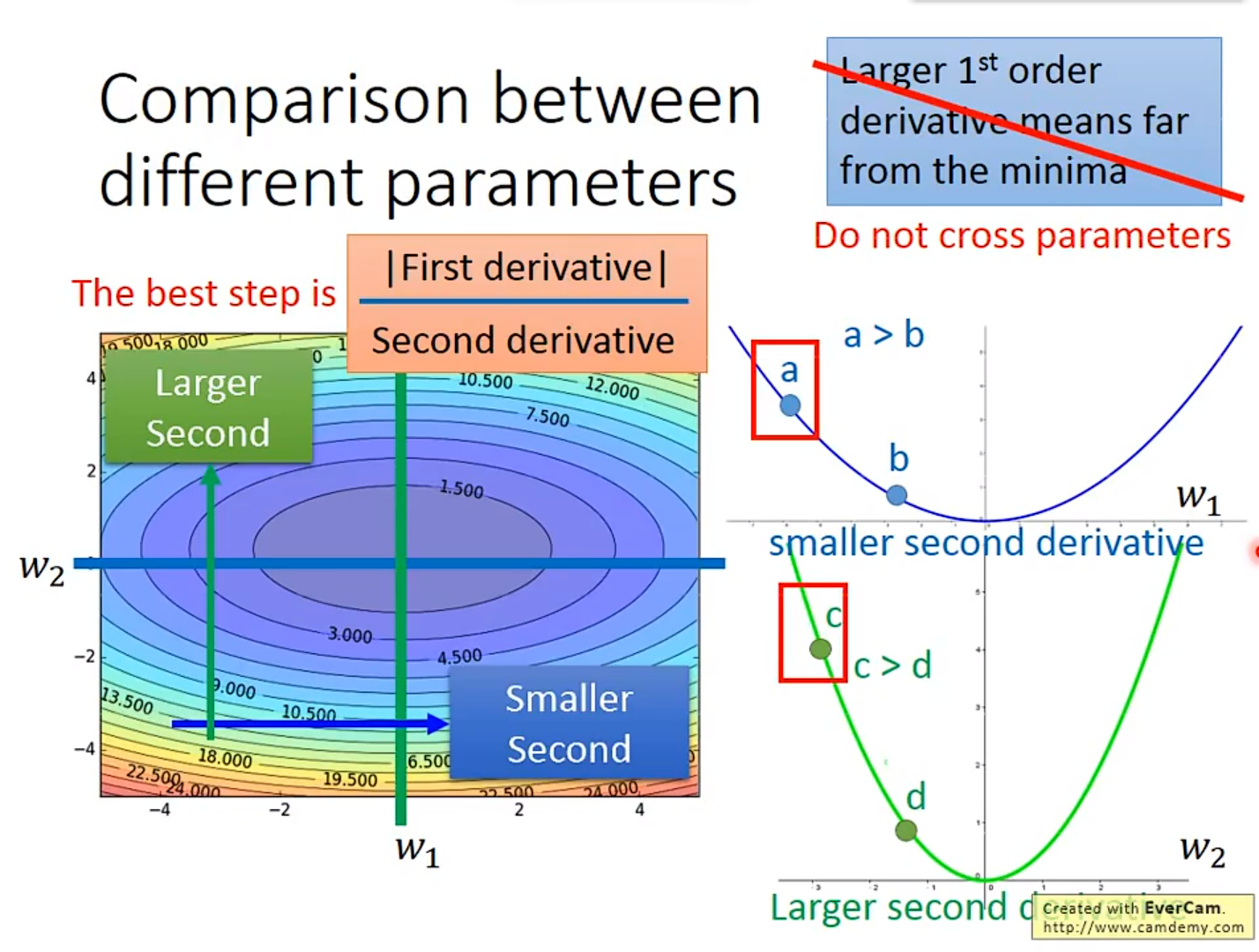
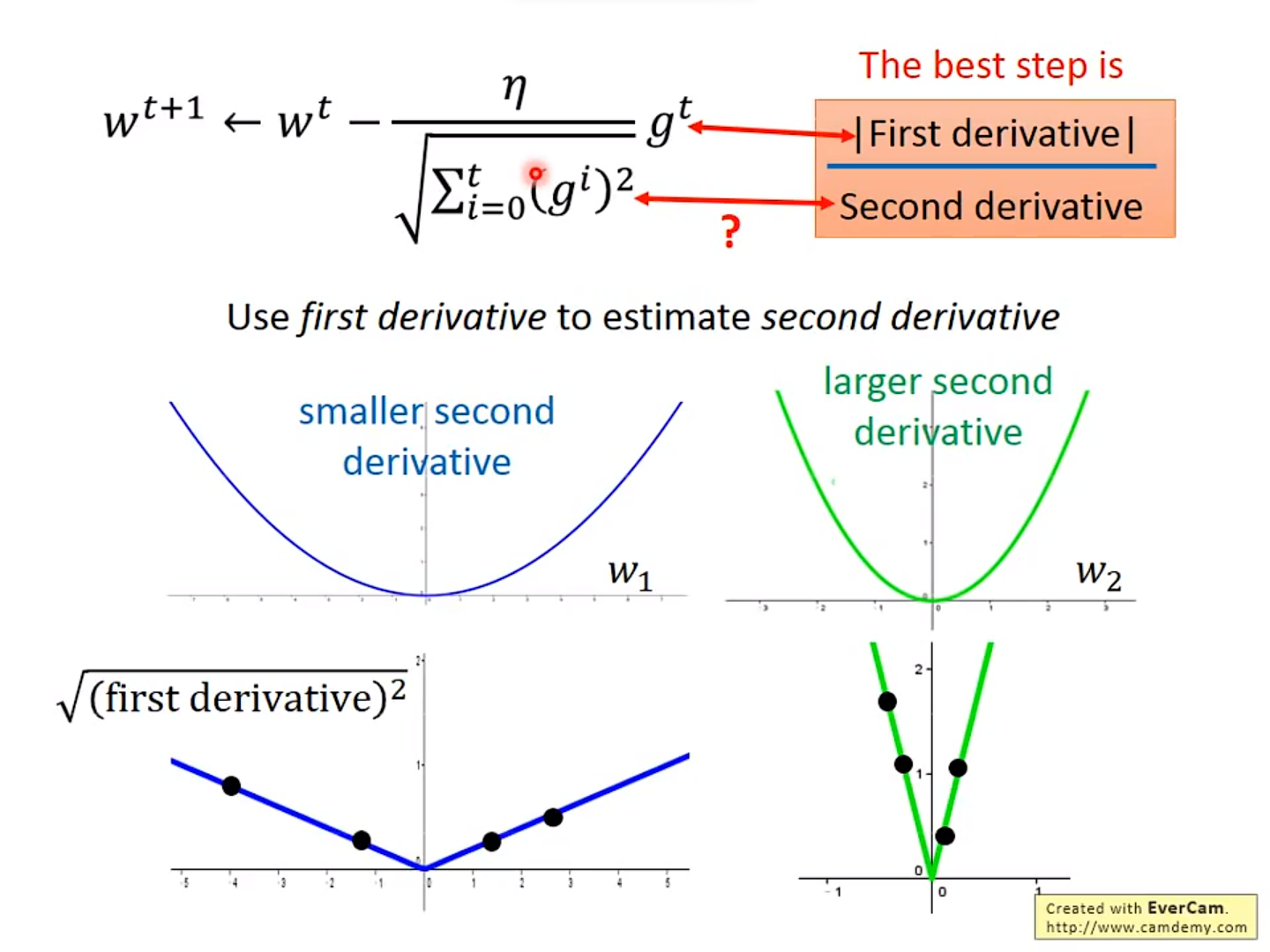
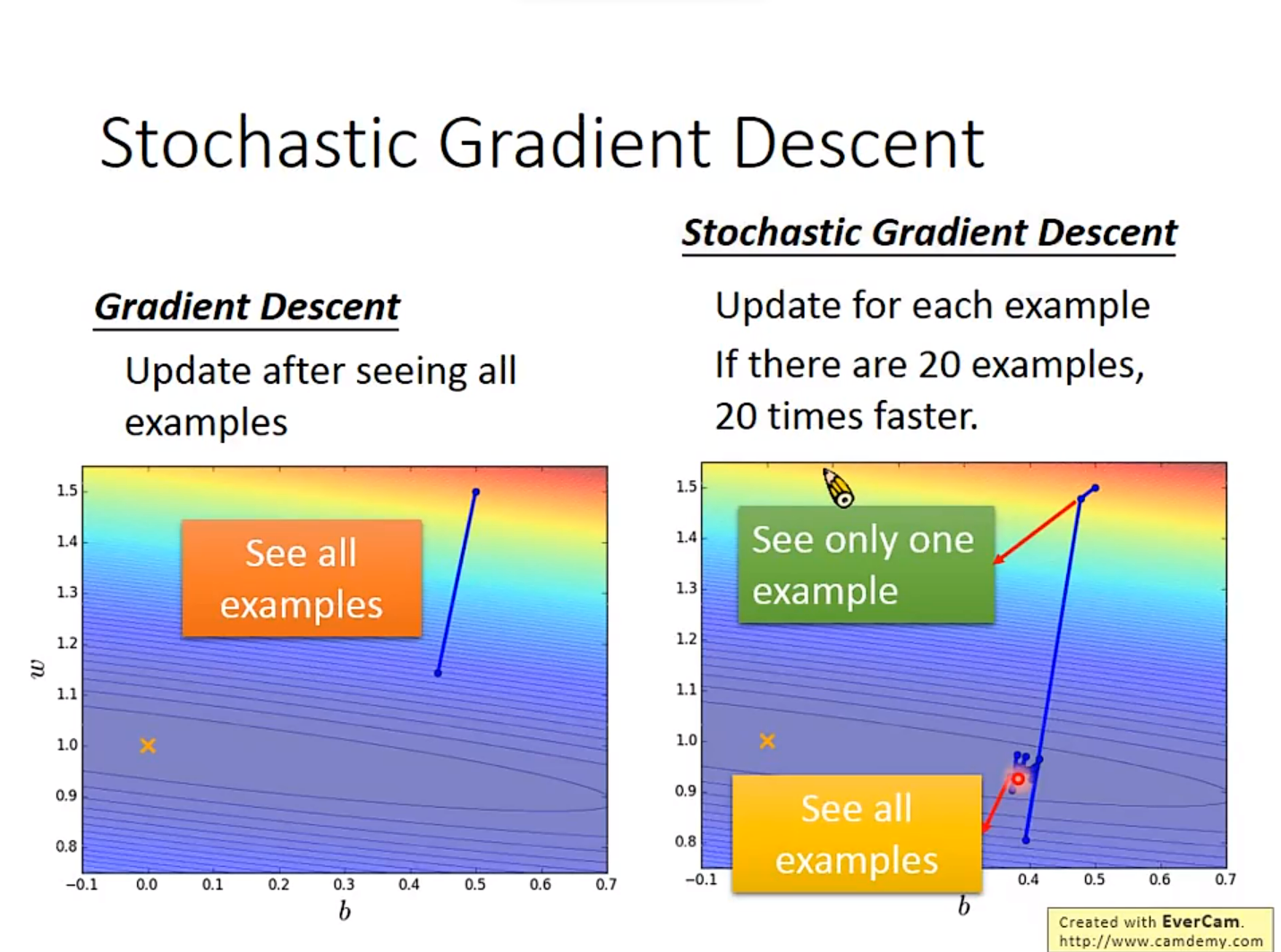
2. Stochastic Gradient Descent
