学校老师开了一门多媒体数据安全的课(一开始选的时候主要是为了能今早的凑够学分摆烂,上了后感觉还不错,老师教的真的不错,属于是为数不多的能教得好的老师了
这里记录一下学到的多媒体数据安全的内容
- 为什么要研究多媒体安全?
- 多媒体基本定义
- 为什么可以压缩?
- 一般的图像压缩流程
- 图像压缩方法-jpeg
- 视频压缩
- 视频压缩标准
- 定义安全需求
- 针对多媒体的攻击
- 多媒体的安全服务
- 多媒体安全服务的性能需求
多媒体是多种媒体的综合,一般包括文本、声音和图像等多种媒体形式。
最常见的多媒体,一般是图像和视频。
为什么要研究多媒体安全?
说白了是因为不信任。
举个例子,你是一个漂亮的妹子,你穿着sexy的比基尼去海边拍了个照,你把照片上传到了你的云盘里。
那么问题来了,管理云盘的人(或算法)说不定扫到了你的照片,觉得你的照片很好看,可以用来….(懂得都懂)
总而言之,就是你把你的数据(可能是隐私数据)上传到了第三方平台中,然而你不能保证第三方平台不对你的数据进行操作
用户不信任云基础设施和应用软件提供商
如何保护输出的敏感数据不被云端基础设施访问?
如何解决这个问题就是多媒体安全的核心要义了。
现在学术界也提出了一些可行的方案,比如
联邦学习-Federated learning
同态加密
然而这些方案现在都不是特别成熟。
多媒体基本定义
所谓知己知彼,百战不殆。研究某种事物的安全问题,首先你必须了解这个事物(你都不知道东西是啥,你怎么研究安全问题呢)
所以要研究多媒体数据的安全,首先要了解多媒体。
数字图像的基本表示单元-像素
我们在电脑、手机中看到的图像,都是由一个个像素组成的。(这个也很好理解,类比微积分中的积分就行了。
一般一个图像的像素点构成越多,一个像素占的字节更多,往往能表示图像更清晰
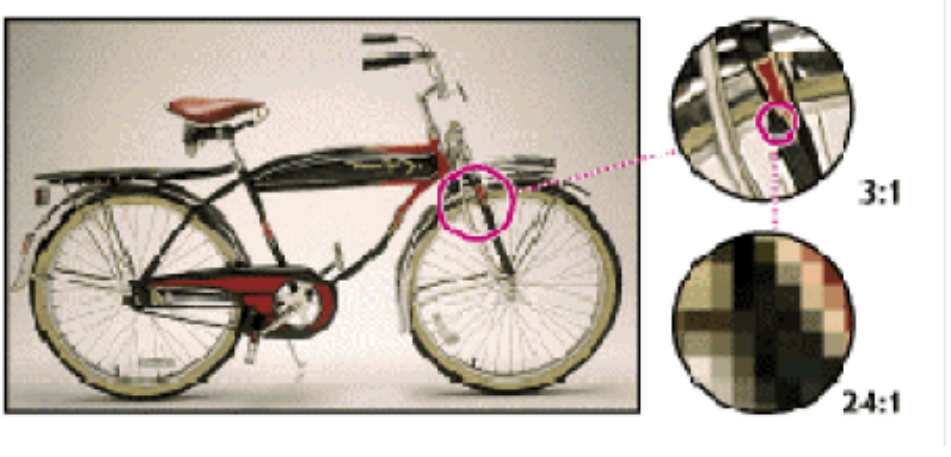
根据一个像素所占的bit数,我们将图像划分成二值图像、灰度图像、彩色图像
二值图像
一个像素点用1 bit表示
灰度图像
一个像素点用8 bits表示
彩色图像
一个像素点用 24 bits表示(比较特殊的是,它分成了3个位面,RGB,即三原色的图层)
视频
我们看到的视频,其实是由一幅幅图像构成了,这里利用人的大脑的一些机制,总的来说
只要 单位时间内 连续播放的图像数量够多, 对于我们来说 它看起来就像一个连续的画面一样(通常是一秒25-30个图像,即30帧)
压缩
讲到视频,视频有一个特别的特性,它往往是经过压缩的,这是为什么呢?