这是一个很神奇的Gradient Descent方法,主打的就是一个唯快不破

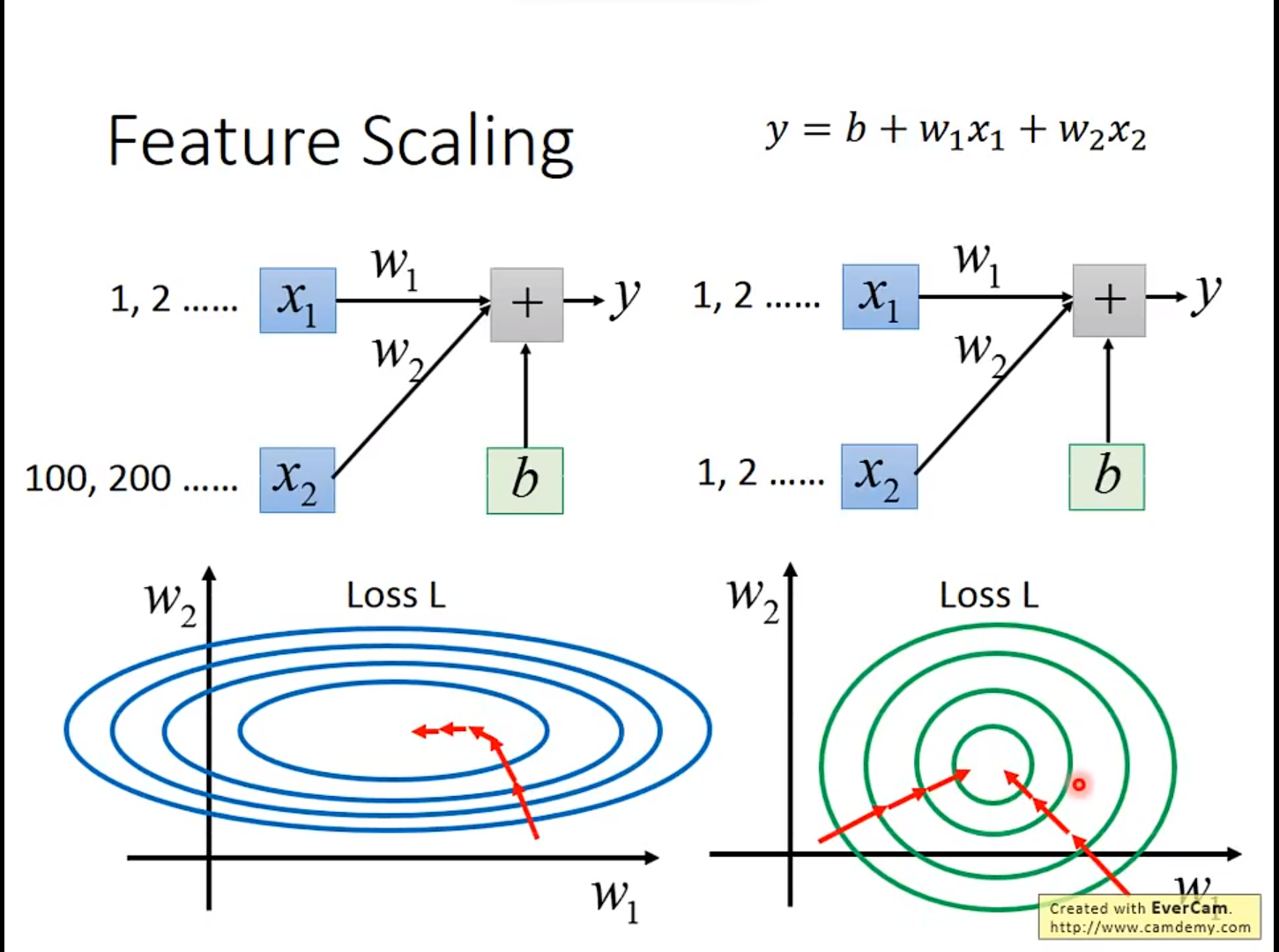
3. Feature Scaling
这个技术的使用场景发生在:不同权重对Loss Function的影响不一样,导致做Gradient Descent效率不够快时。