因为不压缩传送成本太大了。例子
你在某网站看一个30分钟的高清动漫
每个像素点24bits
一幅画面是720*480(即720*480个像素点)
帧率:一秒要放30帧
为了满足你能实时观看,不会卡顿的要求
网站和你的主机之间的传输速率= 720* 480 * 24 * 30约等于237mbps约等于30M/s
这成本也太大了,也没几个网站经得住这种带宽耗费。(众所周知,带宽是很贵的)
所以压缩对于视频来说是必然的
虽然但是,图片也是可以压缩的(看你想不想了)
为什么可以压缩?
图像和视频可以压缩,主要在于他们是存在冗余的
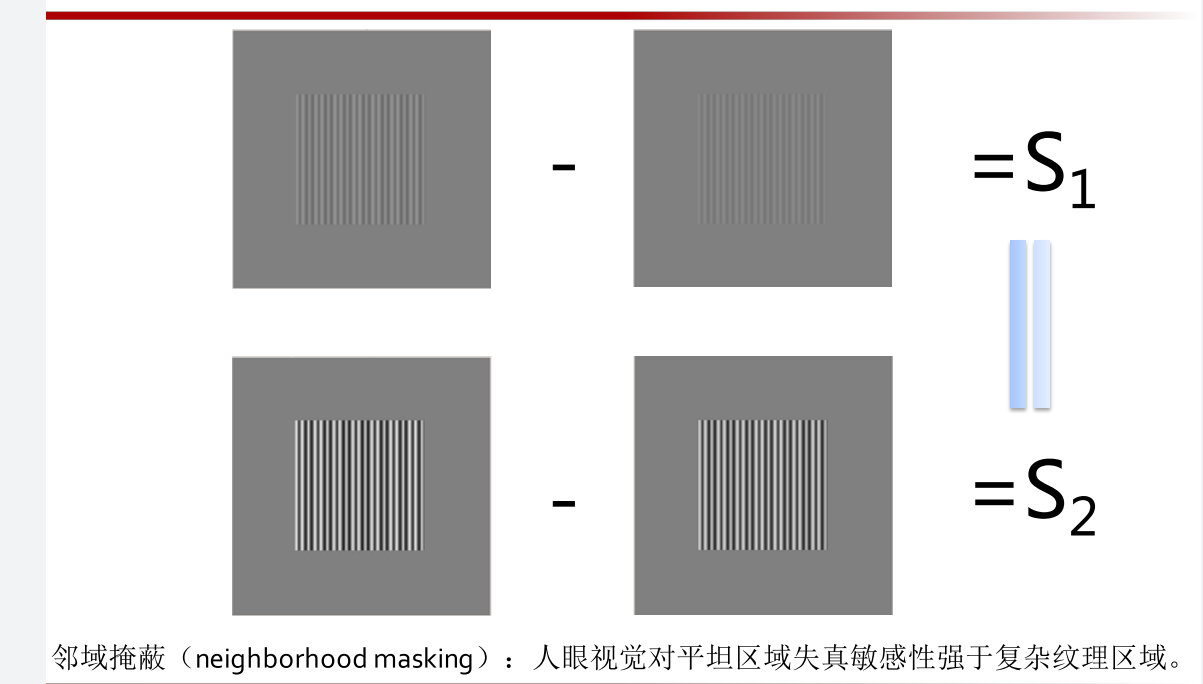
1.视觉冗余-掩蔽效应
掩蔽效应(Masking Effects):由于出现多个同一类别(如声音、图像)的 刺激,导致被试不能完整接受全部刺激的信息。
亮度隐蔽
这涉及到心理学中 亮度掩蔽 的概念
亮度隐蔽:
心理物理学中,将最小 可觉差随背景亮度变化 而变化的现象称为人眼 的亮度掩蔽特性。