如果每个权重的影响相同,那么做Gradient Descent时,效率十分快。
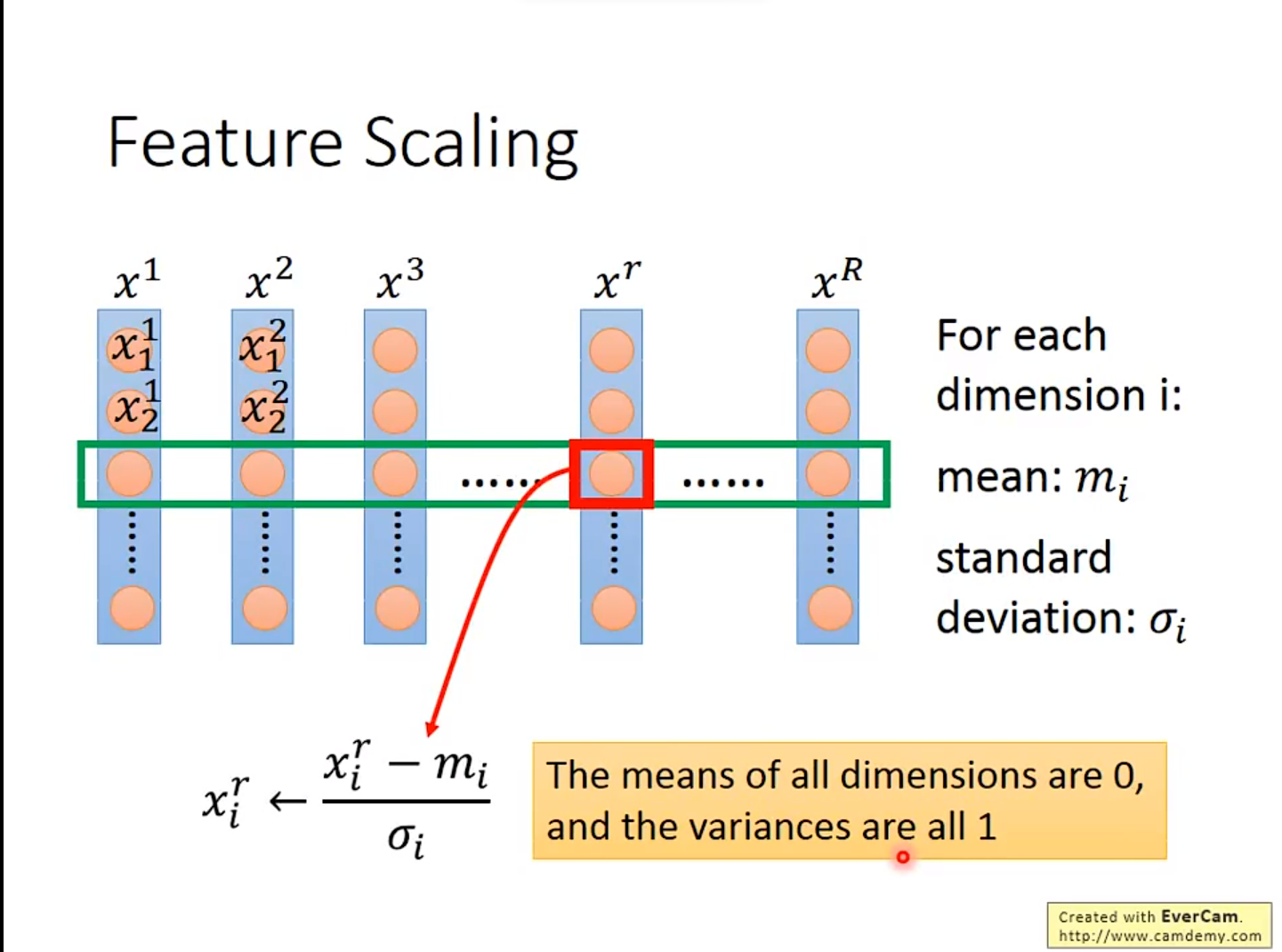
 一种常见的办法是
一种常见的办法是
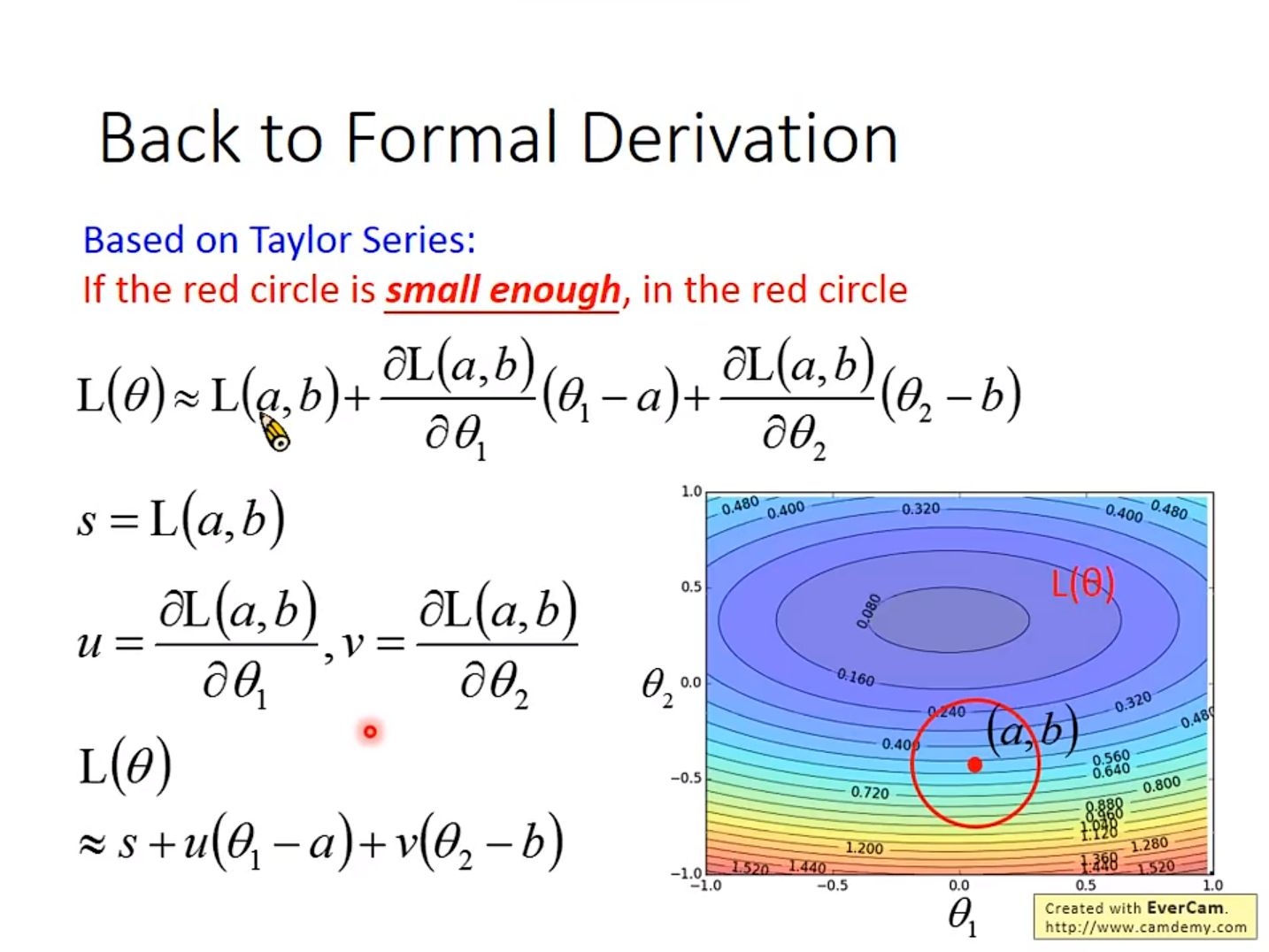
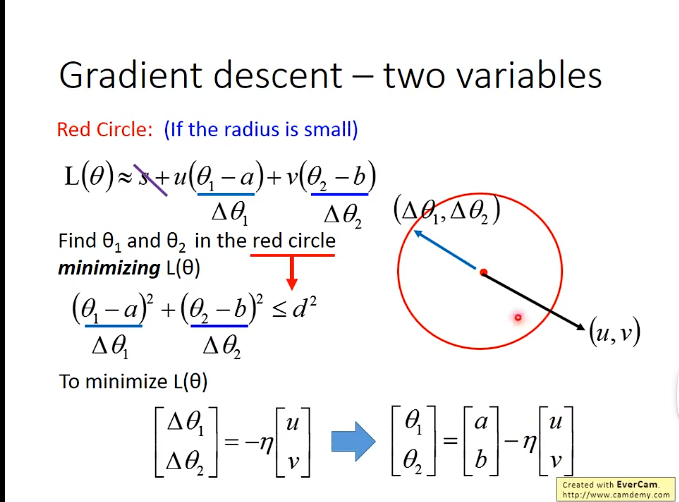
4. Gradient Descent的数学定理
基于泰勒公式

 举个实际的例子
举个实际的例子


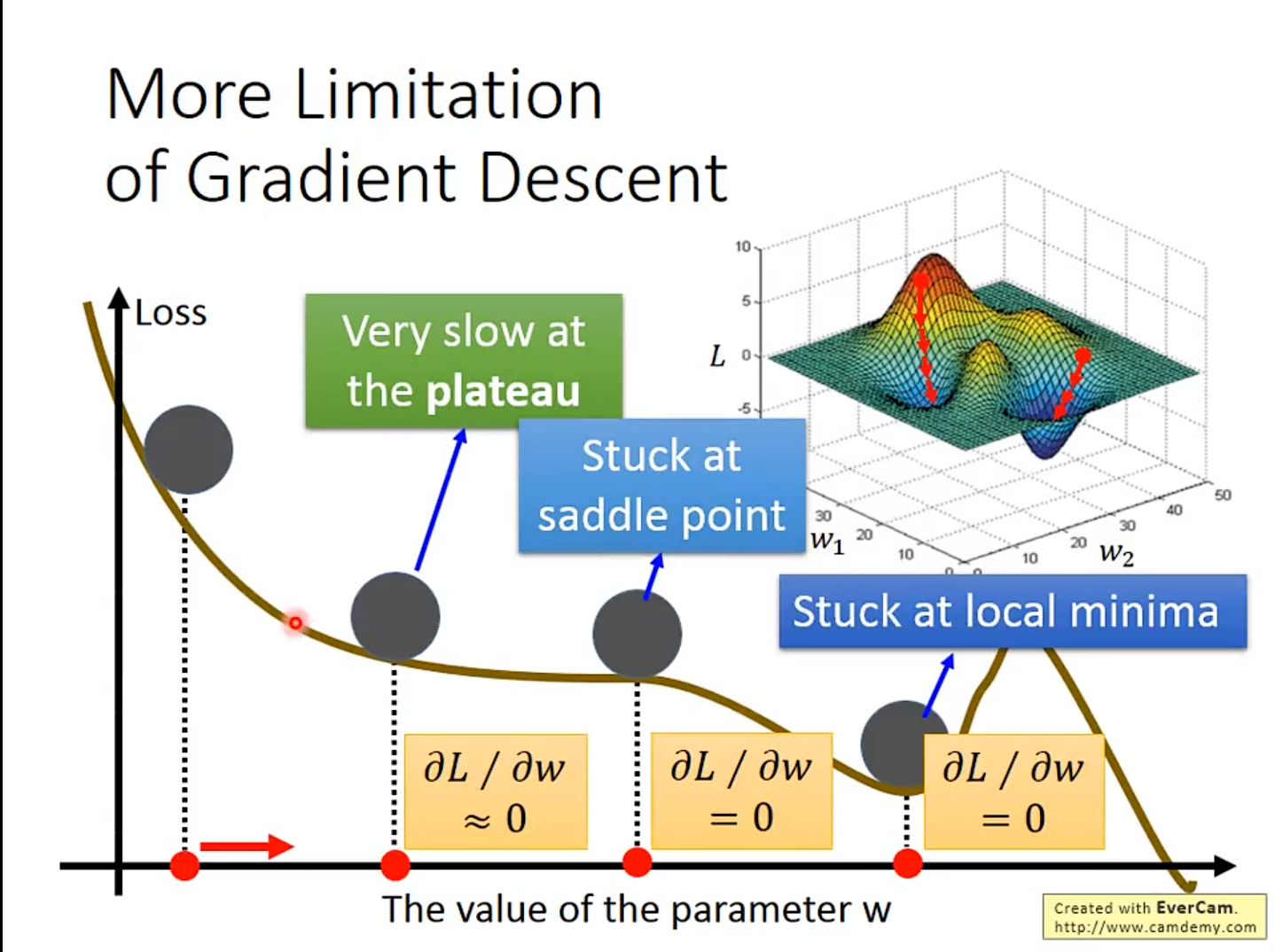