背景越亮,能不被感知 到的亮度差异即视觉能 容忍的差异越大。
亮度隐蔽还有个公式

换句话说,越亮,越看不出变化
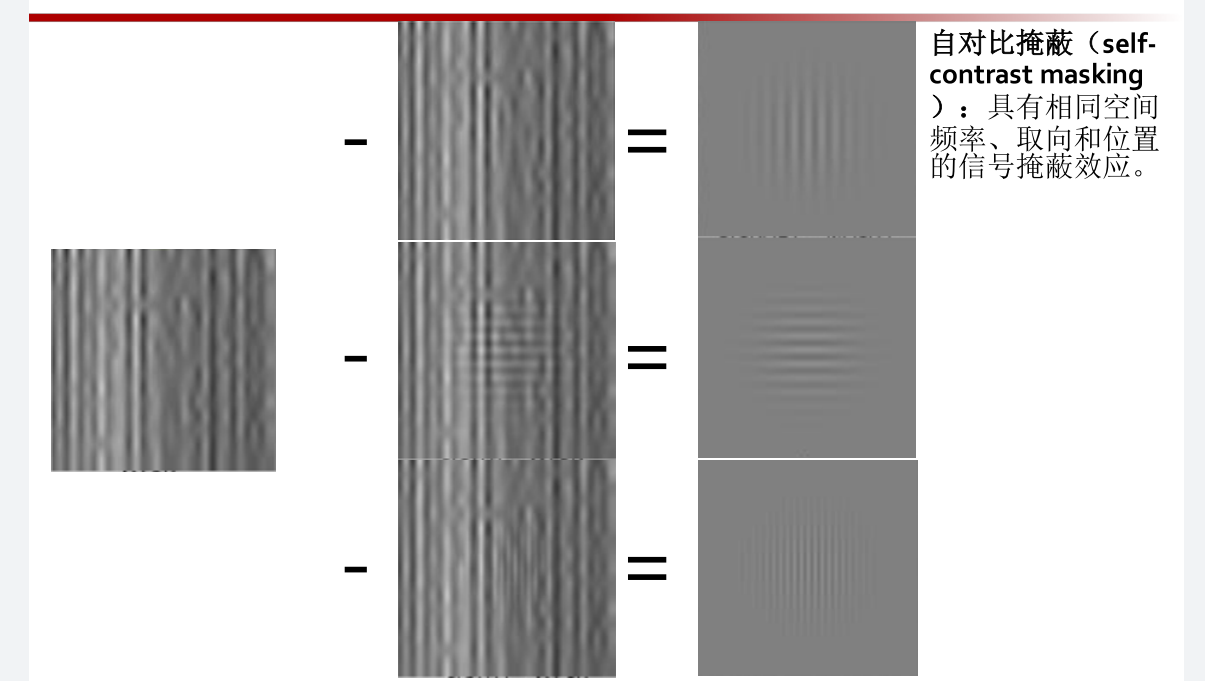
对比度掩蔽
对比度掩蔽(Contrast Masking):
反映在存在背景信号的前提下,人眼 视觉对一个信号的感知掩蔽特性
邻域隐蔽和自对比隐蔽都属于 对比度掩蔽
色度掩蔽
看图就能很清晰的知道为什么

时域隐蔽
这个不是很常用
2.听觉冗余

即我们可以其实可以舍弃2khz~5khz之外的其他声音来减少多媒体的大小
3.统计冗余
统计冗余 包括 空域冗余、时域冗余、编码冗余

一般的图像压缩流程
图像压缩主要是基于统计冗余的
图像压缩的一般流程如下:
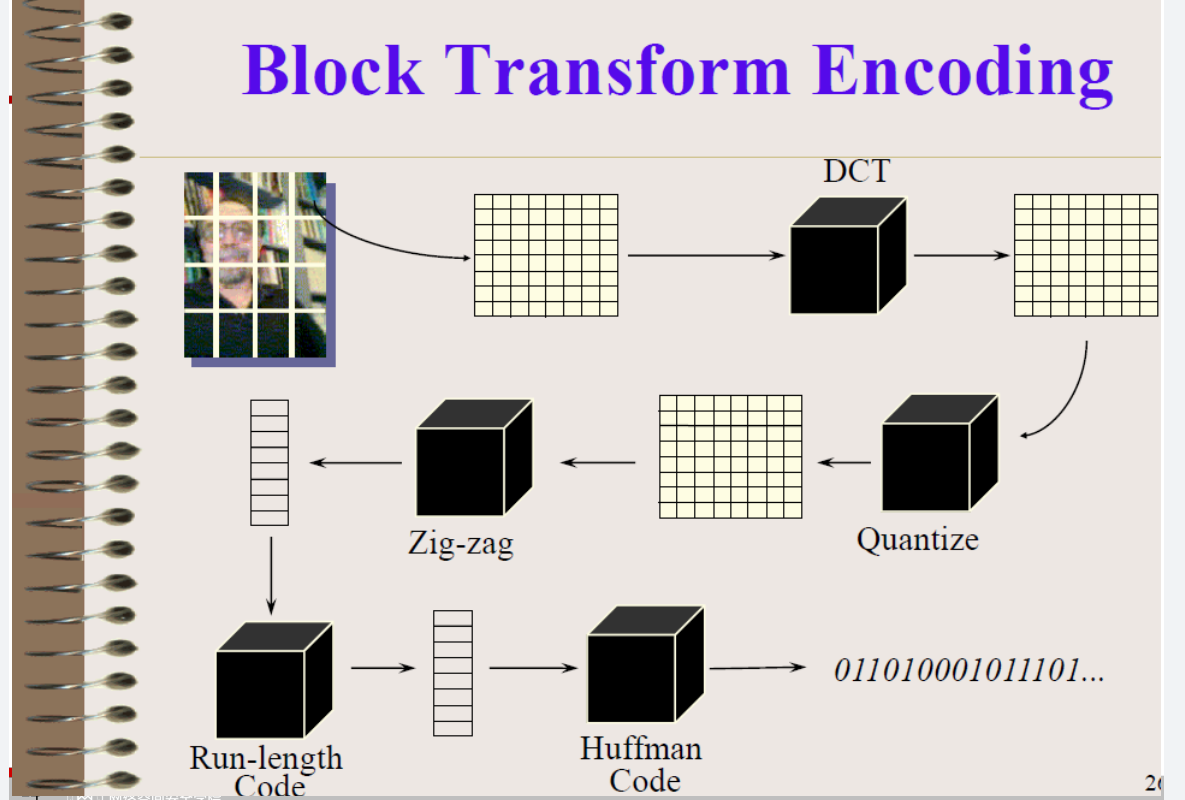
其中,一开始(也是最完整)的图片就是完全没有压缩的,纯的像素域的图
其中比较重要的是 DCT变换 和 量化(Quantize)
其中DCT变换可以更有效的去除冗余(相比离散傅里叶变换来说),但是复杂度更高