5. Gradient Descent的限制
会卡在Local minima(局部最低点)的地方
实际上更严重,因为实际计算时,基本上算不出来微分是0的位置。
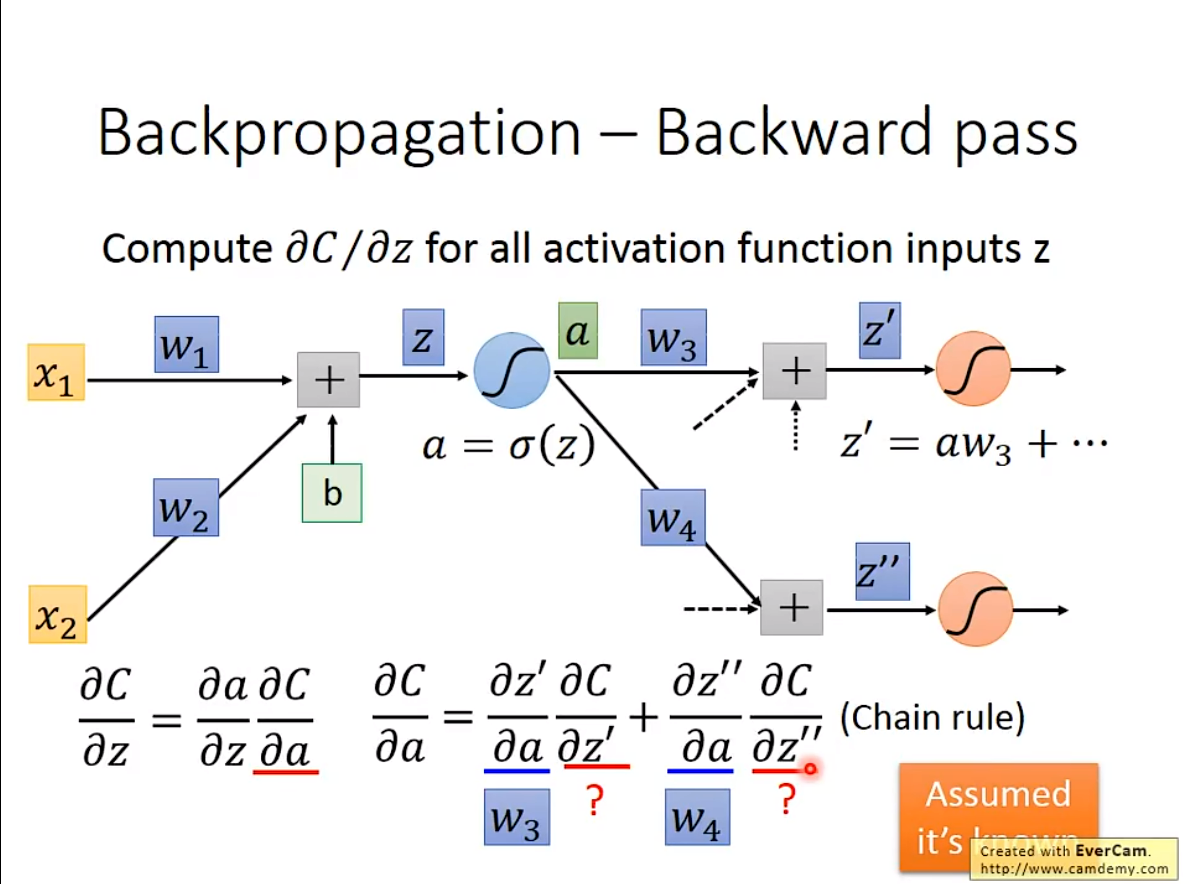
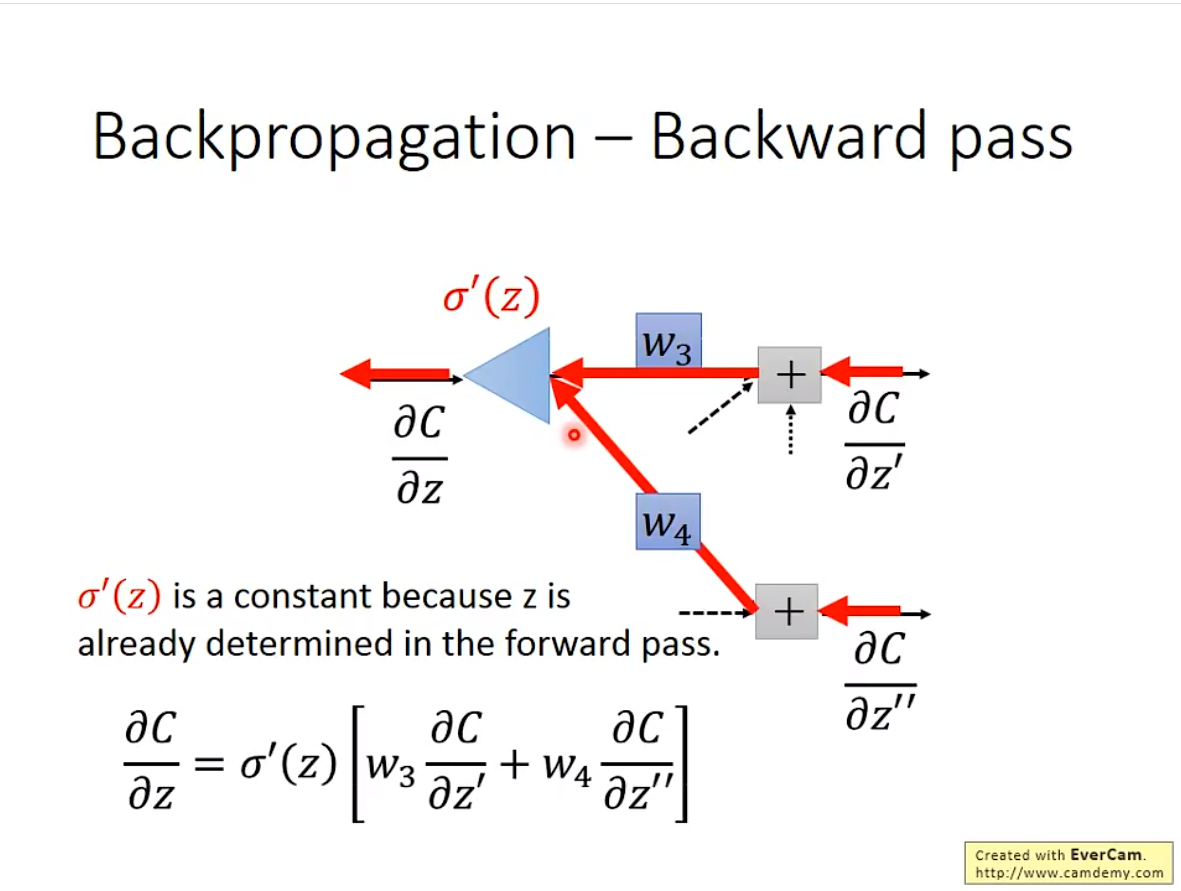
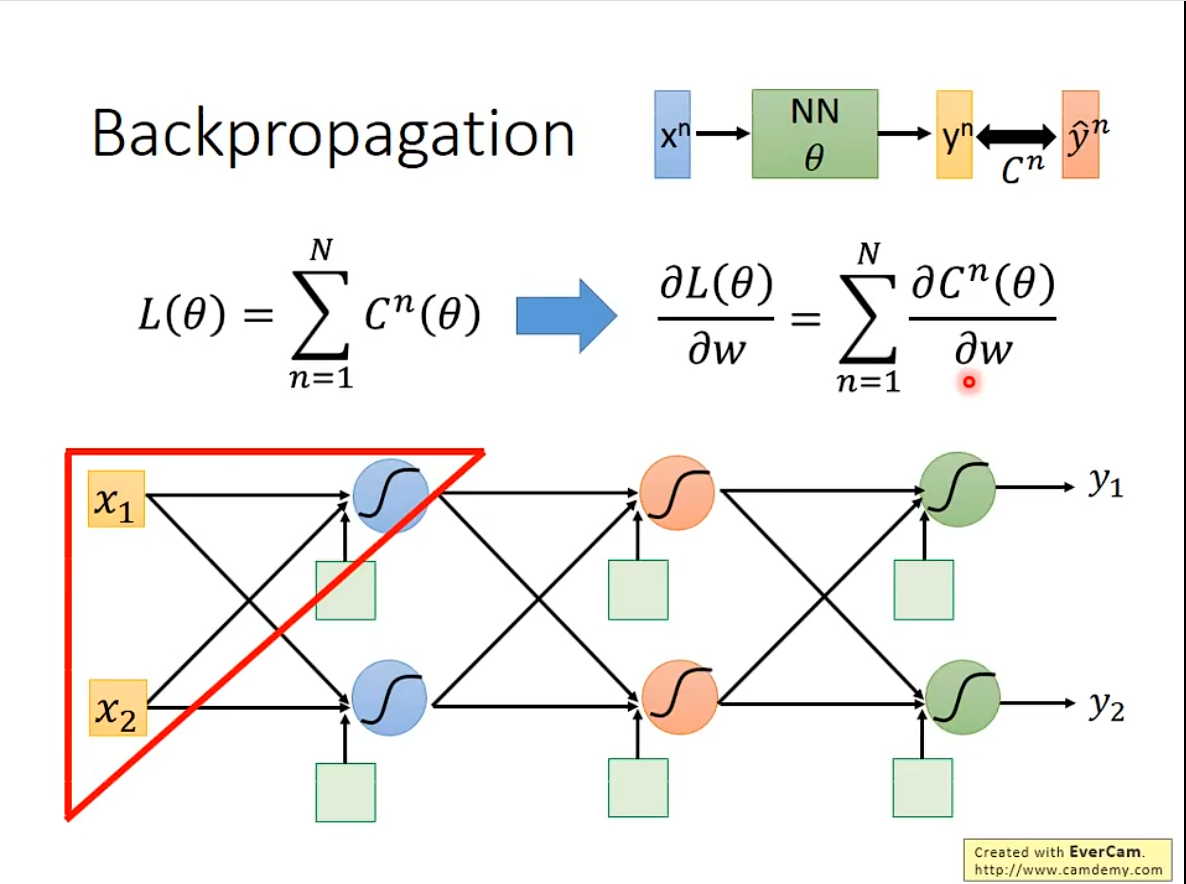
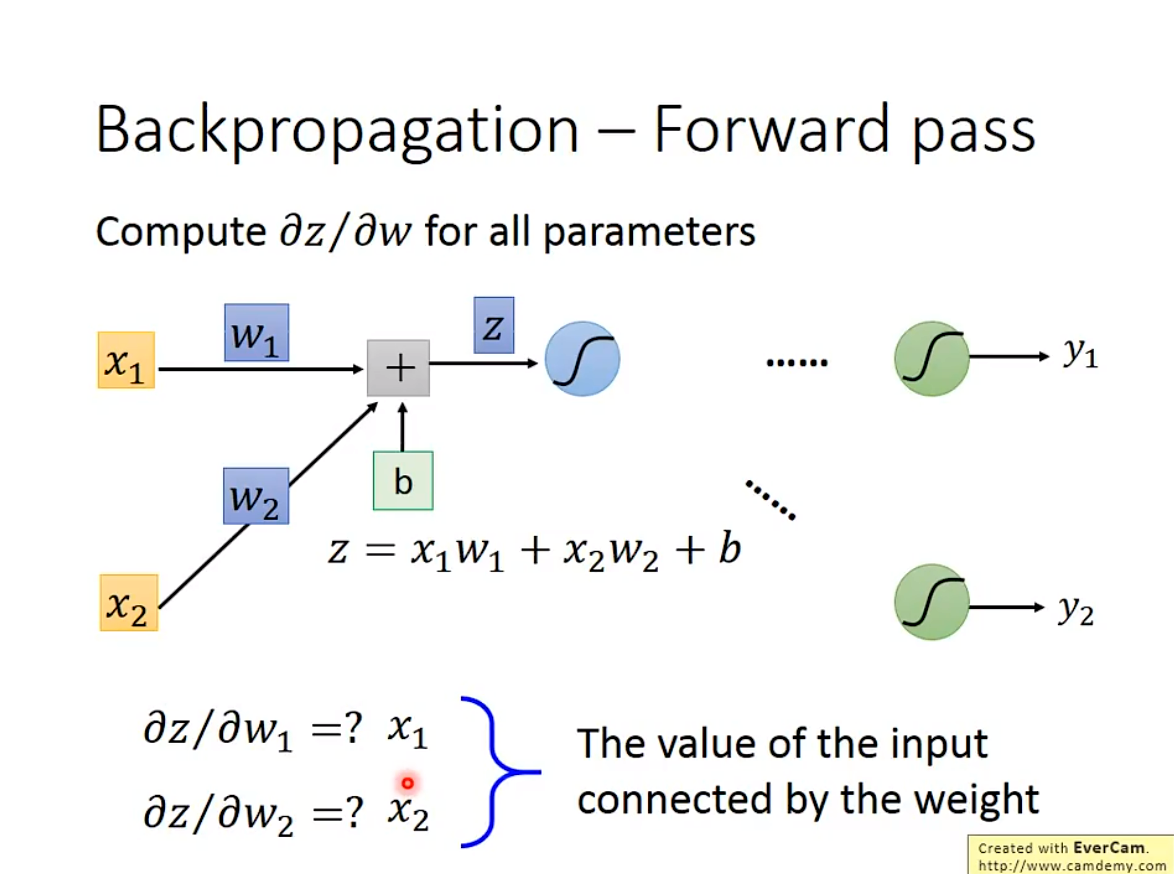
Backpropagation
Backpropagation,其实是更有效率的计算Gradient Descent