量化是不可逆的,会造成信息丢失,但它是多媒体压缩中的一个关键步骤,所以为了判断量化的效果如何,定义了量化误差:量化前后的差值
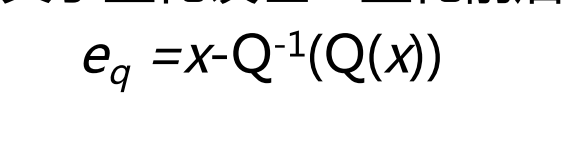
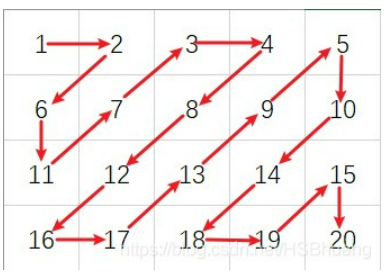
zigzag的走法是这样的
run-length coding是这样的
图像压缩方法-jpeg
jpeg虽然是一种我们见过的图片格式,其实它是一种图片压缩的办法
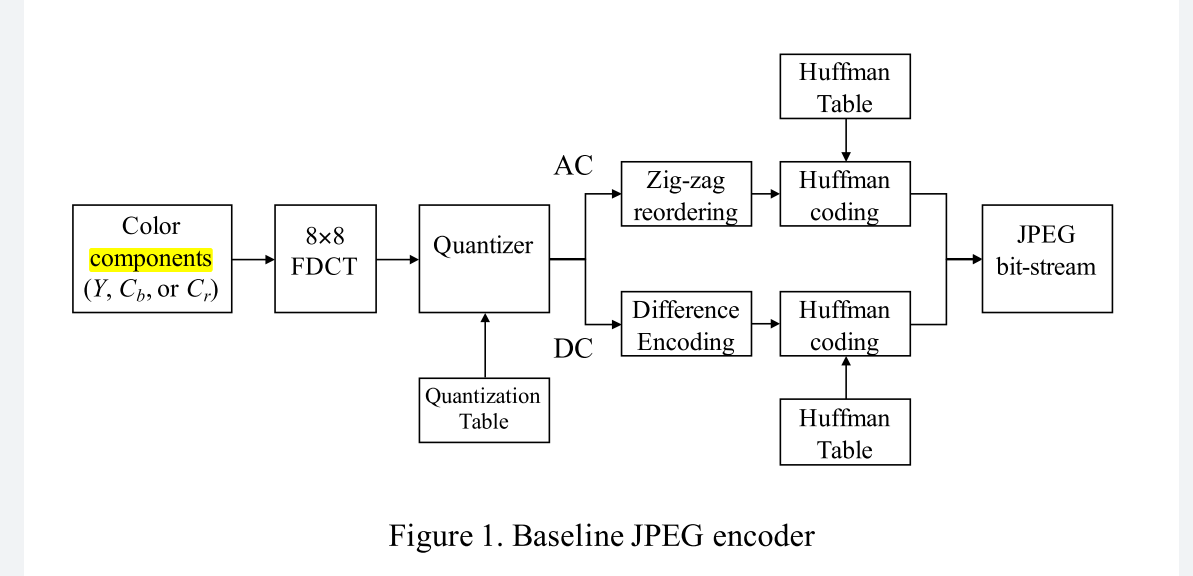
视频压缩
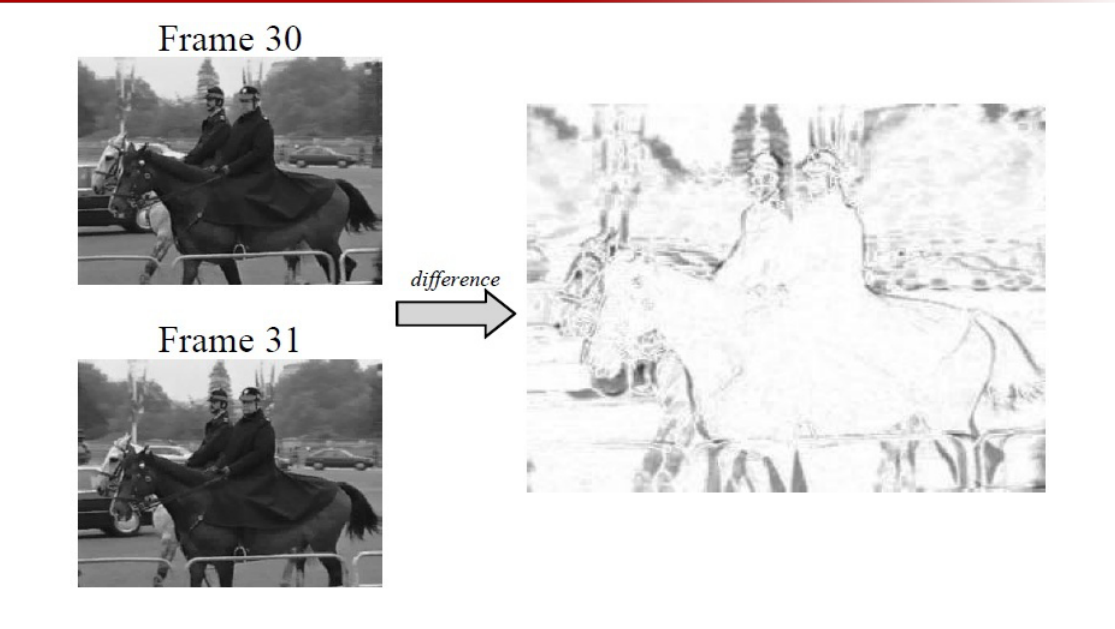
之前说过,视频是一幅幅图像在时间上构成的
但是 相邻的帧之间的差异其实是比较小的
如图所示
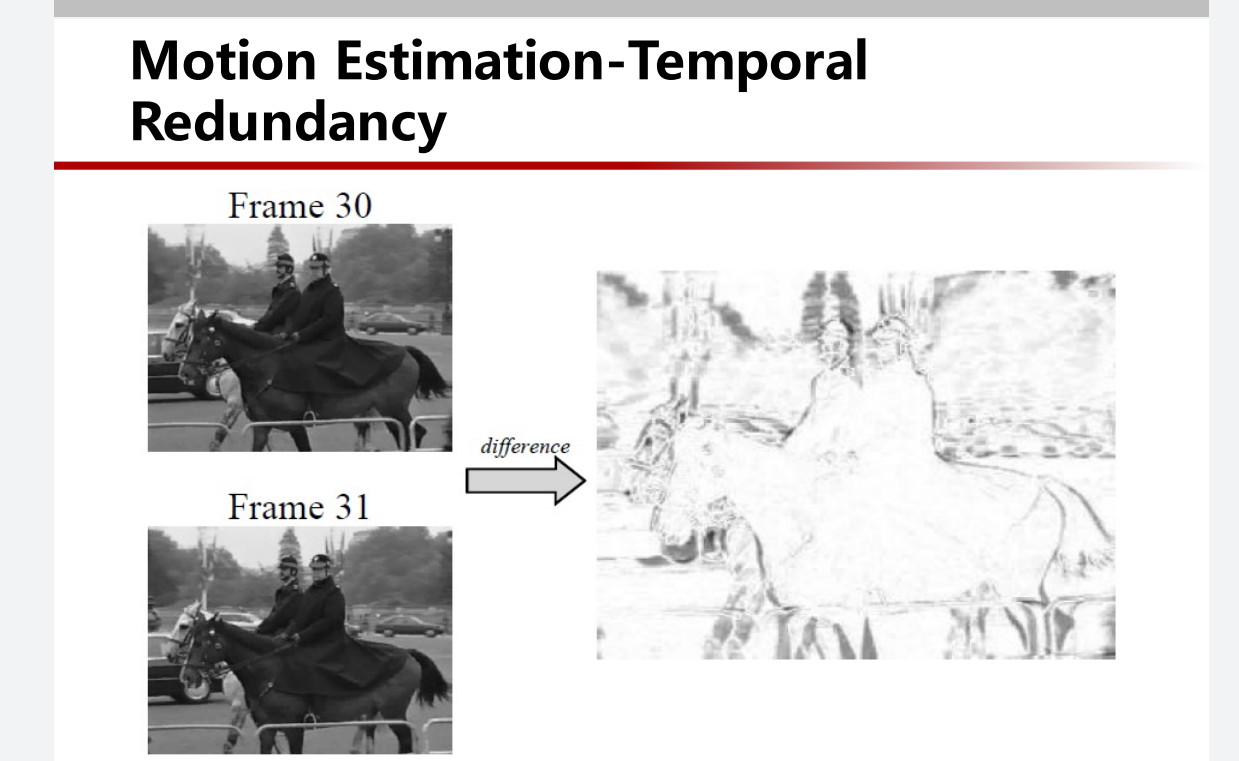
那么就有一种叫做 Motion Estimation(运动估计) Temporal Redundancy(时间冗余) 的方法。