在一个neural network里,大模型参数都有几百万,算起来太复杂了。于是就有了这个东西。
1. 基本原理
 接下来给一个实际例子。
接下来给一个实际例子。
 通过上述的规则转换,得到如下结果
通过上述的规则转换,得到如下结果
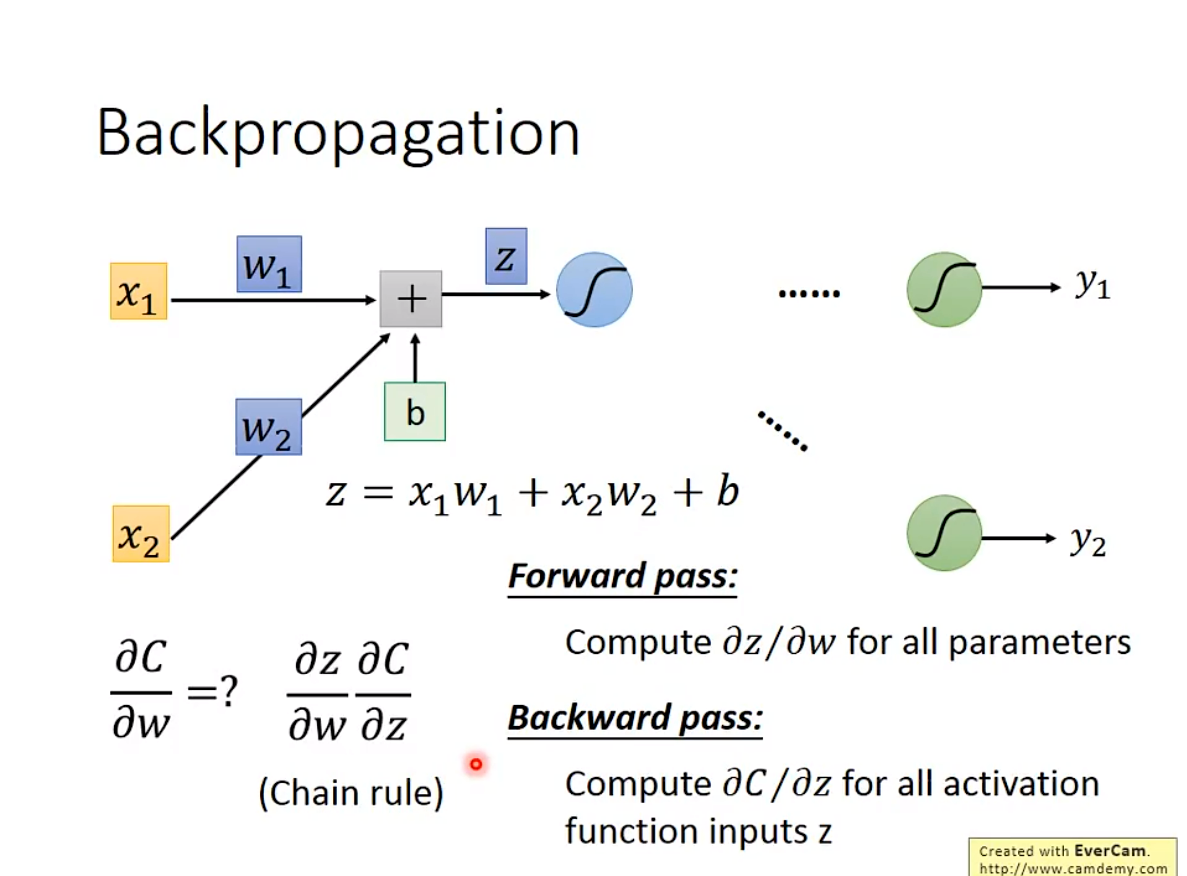
2. Forward pass
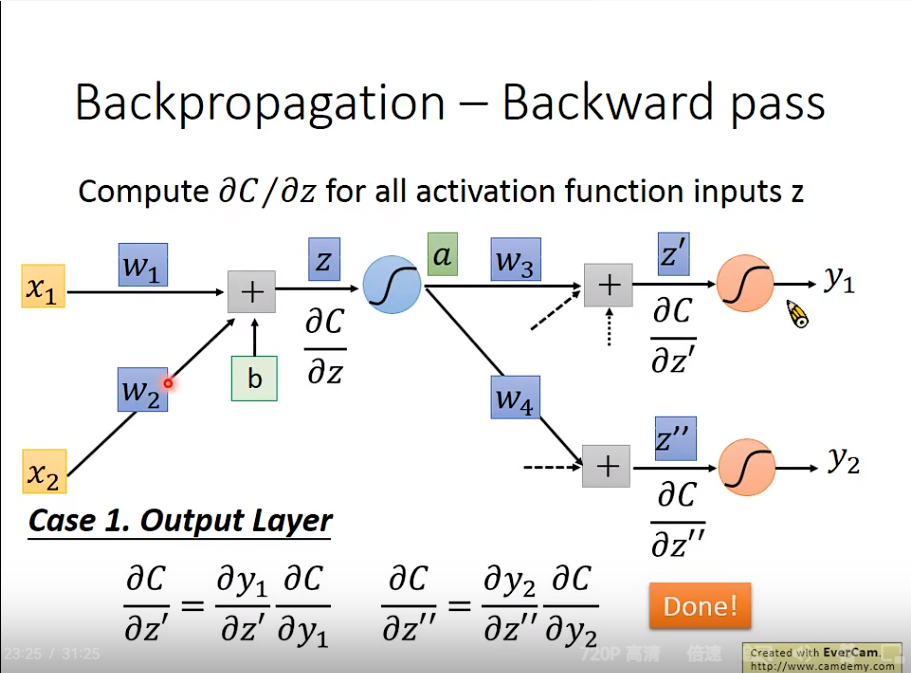
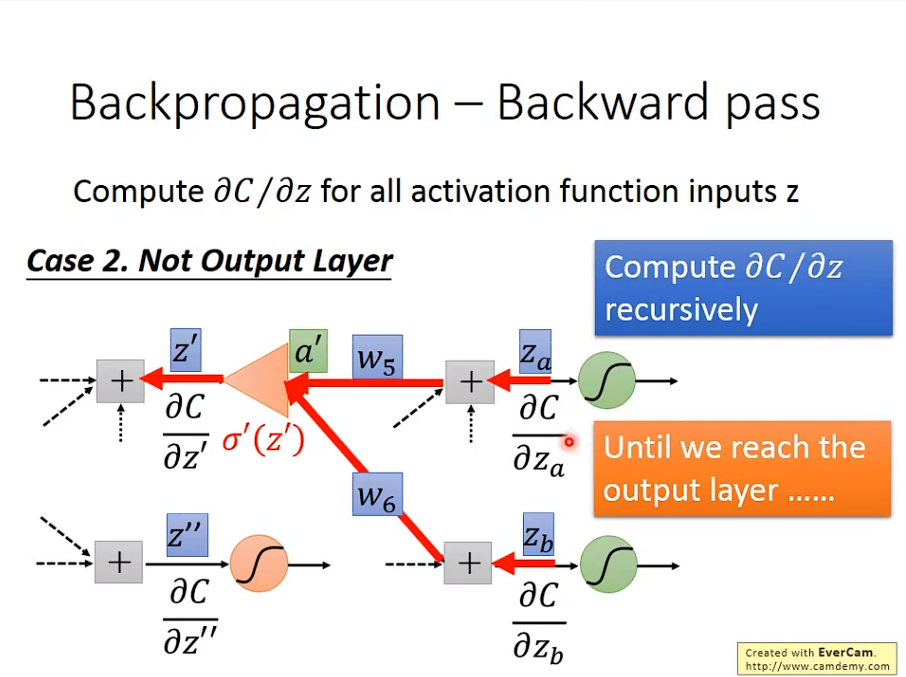
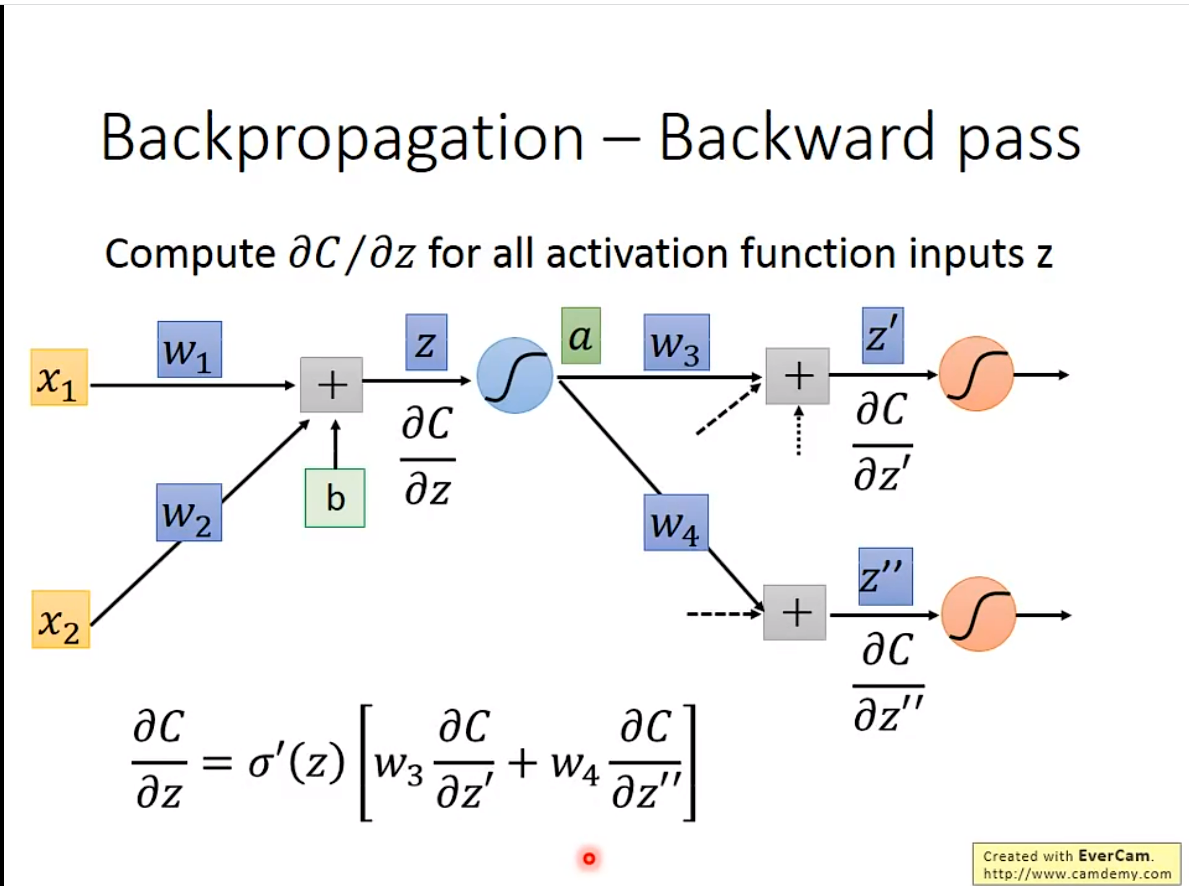
3. Backward pass