Motion Estimation Temporal Redundancy
大白话一点,就是 Inter-frame Compression(帧间预测)
简单来说,就是我们知道第一幅图像,后面几幅图像和第一幅图像的差别应该是很小的,所以我们知道第一幅图像和 后面几幅图像和第一幅图像的差异 就能还原出原来的后面几幅图
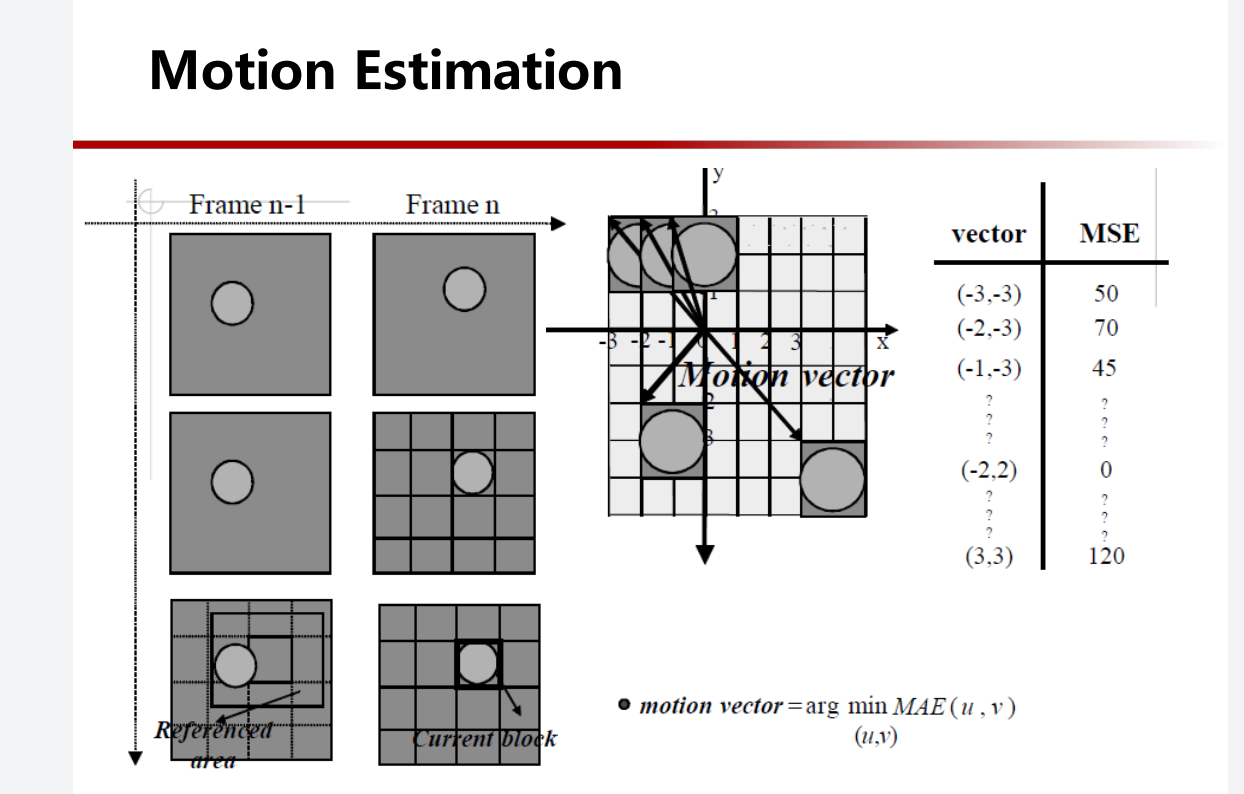
但是显然,不能只有一幅图和后面的所有差异,那样子变化太大了。一般情况下是这样子的
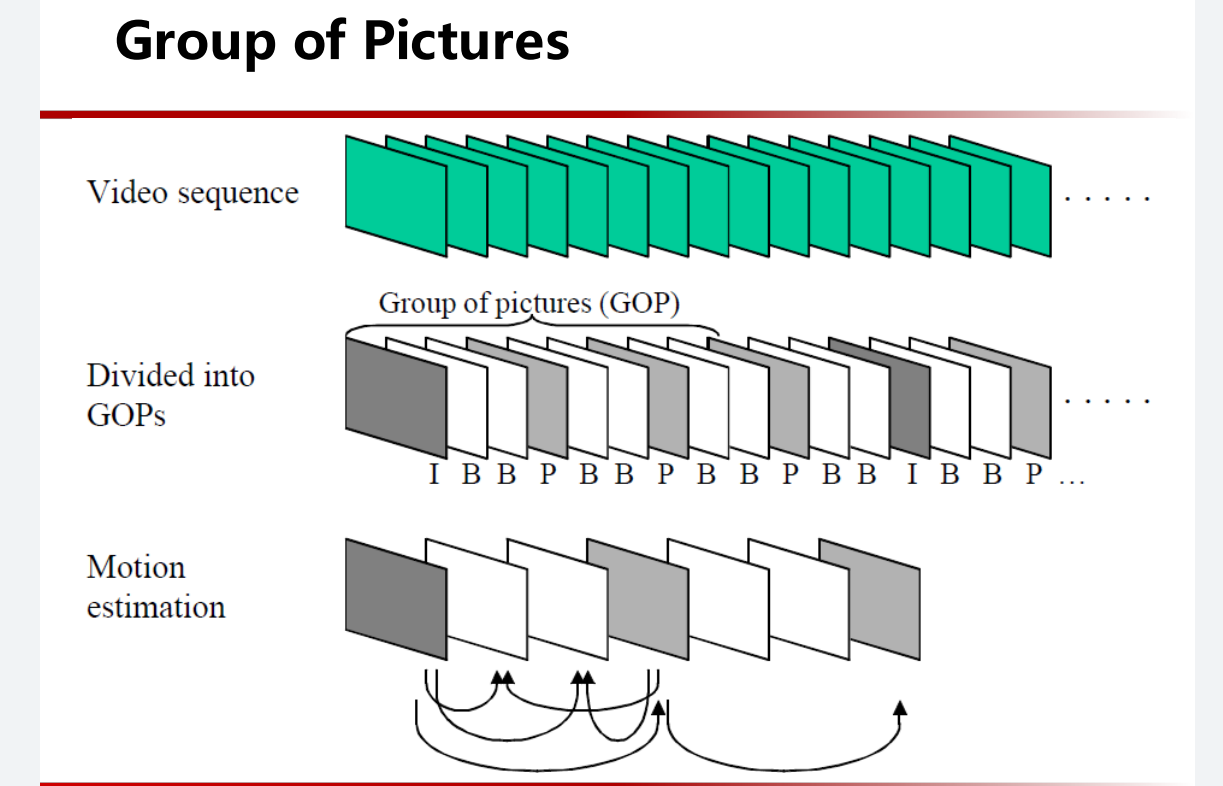
利用I帧和P帧来还原出B帧(帧间压缩,inter-frame compression)
因此经过这种方法发送视频。发送的顺序发生了改变

PSNR(Peak Signal to Noise Ratio)
也叫“峰值信噪比”
PSNR是衡量视频压缩的标准之一,一般情况下是越高越好
PSNR高于40dB说明图像质量极好(即非常接近原始图像);
在30—40dB通常表示图像质量是好的(即失真可以察觉但可以接受)
在20—30dB说明图像质量差;
低于20dB图像不可接受
视频压缩标准
1. H26x系列标准
主要用于实时视频通信,比如视频会议、可视电话等
2. MPEG系列标准
MPEG系列标准主要用于视频存储(DVD)、视频广播和视频流媒体(如基于 Internet、DSL的视频,无线视频等等)。
3. H.264
H.264是ITU—T的视频编码专家组(VCEG)和ISO/IEC的活动图像编码专家组 (MPEG)联合开发的一个最新的视频编码标准。它在数字电视、高清晰度电视 以及移动通信等方面都有比较好的应用
H.264 采取了帧内预测(intra-prediction)的方法,说白了不仅仅是相邻帧的像素差异不大,一个帧内的相邻像素块的差异大概率也不大。

原理不过多解释(我也不会,哈哈)
4. HEVC/H.265
同H.264一样,也是两大权威组织联合开发。
HEVC is the newest video coding standard introduced by ITU-T VCEG and ISO/IEC MEPG.
Compared with H.264/AVC, HEVC decreases the bitrate by 50% percent on average while maintaning the same visual quality
跟H.264比起来,想达到相同的视频质量只要一半的比特率(你看200M的动漫和100M的动漫的效果是一样的,这可是大提升)
定义安全需求
我们都希望我们的多媒体数据是安全的。
但是这个太宽泛了,说实话不利于我们进行研究,为此我们需要知道怎么样才是安全的,这就引出了安全需求的概念
安全需求可以由3个方面定义
1.安全攻击
安全攻击可以分为被动攻击和主动攻击
被动攻击
被动攻击不影响通信,采用窃听监听通信等手段来
• 获取通信内容
• 监控通讯流量
主动攻击
主动攻击会修改数据流来:
• 伪装身份
• 重放
• 篡改信息
• 拒绝服务攻击
• 还有路由攻击。
2.安全服务
安全服务就是提供给客户的“承诺”和“保障”。
• Authentication 认证-确认实体身份。实体包括 :用户、进程、系统、信息等
• Access Control 访问控制- 防止非授权访问 • Data Confidentiality数据机密性 –保护数据非 授权泄漏
• Data Integrity 数据完整性- 确保接收数据和发 送数据一致
• Non-Repudiation 不可抵赖性-要求无论发送方 还是接收方都不能抵赖所进行的传输
3.安全机制
安全机制定义为:被设计用于检测阻止安全攻击或者从安全攻 击中恢复的机制
我们想要的安全现在就有明确的定义了。
利用安全机制提供安全服务对抗安全攻击
针对多媒体的攻击


多媒体的安全服务


多媒体安全服务的性能需求
光有上面说的多媒体安全服务还是不够的,我们不仅希望它安全,我们还希望能够不用花太多钱就让它安全,而且不影响播放多媒体的性能。
为了在保护足够安全的前提下降低对性能的影响 和应用的成本,多媒体安全保护技术的设计需考 虑周全



看到这里真的不容易了,但是安全这部分的概念,大家看一下就好,其实看了解释都比较好理解。也不用特地去记